索引
索引是为了提高数据查询的效率,就类似与书的目录。
索引的常见模型
哈希表,也就是KV类型的结构,输入K即可得到相应的值,思路就是把值放到数组里,用一个哈希函数把K换成一个位置,然后在这个位置上找寻value。当不同的K经过换算有相同的结果是,采用拉链法。如下图:

在这个图中,倘若K换算后的值得到的N,那么目标就是N位置后面的链表的某一个。采用顺序查找。用哈希表查询等值很快,但是缺点是不能进行范围查询。
有序数组,相比于哈希表,有序数组的好处就是可以进行范围查询,同时,用二分的话,等值查询的性能也可以很好的保证。但是,有序数组的缺点就是只适合静态存储引擎。
二叉搜索树,根据二叉树的特点(左孩子小于父节点,右孩子大于父节点),可以很容易来搜索树中的某个值,但是二叉搜索树在一些情况下会出现左右高度不平衡,所以需要保持一颗二叉平衡树,这样查询的复杂度是O(logN),更新一个结点也是O(logN)。
但是实际上二叉树是很少使用的,原因无他,结点数量过多的情况下,二叉树的高度也增加,访问磁盘的次数也会增加,从而查询变慢,所以引入了N叉树,N的值取决于数据块点大小。
InnoDB的索引模型
InnoDB中,表都是根据主键顺序以索引的形式来存放的,使用B+树来存储。
每一个索引都对应有一个B+树,比如建立一个表并设置一个索引,
CREATE table t6(
id int PRIMARY KEY,
k int not null,
name varchar(20),
INDEX (k)
)ENGINE=INNODB;
在这个例子中有两个索引,一个是主键索引,一个是K,每个索引都有一颗B+树。
现在向表中插入(ID,K)的值:(100,1),(200,2),(300,3),(500,5),(600,6)
则此时两颗树的结构如下图:
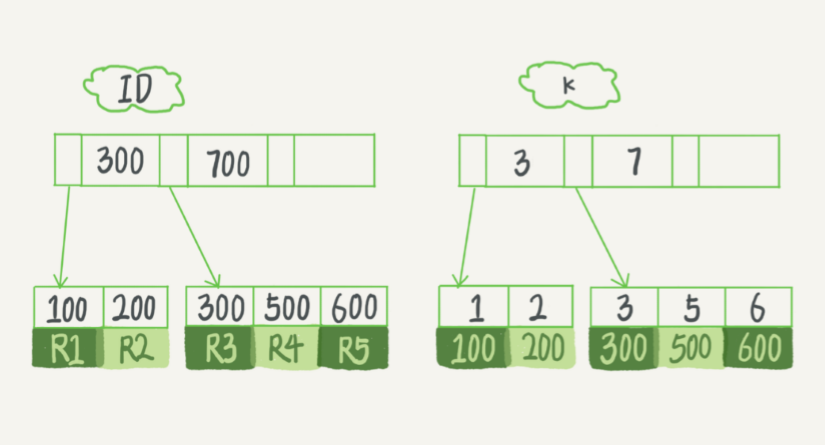
该图中,主键索引的叶子结点保存整行数据,非主键索引即K,叶子结点存储主键的值。
那么此处有两个查询方式,一种是根据主键索引查,一种是根据非主键索引,两者的区别在于:
如果是主键查询,则只需搜索ID的B+树,而如果是非主键查询,则需要先根据K查询到主键,再回表到ID的索引树,再查询信息。所以在项目中应该尽量使用主键查询来减少回表次数。
那么怎么可以经过索引优化来避免回表呢?
覆盖索引
假设现在执行:
SELECT ID FROM t6 where k BETWEEN 3 and 5;
这时候只需要查询ID,因为ID的值已经在K索引的树上了,所以可以直接提供结果而不需要回表,在这个查询里,索引K覆盖了查询请求,故也称之为覆盖索引。
最左前缀原则
简单来说,就是在联合索引中,就是从左边的字段开始匹配。如采用(name,age)建立联合索引,那么就会有下图:

这里只要满足最左前缀原则,在这里可以查name,也可以name和age一起查,这个时候MySQL都会采用这个索引来查找。
最左前缀原则如何安排字段的顺序:第一原则就是通过这样的调整,可以少维护一个索引,那么这个字段顺序是优先考虑使用的,第二个原则是空间,能节省空间的也是优先考虑的。
索引下推
当已经建有这样的联合索引但是查询却不是不符合最左前缀时,MySQL就会进行下推优化,对索引中包含的字段先进行判断,过滤掉不满足的条件,减少回表的次数,这显然比扫描全表要好。