在计算机科学中,二叉树是每个结点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。二叉树是树的一种特殊情形,是一种更简单而且应用更加广泛的树。
B-树B*-树B+-树中的“-”是英文中的连词符号,没有实在的意义。所以B树就是B-树,B+树和B*树对应的就是他们自己,B树是由平衡二叉树演变而来的,是一颗自平衡的二叉搜索树。
二叉搜索树:
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树,左子树和右子树同时也是一颗二叉排序树;
二叉搜索树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字。
如果二叉搜索树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么此时这棵二叉树就是一个B树,此时的B树搜索性能逼近二分查找,二分查找就是查找一堆数据最多需要查找一半数量的次数就可以命中。
但二叉搜索树在多次增删改之后数据结构可能会变成线性表,此时的二叉搜索树的查找效率最差等于线性表查找即O(n)。
所以想拥有二叉搜索树的效率就要考虑平衡的问题,即平衡算法,二叉搜索树加上平衡算法就成为了B树即B-树,这里的平衡算法就是维持二叉搜索树二分查找的效率。
B树(B-树)是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的
子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
张这个样子:
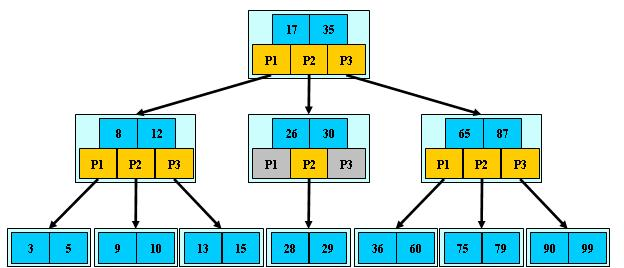
看样子和二叉搜索树没有偏离太远只是打破了一个节点存储一个元素的定义,但这样可以存储更多的数据,且查找不必深入叶子节点,接近二分查找的效率下在某一节点找到即返回,大大提高了查找效率,这是MongoDB采用B-树作为索引结构的原因。
B+树
1、非叶子节点的子树指针与关键字个数相同;
2、非叶子节点的子树指针p[i],指向关键字值属于[k[i],k[i+1]]的子树.(B树是开区间,也就是说B树不允许关键字重复,B+树允许重复);
3、为所有叶子节点增加一个链指针;
4、所有关键字都在叶子节点出现(稠密索引). (且链表中的关键字恰好是有序的);
5、非叶子节点相当于是叶子节点的索引(稀疏索引),叶子节点相当于是存储(关键字)数据的数据层;
6、更适合于文件系统;
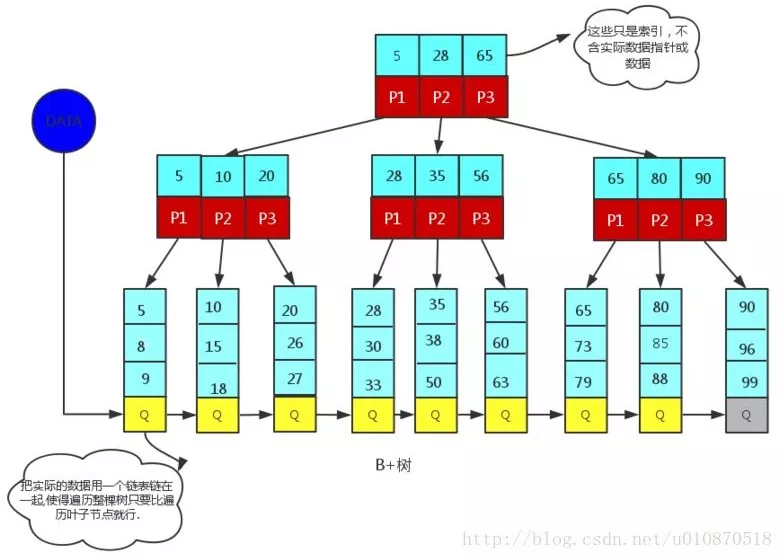
B+树是为文件查找而创造的,文件的目录一级一级索引,只有最底层的叶子节点(文件)保存数据)非叶子节点只保存索引,不保存实际的数据,数据都保存在叶子节点中,这不就是文件系统文件的查找吗?所以B+树是Mysql的索引数据结构,从上图中就可以看出大块的数据被分为小块的数据表结构,上面的节点只有数据指针,可以快速的查找到数据在那个小块上,然后去小块遍历就可以找到需要的数据位置。
为什么B+树更适合做数据库索引:
1、 B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
2、B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3、由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。
参考文章:https://blog.csdn.net/u013411246/article/details/81088914 ;https://www.cnblogs.com/tiancai/p/9024351.html