之前的文章整理一下重新发布
java io流有如下内容:
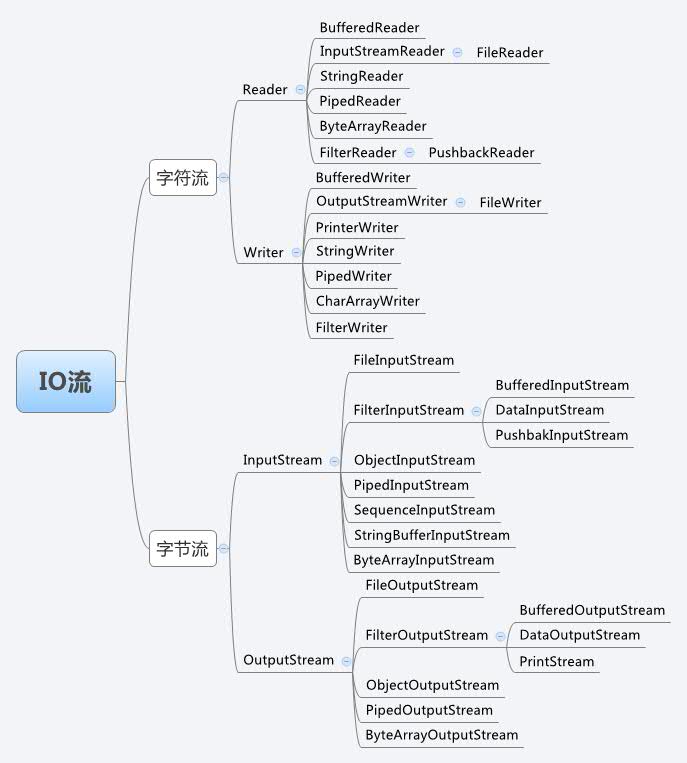
使用java-io流复制文件时,可以从以下步骤来进行判断使用何种流:
1.首先判断是源文件还是目的文件,若为源文件就使用inputstream和reader,否则就使用outputstream和writer;
2.如果是文本文件使用字节流,所以使用inputstream/outputstream体系,媒体文件就使用reader/writer体系;
3.接下来明确使用体系中的那个对象,reader中操作文件的对象是filereader,inputstream体系中操作文件的对象是fileinputstream;
4.是否提高效率:如需提高效率,使用缓存类buffered~,只要用到缓冲区,就要记得刷新,关闭缓冲区,就是在关闭缓冲区中的流对象。
① 完整的复制媒体文件的类如下:
1 import java.io.BufferedInputStream; 2 import java.io.FileInputStream; 3 import java.io.FileNotFoundException; 4 import java.io.FileOutputStream; 5 import java.io.IOException; 6 import java.io.InputStream; 7 import java.io.OutputStream; 8 9 public class CopyMdeia { 10 11 public static void main(String[] args) { 12 // TODO Auto-generated method stub 13 try { 14 InputStream is = new FileInputStream("e://txdx.mp3"); 15 BufferedInputStream bis = new BufferedInputStream(is); 16 OutputStream os = new FileOutputStream("d://txdx.mp3"); 17 byte[] buffer = new byte[1024]; 18 int count = 0; 19 try { 20 while((count=bis.read(buffer))!=-1) { 21 os.write(buffer, 0, count); 22 } 23 }catch(IOException e) { 24 // TODO Auto-generated catch block 25 e.printStackTrace(); 26 } 27 try { 28 os.flush(); 29 os.close(); 30 bis.close(); 31 } catch (IOException e) { 32 // TODO Auto-generated catch block 33 e.printStackTrace(); 34 } 35 } catch (FileNotFoundException e) { 36 // TODO Auto-generated catch block 37 e.printStackTrace(); 38 } 39 } 40 }
② 接下来编写自己的缓存类:
1 import java.io.FileInputStream; 2 import java.io.IOException; 3 4 public class MyIputStremBufferedFileMediaCopy { 5 6 private FileInputStream fis = null; 7 8 private byte[] by = new byte[1024]; 9 10 private int len = 0, p = 0; 11 12 MyIputStremBufferedFileMediaCopy(FileInputStream fis) { 13 this.fis = fis; 14 } 15 16 public int Read() throws IOException { 17 18 if (len == 0) { 19 len = fis.read(by); 20 if (len < 0) 21 return -1; 22 p = 0; 23 byte b = by[p]; 24 p++; 25 len--; 26 return b & 255; 27 } else if (len > 0) { 28 byte b = by[p]; 29 p++; 30 len--; 31 return b & 255; 32 } 33 return -1; 34 } 35 36 public void myClose() throws IOException { 37 fis.close(); 38 } 39 }
这里解释下为什么要&255:
* 因为read读取到的是二进制数据,二进制数据是由0和1组成的,有可能出现11111111
* 作为一个字节来讲11111111的十进制是-1,由于返回值是int类型,就会自动提升,int类型是32位,在前面补1,
* 就成了11111111-11111111-11111111-11111111,他的值还是-1,在写入的while循环哪里,判断到-1就会停止循环,
* 就导致了数据丢失,所以在这里&一个255,也就是二进制的00000000-00000000-00000000-11111111,
* 11111111-11111111-11111111-11111111
* 00000000-00000000-00000000-11111111
* ————————————————————————————————————& 值都为1结果才为1。
* 00000000-00000000-00000000-11111111
* 结果不变,
* 这样既保证了返回值不是-1,又没有改变二进制数据。
查看BufferedInputStream源码就可以看到:
1 public synchronized int read() throws IOException { 2 if (pos >= count) { 3 fill(); 4 if (pos >= count) 5 return -1; 6 } 7 return getBufIfOpen()[pos++] & 0xff; 8 }
这里也&255,具体的原因就是上面提到的问题。
参考文章:https://blog.csdn.net/qq_41890624/article/details/81625383