!!!做题之前建好一个文件夹以自己名字缩写命名
题目中出现xxx都是自己名字缩写
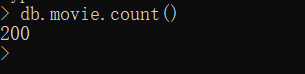
一、爬取百度首页源代码存入xxxbaidu.html文件中,然后把baidu.html文件在浏览器打开 (15 分)
需求分析
UA伪装

代码编写
进行爬取前包导入,UA伪装
# 引入模块requests
import requests
# 请求头UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
# 爬取的网页url
url = 'https://www.baidu.com/'
爬取网页源码并存入本地文件中
# 请求网址进行爬取
resp = requests.get(url=url, headers=headers)
# 文件写入
with open('xxxbaidu.html', 'w', encoding='utf8') as f:
f.write(resp.text)
效果展示


二、爬取拉勾网中关于python 爬虫的职位信息的JSON数据,爬取到1页即可 (25分)
需求分析
请求的url

查看需要爬取的请求头发现是post请求

请求体

代码编写
UA伪装和cookie模拟并写好请求体数据
import requests
pre_url = 'https://www.lagou.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36',
'referer': 'https://www.lagou.com/jobs/list_python%E7%88%AC%E8%99%AB?labelWords=&fromSearch=true&suginput=',
'cookie': 'RECOMMEND_TIP=true; user_trace_token=20200823150507-a39504af-6ef7-4e0f-89f7-9fe83c9460f0; LGUID=20200823150507-72fe7816-e0a2-4df5-a5e5-6dd5514e5ee4; _ga=GA1.2.840302598.1598166308; index_location_city=%E5%85%A8%E5%9B%BD; smidV2=2020111008480886bc6c6a421992c1c9d3e1c672b741c800541824619c509f0; JSESSIONID=ABAAABAABEIABCI12B48CD419CD5D4B7D3C853A73138F5B; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1606291292,1606373133,1606736150,1607243607; LGSID=20201206163325-0fd3e39a-f97a-463f-a4e1-68c9ec210896; PRE_UTM=m_cf_cpt_baidu_pcbt; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Fother.php%3Fsc.000000a%5FIDoM6WOygsin1bHQJSGZFeywzO4iVl7X0aQ86oi97CO94xvVpIVQ7sXGqCq1c-bFToJLOxmaeockf7BrA-Sr7oZVXOGjsCcnSyh8HwEgLFg6kF2CZF9wVHN3%5FmqgxIlWfuUgJeL4egN1yNuH8zJMBSHHivPLlH46vrsJt8eD%5F3E7rD6ycYDyz6eRsYU1Fr6ZMvN0tQu3ll8ZqrfAaJGk.7Y%5FNR2Ar5Od663rj6tJQrGvKD77h24SU5WudF6ksswGuh9J4qt7jHzk8sHfGmYt%5FrE-9kYryqM764TTPqKi%5FnYQZHuukL0.TLFWgv-b5HDkrfK1ThPGujYknHb0THY0IAYqs2v4%5FsKdTvNzgLw4TARqn0K9u7qYXgK-5Hn0IvqzujL0oUhY0ZFWIWYk0ZNzU7qGujYkPHczPj6dPH010Addgv-b5HD1rjT1P1DY0AdxpyfqnH0LrHmzPWm0UgwsU7qGujYknHR1P0KsI-qGujYs0A-bm1dcfbR0mLFW5Hm1njfz%26dt%3D1607243602%26wd%3D%25E6%258B%2589%25E9%2592%25A9%26tpl%3Dtpl%5F11534%5F23295%5F19442%26l%3D1522485503; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Flanding-page%2Fpc%2Fsearch.html%3Futm%5Fsource%3Dm%5Fcf%5Fcpt%5Fbaidu%5Fpcbt; WEBTJ-ID=20201206163342-176372f67fdad9-02388e6467b6c8-c791039-1327104-176372f67fe800; _gid=GA1.2.911330384.1607243623; sensorsdata2015session=%7B%7D; TG-TRACK-CODE=search_code; SEARCH_ID=4cb77d31446b445da28617dc330d995f; X_HTTP_TOKEN=a64c53dd88843d2479744270615229782ef78845ee; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22176039d604c895-050e4b48534006-c791e37-1327104-176039d604db77%22%2C%22%24device_id%22%3A%221741a22c220420-01e073b4664e7-3323766-1327104-1741a22c221aef%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_utm_source%22%3A%22lagouedu%22%2C%22%24latest_utm_medium%22%3A%22pcbanenr%22%2C%22%24latest_utm_campaign%22%3A%22%E6%9C%AA%E7%9F%A5%E6%B4%BB%E5%8A%A8%22%2C%22%24latest_utm_term%22%3A%22%E5%8F%8C%E5%8D%81%E4%B8%80%E9%A2%84%E7%83%ADH5%22%2C%22%24os%22%3A%22Windows%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%2287.0.4280.88%22%7D%2C%22first_id%22%3A%22%22%7D; _gat=1; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1607244799; LGRID=20201206165318-0f6519ee-29a5-4c6a-a6df-ced5e442e017'
}
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
data = {
'first': 'true',
'pn': 1,
'kd': 'python爬虫'
}
进行请求并把数据打印在控制台
resp = requests.post(url=url, data=data, headers=headers)
print(resp.text)
效果展示

三、根据第二题得到的数据进行数据清洗,并把数据以json的格式存入xxx.json文件中
存入的数据要用美化的方式!
需求分析
分析得到数据发现是json格式并得知职位信息在下图所示位置

代码编写
把json字符串转化为字典格式得到关于职位信息的位置
json_str = resp.text
import json
dic = json.loads(json_str)
info = dic['content']['positionResult']['result']
把数据以json格式写入文件中
with open('xxx.json', 'w', encoding='utf8') as f:
json.dump(info, f, ensure_ascii=False, indent=4)
效果展示

四、爬取豆瓣热门电影前200条数据,再根据数据中的url进行详情页爬取,爬取完成后存入mongodb中 (35分)
注意前面爬取到的url等数据对应每一页的详情数据是一个列表!!!mongodb数据库名字以自己名字缩写
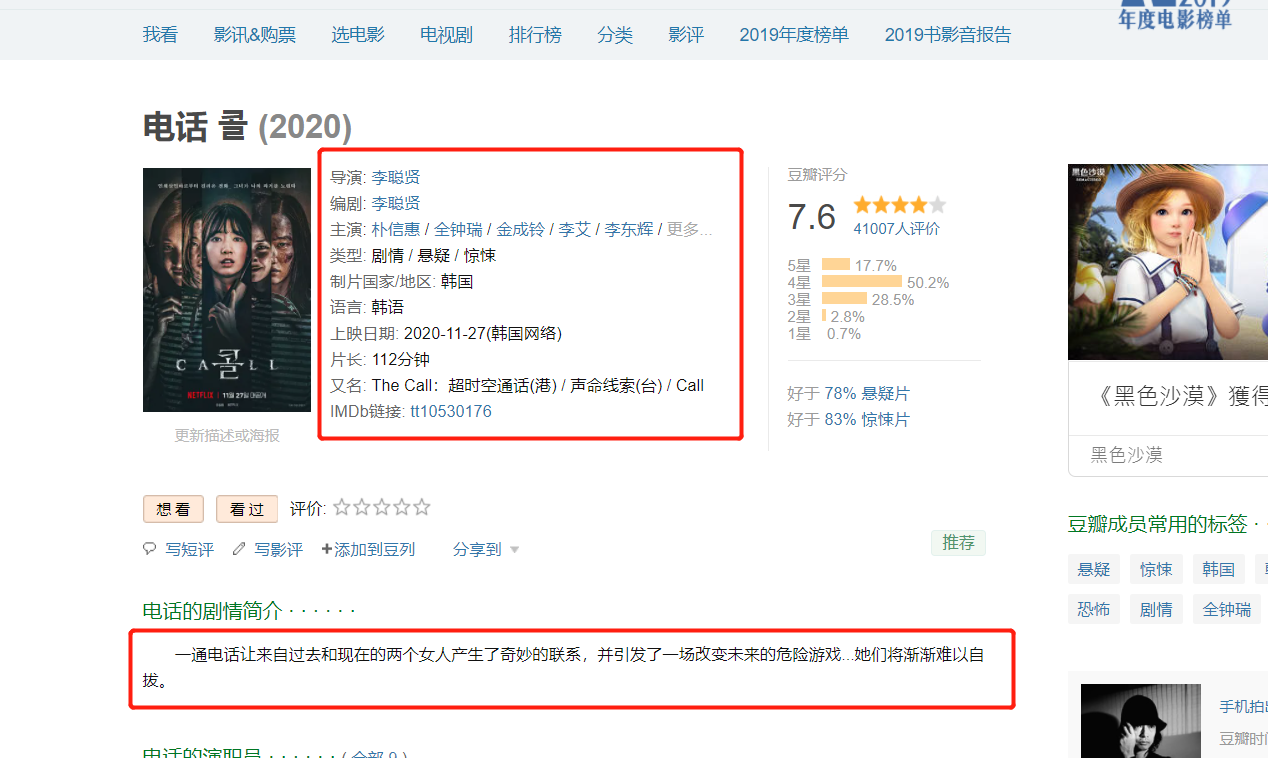
需求分析
发现请求的时候有cookie

分析请求参数

代码编写
进行UA伪装,cookie模拟,以及包的导入
import requests
import pymongo
clint = pymongo.MongoClient()
movie = clint['xxx']['movie']
from lxml import etree
import re
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Cookie': 'bid=QEz4ON7HzEE; douban-fav-remind=1; ll="108288"; __yadk_uid=coQZcizz0GQ4Eruic97BQUOpSwzvAQIs; _vwo_uuid_v2=DDD2509BC44616C15A4B916BFE5F7BFC4|419d4f4e08eadef0ec13fd37db4fea89; push_noty_num=0; push_doumail_num=0; __utmz=30149280.1605231795.5.5.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmv=30149280.22650; dbcl2="226501939:r5LYYk+nDHo"; ck=fnLy; ap_v=0,6.0; __utma=30149280.914318564.1601114885.1605231795.1607132983.6; __utmc=30149280; __utmt=1; __utmb=30149280.2.10.1607132983; __utma=223695111.2012091785.1604974322.1604974322.1607132988.2; __utmb=223695111.0.10.1607132988; __utmc=223695111; __utmz=223695111.1607132988.2.2.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1607132993%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D; _pk_ses.100001.4cf6=*; _pk_id.100001.4cf6=0a560b7600fa2f47.1604974324.2.1607133048.1604975564.; __gads=ID=c6ebe6bd924b0569-2270147706c500c0:T=1607133047:RT=1607133047:R:S=ALNI_Mbz6H5JOV6biELnY9KFK8enMxcSEQ'
}
进行请求参数编写,并发起请求,得到数据
params = {
'type': 'movie',
'tag': '热门',
'sort': 'recommend',
'page_limit': '200',
'page_start': '1'
}
resp = requests.get(url='https://movie.douban.com/j/search_subjects', params=params, headers=headers)
dic = resp.json()
找到单个url并对url进行请求,进行数据清洗并把数据存入mongodb中
for dic_old in dic['subjects']:
resp = requests.get(url=dic_old['url'], headers=headers)
html = etree.HTML(resp.text)
li = html.xpath('//div[@id="info"]//text()')
desc = html.xpath('//*[@id="link-report"]/span//text()')
li_new = [re.sub("s|/|:","",i) for i in li]
new_infos_list = list(filter(None, li_new))
# print(li_new)
lenth = len(new_infos_list)
for i in desc:
text = i.replace('
', '').replace('u3000', '')
dic_old['desc'] = text.strip()
for index, info in enumerate(new_infos_list):
if info.startswith('导演'):
for i in range(index + 1, lenth):
items = new_infos_list[i]
if items.startswith('编剧'):
break
dic_old['director'] = items
elif info.startswith('编剧'):
li = []
for i in range(index + 1, lenth):
items = new_infos_list[i]
if items.startswith('主演'):
break
li.append(items)
dic_old['scriptwriter'] = li
elif info.startswith('主演'):
li = []
for i in range(index + 1, lenth):
items = new_infos_list[i]
if items.startswith('类型'):
break
li.append(items)
dic_old['active'] = li
elif info.startswith('类型'):
li = []
for i in range(index + 1, lenth):
items = new_infos_list[i]
if items.startswith('制片国家地区'):
break
li.append(items)
dic_old['type'] = li
elif info.startswith('制片国家地区'):
for i in range(index + 1, lenth):
items = new_infos_list[i]
if items.startswith('语言'):
break
dic_old['country'] = items
elif info.startswith('语言'):
for i in range(index + 1, lenth):
items = new_infos_list[i]
if items.startswith('上映日期'):
break
dic_old['language'] = items
elif info.startswith('上映日期'):
for i in range(index + 1, lenth):
items = new_infos_list[i]
if items.startswith('片长'):
break
dic_old['date'] = items
elif info.startswith('片长'):
for i in range(index + 1, lenth):
items = new_infos_list[i]
if items.startswith('又名'):
break
dic_old['date'] = items
print(dic_old)
movie.insert(dic_old)
效果展示