5)linux中查看线程状态命令---ps命令(常和grep字符串匹配命令使用)
2)无参构造函数中如果有修改类成员会不会对当前正在构造的类产生影响,这种调用方式有什么优势或者缺点?
10、C++11中的= delete 和 = default 或者是智能指针unique_ptr不允许指针间相互赋值的原因?
1、C++中的char*、const char* 和string之间的相互转换
一、牛客网面经总结
1、虚函数表是什么时候创建的(预处理、编译、汇编、链接)?由谁创建的?
首先虚函数表是在编译时期由编译器创建的,原因如下(排除法):
I 预处理:只是进行宏定义的替换规则;
II 汇编:将编译器生成的汇编代码转变成机器可以执行的指令;
III 链接:汇编器生成的目标文件(和库)链接成一个可执行文件。
所以上面都可以排除,而编译步骤做的事情比较多,包括词法分析、语法分析、语义分析及优化代码等,是整个程序构建的核心。
总之,虚拟函数表是在编译期就建立了,各个虚拟函数这时被组织成了一个虚拟函数的入口地址的数组。而对象的隐藏成员--虚拟函数表指针是在运行期--也就是构造函数被调用时进行初始化的,这是实现多态的关键。
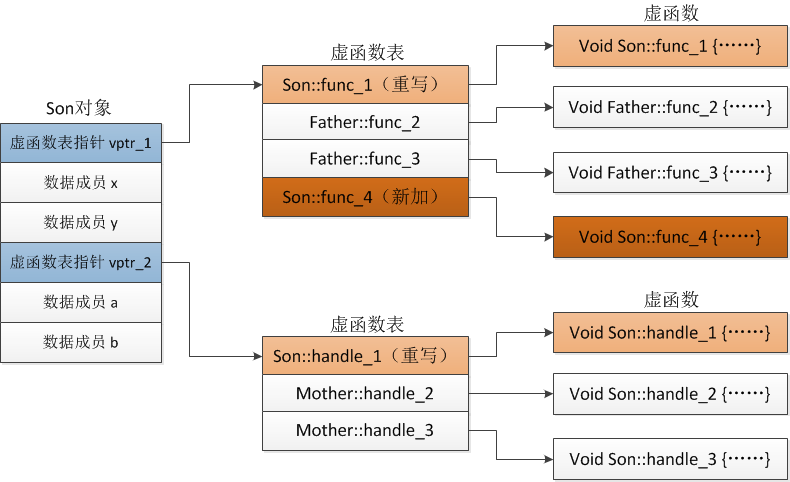
2、单继承和多继承虚函数表的结构
单继承:派生类只继承了一个基类,那么此时派生类只有一个虚函数表;编译器会将基类的虚函数表复制到派生类中,假如基类和派生类中有同名的虚函数,那么就会在复制给派生类的虚函数表中将重名的虚函数替换为派生类的虚函数;加入基类中有的虚函数,但是派生类中没有,那么会保留基类的虚函数;同理派生类中有的虚函数,但是基类中没有的虚函数,也会添加到派生类的虚函数表中。
多继承:即一个派生类继承了多个基类。此时该派生类继承了多少个基类就会有多少个虚函数表,每个虚函数表中的内容和单继承是一样的。
举例:


1 #include <iostream> 2 using namespace std; 3 4 class Father 5 { 6 public: 7 virtual void func_1() { cout << "Father::func_1" << endl; } 8 virtual void func_2() { cout << "Father::func_2" << endl; } 9 virtual void func_3() { cout << "Father::func_3" << endl; } 10 public: 11 int x = 666; 12 int y = 999; 13 }; 14 15 class Mother 16 { 17 public: 18 virtual void handle_1() { cout << "Mother::handle_1" << endl; } 19 virtual void handle_2() { cout << "Mother::handle_2" << endl; } 20 virtual void handle_3() { cout << "Mother::handle_3" << endl; } 21 public: 22 int a = 555; 23 int b = 888; 24 }; 25 26 class Son : public Father, public Mother //继承了两个父类 27 { 28 public: 29 void func_1() { cout << "Son::func_1" << endl; } //重写了 Father 虚函数 30 virtual void func_4() { cout << "Son::func_4" << endl; } //子类对象新写的虚函数 func_4 31 void handle_1() { cout << "Son::handle_1" << endl; } //重写了 Mother 虚函数 32 }; 33 34 typedef void(*func_t)(void); 35 36 int main(void) 37 { 38 Son son; 39 int* vptr_s_1 = (int*)*(int*)&son; //son的第一个虚表指针 40 41 for (int i = 0; i < 4; i++) 42 { 43 cout << "调用第" << i + 1 << "个虚函数:"; 44 ((func_t) * (vptr_s_1 + i))(); 45 } 46 47 for (int i = 0; i < 2; i++) 48 { 49 cout << "继承自 Father 数据成员:" << *(int*)((int)&son + 4 + i * 4) << endl; 50 } 51 52 int* vptr_s_2 = (int*)*((int*)&son + 3); //son的第二个虚表指针 53 for (int i = 0; i < 3; i++) 54 { 55 cout << "调用第" << i + 1 << "个虚函数:"; 56 ((func_t) * (vptr_s_2 + i))(); 57 } 58 59 for (int i = 0; i < 2; i++) 60 { 61 cout << "继承自 Mather 数据成员:" << *(int*)((int)&son + 16 + i * 4) << endl; 62 } 63 }
Son类继承自 Father 和 Mather 类,并且改写了 Father::func_1 与 Mather::handle_1,这两个虚函数将会存放到两个虚函数表中,Son 新加的 func_4 将会在第一个虚函数表中:
3、Linux下常用命令
1)文件查找命令(find)
1 /*根据文件名字搜索*/ 2 find /etc -name init (在/etc目录下精准搜索,区分大小写,即只有名为为init的文件才可以被搜索到) 3 find /etc -iname init (在/etc目录下精准搜索,不区分大小写,即Init、iNiT都可以被搜索到) 4 find /etc -name *init (在/etc目录下模糊搜索,以 init 结尾的文件或目录名) 5 find /etc -name init??? (在/etc目录下模糊搜索,? 表示单个字符,即搜索到 init___) 6 7 /*根据文件大小搜索*/ 8 eg:在/etc目录下查找大于100M 的文件可以使用如下命令: 9 find /etc -size +204800 #204800为数据块 10 这里 +204800 表示大于204800,-204800 表示小于204800 11 1 数据块 = 512 字节 = 0.5KB,也就是1KB等于2数据块 12 100MB = 102400KB = 204800数据块 13 14 /*根据所有者和所属组搜索*/ 15 在home目录下查询所属组为 root 的文件 16 find /home -group root 17 在home目录下查询所有者为 root 的文件 18 find /home -user root 19 20 /*根据 时间属性 搜索*/ 21 find 【路径】【选项】【时间】 22 选项有下面三种:-amin 访问时间 23 -cmin 文件属性被更改 24 -mmin 文件内容被修改 25 时间:+n,-n,n分别表示超过n分钟,n分钟以内和n分钟 26 eg:在 /etc 目录下查找5 分钟内被修改过属性的文件和目录 27 find /etc -cmin -5
2)在文件中匹配字符串并输出(grep)
功能描述:在文件中搜寻字符串匹配的行并输出
语法:grep -iv 【指定字符串】【文件】
-i 不区分大小写
-v 排除指定字符串
eg:查找 /root/install.log 文件中包含 mysql 字符串的行,并输出
grep mysql /root/install.log
3)查看文件(more、less、cat、head、tail)
1、more
分页显示一个文件或任何输出结果,使用方法
more 文件
2、less
less 与 more 类似,但使用 less 可以随意浏览文件,而 more 仅能向前移动
3、cat
一次显示整个文件内容
cat 参数 文件

4、head(默认显示前十行)
head -n 20 file.txt # 显示file.txt文件的前20行
head -n -20 file.txt #除了file.txt文件的最后20行,都显示
5、tail
tail -n 20 file.txt # 显示file.txt文件的最后20行
4)Linux中查看内存使用情况的命令---top命令
方式一:直接使用top命令

或者sudo apt-get install htop进行安装htop工具,使用htop查看内存使用情况

方式二:查看某个进程占用的内存
首先可以通过ps命令找到进程id,比如 ps -ef | grep kafka 可以看到kafka这个程序的进程id
然后使用 top -p 2319 查看进程id为2913进程的内存使用情况
5)linux中查看线程状态命令---ps命令(常和grep字符串匹配命令使用)
ps -aux | grep 执行进程的程序名称
把所有进程显示出来,并输出到ps001.txt文件
命令:
ps -aux > ps001.txt
1 USER:该 process 属于那个使用者账号的 2 3 PID :该 process 的号码 4 5 %CPU:该 process 使用掉的 CPU 资源百分比 6 7 %MEM:该 process 所占用的物理内存百分比 8 9 VSZ :该 process 使用掉的虚拟内存量 (Kbytes) 10 11 RSS :该 process 占用的固定的内存量 (Kbytes) 12 13 TTY :该 process 是在那个终端机上面运作,若与终端机无关,则显示 ?,另外, tty1-tty6 是本机上面的登入者程序,若为 pts/0 等等的,则表示为由网络连接进主机的程序。 14 15 STAT:该程序目前的状态,主要的状态有 16 17 R :该程序目前正在运作,或者是可被运作 18 19 S :该程序目前正在睡眠当中 (可说是 idle 状态),但可被某些讯号 (signal) 唤醒。 20 21 T :该程序目前正在侦测或者是停止了 22 23 Z :该程序应该已经终止,但是其父程序却无法正常的终止他,造成 zombie (疆尸) 程序的状态 24 25 START:该 process 被触发启动的时间 26 27 TIME :该 process 实际使用 CPU 运作的时间 28 29 COMMAND:该程序的实际指令
4、构造函数或析构函数能否调用虚函数?
语法上没有问题,但是没有效果。举例如下:
1 class A { 2 public: 3 A() { 4 std::cout << "create A" << std::endl; 5 virFunc(); 6 } 7 8 virtual void virFunc() { 9 std::cout << "A virFunc" << std::endl; 10 } 11 }; 12 13 class B : public A { 14 public: 15 B() { 16 std::cout << "create B" << std::endl; 17 virFunc(); 18 } 19 20 virtual void virFunc() { 21 std::cout << "B virFunc" << std::endl; 22 } 23 }; 24 25 int main() { 26 A *p = new B(); //这里本来是希望先调用基类构造函数A(),然后再调用B::virFunc(),再调用派生类构造函数B(),最后调用B::virFunc(),但是实际上不是这样的 27 delete p; 28 return 0; 29 }
A *p = new B(); //这里本来是希望先调用基类构造函数A(),然后再调用B::virFunc(),再调用派生类构造函数B(),最后调用B::virFunc(),但是实际上不是这样的,两次不都是调用B::virFunc()。实际调用如下:先调用基类构造函数A()、再调用A::virFunc(),再调用派生类构造函数B()、最后调用B::virFunc()。
别人的解释:
当 new B() 执行时,首先调用父类的构造函数,即调用 A 的构造函数,我们都知道,在类的成员函数中有一个隐藏的 this 指针,代表的是当前对象的地址,在调用 A() 时,传递给 A() 的 this 指针应该是新创建的 B 的对象的地址,所以 A() 可类似为:
1 A(this) { // 此时的 this 为新创建的 B 的对象的指针 2 std::cout << "create A" << endl; 3 this->A::virFunc(); // 这里实际上是通过子类的指针去调用父类中的函数,没有产生多态的效应 4 }
《Effective C++》条款9:永远不要在构造函数或析构函数中调用虚
5、C++中构造函数相互调用的问题
1)能否在有参构造函数中调用无参构造函数
不可以,原因如下,加入有如下类:
#include <stdlib.h> #include <iostream> using namespace std; class CLS { int m_i; CLS( int i ) : m_i(i){} CLS() { CLS(0); //产生了一个匿名的临时CLS对象,它调用CLS(int)构造函数 } }; int main() { CLS obj; //此时会先为obj分配内存,然后调用无参构造函数, cout << obj.m_i << endl; system("PAUSE"); return 0; }
CLS obj;这里已经为obj分配了内存,然后调用默认构造函数,但是默认构造函数还未执行完,却调用了另一个构造函数,这样相当于产生了一个匿名的临时CLS对象,它调用CLS(int)构造函数,将这个匿名临时对象自己的数据成员m_i初始化为0;但是obj的数据成员并没有得到初始化。于是obj的m_i是未初始化的,因此其值也是不确定的
关键是让第二个构造函数在第一次分配好的内存上执行,而不是分配新的内存,可以像下面这样做:
1 #include <stdlib.h> 2 #include <iostream> 3 using namespace std; 4 5 class CLS 6 { 7 int m_i; 8 CLS( int i ) : m_i(i){} 9 CLS() 10 { 11 new (this)CLS(0); //在原来类对象内存的基础上调用另外一个构造函数 12 } 13 }; 14 int main() 15 { 16 CLS obj; 17 cout << obj.m_i << endl; 18 19 system("PAUSE"); 20 return 0; 21 }
2)无参构造函数中如果有修改类成员会不会对当前正在构造的类产生影响,这种调用方式有什么优势或者缺点?
无参构造函数调用有参构造函数不会对当前构造的类产生影响,是因为在调用这个有参构造函数的时候会创建一个临时的类对象,并且初始化这个临时的类对象中的变量。
像上面那样改进后的优势:可以重复使用一些代码。
6、段错误
段错误是指访问的内存超出了系统所给这个程序的内存空间。
做题中最常见的原因有两个:
第一是在某个函数内开的数组过大,导致该函数的栈无法容纳数组,造成爆栈。
解决方法:把数组开到函数外边,此时数组保存在全局变量区。
第二是有指针越界。
解决方法:检查是否有数组下标越界,或者定义的指针指向了错误的地方。
7、关于.h文件重复定义的问题
假如有一个c.h头文件,在该头文件中定义了一个help()函数,两个cpp文件a.cpp和b.cpp都包含了这个头文件c.h,请问这样会报错吗?
主要问题是要使用#ifndef 解决重复定义的问题,但是又包含下面两种编译方式,分别会出现不同的问题,例如下面的文件:
1 #ifndef _C_H 2 #define _C_H 3 int help(){ 4 return 1; 5 } 6 #endif
1 #include "c.h" 2 3 int helpa(){ 4 return help(); 5 }
1 #include "c.h" 2 3 int helpb(){ 4 return help(); 5 }
1 #include "a.cpp" 2 #include "b.cpp" //这样写是为了不创建b.h文件,为了省事,而不写#include "b.h" 3 #include "iostream" 4 5 int main(){ 6 std::cout<<helpa()<<std::endl; 7 std::cout<<helpb()<<std::endl; 8 std::cout<<help()<<std::endl; 9 return 0; 10 }
编译方式一 g++ main.cpp -o test 后执行./test是不会报错的,因为在c.h中使用了#ifdef,那么这样不会出现报"重复定义"的错误

编译方式二:g++ mian.cpp b.cpp a.cpp -o test 这样是会报“重复定义”的错误!!! 需要注意的是#include "a.cpp"和#include "b.cpp"都是将a.cpp中的文件和b.cpp中的文件全部拷贝到main.cpp中

解决方法:新建c.cpp文件,把help()函数的实现和定义分离,用c.cpp去实现help()函数就没有问题了
8、哪些函数不能被继承
1)构造函数、拷贝构造函数
2)析构函数
3)赋值运算符重载函数(对等号的重载),其余的运算符重载函数可以被子类继承
B1继承A,举例:
1 class A1 2 { 3 public: 4 int operator=(int a) 5 { 6 return 8; 7 } 8 9 int operator+(int a) 10 { 11 return 9; 12 } 13 }; 14 15 class B1 : public A1 16 { 17 public: 18 int operator-(int a) 19 { 20 return 7; 21 } 22 }; 23 24 int main() 25 { 26 B1 v; 27 cout << (v + 2) << endl; // OK, print 9 28 cout << (v - 2) << endl; // OK, print 7 29 cout << (v = 2) << endl; // Error, see below //这里会报错在B1类中找不到对=号的重载函数 30 31 return 0; 32 }
报错信息如下;
error C2679: binary '=' : no operator defined which takes a right-hand operand of type 'const int' (or there is no acceptable conversion)
意思是说编译器找不到int operator=(int a)这个成员函数可以调用。
原因如下:
1,每一个类对象实例在创建的时候,如果用户没有定义“赋值运算符重载函数”,那么,编译器会自动生成一个隐含和默认的“赋值运算符重载函数”。所以,B1的实际上的声明应该类似于下面这种情况:
1 class A1 2 { 3 public: 4 int operator=(int a) 5 { 6 return 8; 7 } 8 9 int operator+(int a) 10 { 11 return 9; 12 } 13 }; 14 15 class B1 : public A1 16 { 17 public: 18 B1& operator =(const B1& robj); // 注意这一行是编译器添加的 19 int operator-(int a) 20 { 21 return 7; 22 } 23 };
2,C++标准规定:如果派生类中声明的成员与基类的成员同名,那么,基类的成员会被覆盖,哪怕基类的成员与派生类的成员的数据类型和参数个数都完全不同。显然,B1中的赋值运算符函数名operator =和基类A1中的operator =同名,所以,A1中的赋值运算符函数int operator=(int a);被B1中的隐含的赋值运算符函数B1& operator =(const B1& robj);所覆盖。 A1中的int operator=(int a);函数无法被B1对象访问。
3,程序中语句v = 2实际上相当于v.operator =(2);,但是A1中的int operator=(int a);已经被覆盖,无法访问。而B1中默认的B1& operator =(const B1& robj);函数又与参数2的整数类型不相符,无法调用。
一个空类什么时候不是空类? ---- 当C++编译器通过它的时候。如果你没有声明下列函数,体贴的编译器会声明它自己的版本。这些函数是:一个拷贝构造函数,一个赋值运算符,一个析构函数,一对取址运算符。另外,如果你没有声明任何构造函数,它也将为你声明一个缺省构造函数。所有这些函数都是公有的。换句话说,如果你这么写:
1 class Empty{}; 2 3 和你这么写是一样的: 4 5 class Empty { 6 public: 7 Empty(); // 缺省构造函数 8 Empty(const Empty& rhs); // 拷贝构造函数 9 10 ~Empty(); // 析构函数 ---- 是否 11 // 为虚函数看下文说明 12 Empty& 13 operator=(const Empty& rhs); // 赋值运算符 14 15 Empty* operator&(); // 取址运算符 16 const Empty* operator&() const; 17 };
9、那些函数不可以写成虚函数
1)构造函数
简单讲就是没有意义。虚函数的作用在于通过子类的指针或引用来调用父类的那个成员函数。而构造函数是在创建对象时自己主动调用的,不可能通过子类的指针或者引用去调用。
2)内联函数
inline函数在编译时被展开,虚函数在运行时才能动态的邦定函数
3)静态成员函数
静态成员函数编译时被展开,虚函数在运行时才能动态的邦定函数;且静态成员函数不属于类成员。
4)友元函数
10、C++11中的= delete 和 = default
首先要知道C++类默认生成的函数
默认构造函数、默认拷贝构造函数、默认析构函数、默认赋值运算符 这四个是我们通常大都知道的。但是除了这四个,还有两个,那就是取址运算符和 取址运算符 const
1 class Empty 2 { 3 public: 4 Empty(); // 缺省构造函数 5 Empty( const Empty& ); // 拷贝构造函数 6 ~Empty(); // 析构函数 7 Empty& operator=( const Empty& ); // 赋值运算符 8 Empty* operator&(); // 取址运算符 9 const Empty* operator&() const; // 取址运算符 const 10 11 };
1、= delete
禁止使用编译器默认生成的函数,且可以用于任何函数
假如上面的几个函数中,不想使用其中某个,可以将其定义为private,或者使用=delete
1 #include <iostream> 2 using namespace std; 3 4 class DataOnly { 5 public: 6 DataOnly () {} 7 ~DataOnly () {} 8 9 DataOnly (const DataOnly & rhs) = delete; //禁止使用该函数 10 DataOnly & operator=(const DataOnly & rhs) = delete; //禁止使用该函数 11 12 DataOnly (const DataOnly && rhs) {} 13 DataOnly & operator=(DataOnly && rhs) {} 14 }; 15 16 int main(int argc, char *argv[]) { 17 DataOnly data1; 18 DataOnly data2(data1); // error: call to deleted constructor of 'DataOnly' 19 DataOnly data3 = data1; // error: call to deleted constructor of 'DataOnly' 20 return 0; 21 }
再如unique_ptr智能指针不允许unique_ptr指针之间相互赋值,即不允许调用unique_ptr的拷贝构造函数和对等号的重载函数,方法是在这两个函数的声明后加上=delete
2、= default
允许我们使用=default来要求编译器生成一个默认函数,如
1 struct Point { 2 Point()=default; 3 Point(int _x, int _y) : x(_x), y(_y) {} 4 int x = 0; 5 int y = 0; 6 }
这样相当于无参的构造函数也是可以使用的。
11、Linux下修改文件权限命令的集合
1)chmod a+x file.cpp #为file.cpp文件的全部人添加可执行的权限
主要u表示所有者(user)、g表示该用户下所有者所在的组(group)、o表示其他人(other)、a表示全部人(all)
r表示可读权限、w表示可写权限、x表示对文件来说是可执行权限、对目录来说是可进入该目录的权限
2)chmod 777 file.cpp #为file.cpp的所有者、所在组、其他人都添加rwx权限
其中rwx代表的数字如右边:r--4、w---2、 x---1
3)chmod u+x file.cpp #为file.cpp的所有者添加可执行的权限
chmod a-x file.cpp #为file.cpp的全部人(所有者、所在组、其他人)减去可执行的权限
chmod o=rw file.cpp #为file.cpp的其他人添加可读和可写的权限,x没有写就是不添加该权限
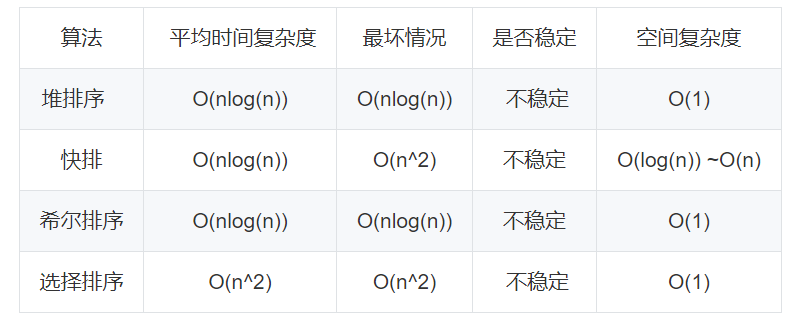
12、排序算法时间和空间时间复杂度、最坏情况下的时间复杂度
13、32位系统可以访问多大的内存
32位系统是微软为32位计算机设计的操作系统,可以一次性处理32位数据;
32位系统理论上最多支持4G内存,算法是2的32次方,429967296(Bit)。不过在使用时一般32位系统最大只能识别3.75G内存,(BIOS内存,CPU缓存等硬件都需要占领一部分内存,将他们的寻址空间分配完成后才会将剩余的寻址空间分配给内存条)。就算你是8G内存,能派的上用场的也就是3.75G。
64位系统可以最大支持128G的内存
14、虚拟内存的作用?
虚拟内存提供了三个重要的能力: 缓存,内存管理,内存保护
1. 将主存视为一个存储在磁盘上的地址空间的高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据
2. 为每个进程提供了一致的地址空间,简化内存管理
3. 保护了每个进程的地址空间不被其他进程破坏
15、请完成宏定义: #define swap(a,b)
1 #include <iostream> 2 using namespace std; 3 4 #define Swap(a,b) { c = a; a = b ; b = c;} 5 6 int main() 7 { 8 int a = 1, b = 2; 9 int c; 10 Swap(a, b); //在调用Swap()之前,必须将Swap()宏定义中使用到的变量全部声明 11 cout << a << " " << b << endl; 12 13 system("pause"); 14 return 0; 15 }
16、模板类的优点和缺点
优点:
1. 灵活性, 可重用性和可扩展性;
2. 可以大大减少开发时间,模板可以把用同一个算法去适用于不同类型数据,在编译时确定具体的数据类型;
3. 模版模拟多态要比C++类继承实现多态效率要高, 无虚函数, 无继承;
缺点:
1. 易读性比较不好,调试比较困难;
2. 模板的数据类型只能在编译时才能被确定;
3. 所有用基于模板算法的实现必须包含在整个设计的.h头文件中, 当工程比较大的时候, 编译时间较长;
二、计算机网络相关
1、输入一个网址后到网页显示全过程描述
1)输入网址,DNS解析出网址对应的服务器IP地址
在输入地址的时候,浏览器就在书签、浏览历史记录中智能的匹配网址对应的URL了。如果没有对应的URL,那么就开始解析这个网址(域名),首先也是先从本地本地硬盘的 hosts 文件查找有没有这个网址对应的IP地址,如果没有,那么浏览器会发出一个 DNS请求到本地DNS服务器,如果在本地DNS服务器中没有查询到,那么需要去域服务器中继续查找,域服务器会告诉本地DNS服务器你要查找的域名解析服务器地址,然后本地DNS服务器向域名的解析服务器发出请求,这时就能收到一个域名和IP地址对应关系。
URL:URL由三部分组成:资源类型、存放资源的主机域名、资源文件名。
本地DNS服务器:本地DNS服务器一般都是你的网络接入服务器商提供,比如中国电信,中国移动。
2)浏览器根据获得的服务器IP地址,向服务器发起一个http请求
拿到服务器的IP地址后,浏览器会以一个任意的端口(1024<端口<65535)向服务WEB程序(常用的有httpd,nginx等)80端口发起TCP的连接请求。建立了TCP连接之后,浏览器再发起一个http请求。
3)服务器的永久重定向
服务器给浏览器响应一个301永久重定向响应,这样浏览器就会访问“http://www.google.com/” 而非“http://google.com/”。
重定向原因:
4)浏览器使用新的地址重新向服务器发送一个http请求
5)服务器处理浏览器发送的http请求,并向浏览器发送一个http响应
6)浏览器显示HTML
四、牛客网面经总结
1、C++中的char*、const char* 和string之间的相互转换
1). string转const char*
1 string s ="abc"; 2 const char* c_s = s.c_str();
2). const char*转string
1 const char* c_s ="abc"; 2 string s(c_s);
3).string转char*
1 string s ="abc"; 2 char* c; 3 const int len = s.length(); 4 c =new char[len+1]; 5 strcpy(c,s.c_str());
4). char*转string
1 char* c ="abc"; 2 string s(c);
5). const char*转char*
1 const char* cpc ="abc"; 2 char* pc =new char[100];//足够长 3 strcpy(pc,cpc);