概述
第三个部分是实现一个分时多任务的系统,也就是能够在多个任务运行期间进行切换,让一个程序在等待IO时其他程序能执行而不是傻等。虽然和并行有点类似,但目前使用到的都只有一个CPU,任何时候都只有一个程序在执行。分时多任务有两种:一种是程序自己主动让出控制权,有点类似于编程语言中协程的概念;一种是由操作系统控制每个程序只能运行一个时间片,到时间了自动切换控制权,有点类似于Python中带了GIL锁的线程。由于第二种是在第一种的基础上建立的,所以这里主要展现的第二种。
内容
和上次相比:
-
把
hello_world.c修改成了hello_world0.c、hello_world1.c和hello_world2.c三个文件,以hello_world0.c为例:#include "user.h" int main() { char *s = "Program[0] print0 "; isize w; for (int i = 0; i < 10; i++) { s[16] = (i % 10) + '0'; write(FD_STDOUT, s); w = get_time() + 10; while (get_time() < w); // yield(); } return 0; }每个程序都会输出自己的编号,相隔两次循环会阻塞自己一段时间,
hello_world1.c阻塞的时间是20ms,hello_world2.c阻塞的时间是30ms。另外,因为程序比较少,所以没有像教程一样写一个用来编译的Python脚本,而是把链接脚本也分成三个,每个的起始地址不一样,makefile中分别用不同的链接脚本编译这三个文件。 -
把原来
batch.c的一部分代码放在loader.c里,负责加载用户程序和初始化;新添加了管理任务的task.c,管理计时的timer.c和控制任务切换的汇编程序switch.S。
注意点不是很多,首先是几个硬编码的部分,如SIE寄存器的初始化,第五位为1开启内核态时钟中断:
usize sie; asm volatile("csrr %0, sie":"=r"(sie));
sie |= (1 << 5); asm volatile("csrw sie, %0"::"r"(sie));
读取时间寄存器,有一个专门的指令rdtime:
usize get_time() {
usize timer; asm volatile("rdtime %0":"=r"(timer)); return timer;
}
scause寄存器的第63位(从0开始)为0表示当前异常是陷入,1表示当前异常是中断(用户态的系统调用属于陷入),后面的0-62位表示陷入或者中断的具体原因。对于中断,低位为5表示内核态时钟中断:
if (scause == (1L << 63) + 5) {
set_next_trigger();
suspend_current_and_run_next();
return cx;
}
接着,为了更好的理解切换的过程,还是需要研究一下这个过程中sp寄存器的变化。同样,在程序最开始的时候,sp指向bootstack里,注意在本次任务中,每个用户程序各自拥有一个属于自己的用户栈和内核栈,所以初始化的时候init_app_cx就是给每个程序的内核栈压上TrapContext和TaskContext。
然后进入run_first_task,进入__switch,第二句是sd sp 0(a0),这里有一点挺坑的,就是传给__switch的参数是一个“指针的指针”,就是说,TaskControlBlock里的task_cx_ptr属性存储的是指向TaskContext的指针,或者说是栈顶地址,而传入__switch的参数是指向这个属性的指针。
那么在上面这句汇编代码中,0(a0)解引用,就是把sp(或者说是前一个任务的栈顶地址)保存在这个属性里了,最后把0(a1)传给sp,就是跳转到另一个任务的栈里,对于第一次调用而言,就是在这里从bootstack跳到了第一个任务的内核栈,切换任务之后,sp指向了新任务的TrapContext,由于ra现在指向__restore,所以程序就会再走一遍__restore的流程,进入用户态。
另外,由于第一次调用__restore前sp就已经指向内核栈了,所以原来__restore的第一句mv sp, a0就应该去掉了。在上一部分还提到过一个内核栈重置的问题,当时是在运行完一个程序之后,要压入一个自定义的TrapContext,为了节省空间,就直接放到栈底了,而现在由于每个程序一个栈,在一个程序运行结束之后,这个栈就没有用了,同时task_cx_ptr和scratch又分别保存了当前程序的TaskContext和TrapContext地址,修改都是在对应位置,所以没有“重置栈”这一过程。
最后分析一下输出结果(设定每个程序运行的时间片是10ms,这里IO的时间和时间片相比基本可以忽略不计):
Program[0] print0
Program[1] print0
Program[2] print0
Program[0] print1
Program[0] print2
Program[1] print1
Program[2] print1
Program[0] print3
Program[0] print4
Program[1] print2
Program[2] print2
Program[0] print5
Program[1] print3
Program[2] print3
Program[0] print6
Program[1] print4
Program[2] print4
Program[0] print7
Program[1] print5
Program[2] print5
Program[0] print8
Program[1] print6
Program[2] print6
Program[0] print9
Application exited with code 0
Program[2] print7
Program[1] print7
Program[1] print8
Program[2] print8
Program[1] print9
Program[2] print9
Application exited with code 0
Application exited with code 0
根据输出,画出的前120ms的程序运行情况如图所示:
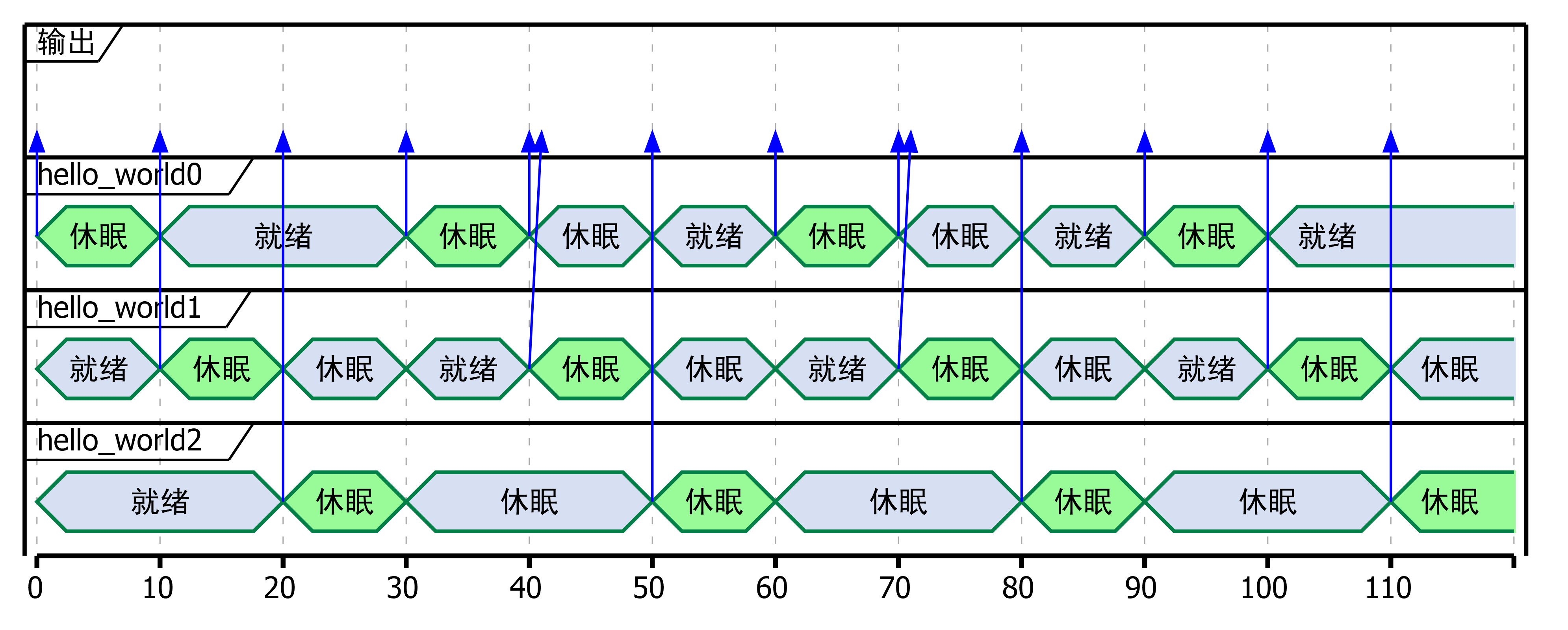
绿色表示当前占有CPU的程序,箭头表示输出。可以发现不管各个程序休眠多长时间,都是轮流使用CPU,到点即换人。不过值得注意的是在输出结果中出现了程序0连续输出两行的情况,对应上图第40ms和第70ms的地方。而在第100ms则没有出现这一情况。这种情况是否发生取决于程序0休眠10ms后被唤醒准备进入内核态调用输出函数和10ms的时间片到达发生时钟中断这两个事件谁先谁后。如果前者先,那么程序0进入内核态后时钟中断就不能发生了,必须等输出之后回到用户态才会发生中断,这样结合休眠前的输出,就会连着输出第二次;而如果后者先,那么在输出前控制权就被让出去了,必须等程序2和程序3都输出过后才能轮到程序0输出,这样就不会连着输出两次。再比如,如果程序0在输出之后,获取当前时间之前让出了控制权,程序1和程序2输出后,程序0才获取时间,休眠10ms然后控制权又被程序1和程序2抢走了,那么就会出现程序0一时半会输出不了的情况。所以说即使是全程只有一个程序在运行,在任务切换的时候仍然可能无法预测的竞争问题,这里也是各种程序Bug的重灾区。
还有一个地方,就是我的输出没有出现教程那样混乱的情况,因为我打印字符串是直接将整个字符串提交到内核态,而一旦进入内核态就不会再收到时钟中断了,所以字符串都是完整输出。