作者 | 武博士、宋知达、袁雪瑶、聂文韬
人类需要经过各式各样的学习才有办法认识这个世界。
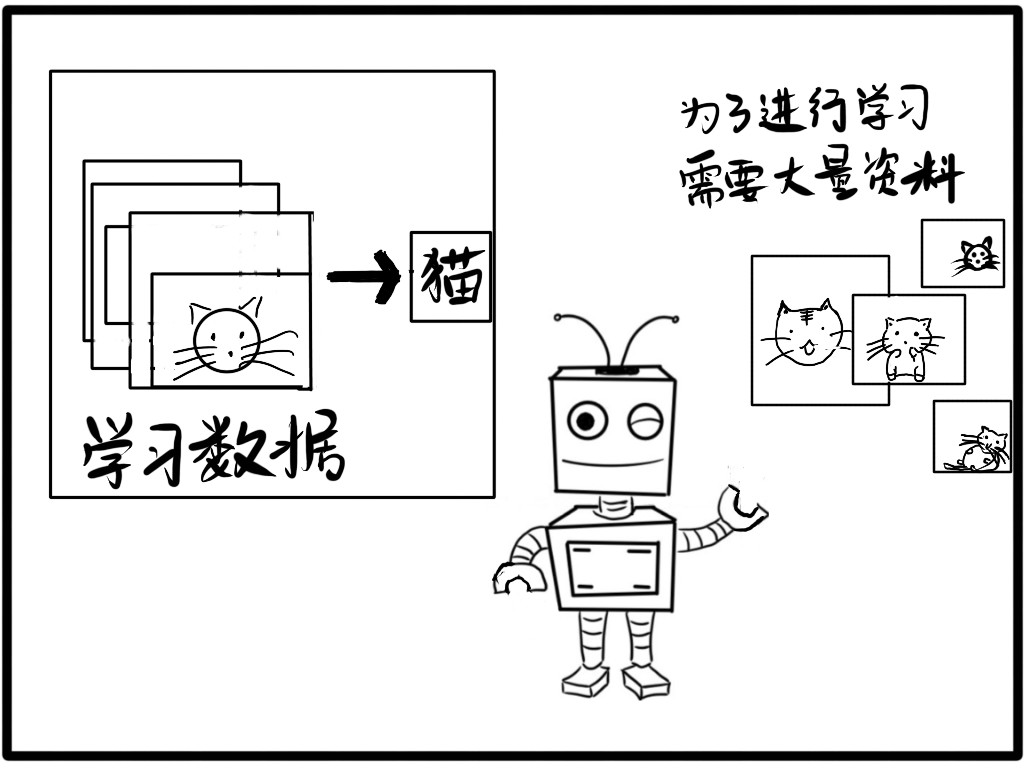
当小朋友第一次看到猫后,可能会问爸爸妈妈,这个胖乎乎有胡子的可爱动物是什么。当父母告诉她:这就是猫的时候,她就会理解到,这种生物就是猫。 以后她碰到各种各样的猫的时候,都能认得出来。

计算机也是一样,在学习的过程中,可以自动找出“猫的具体特征”,以及形成自己一套识别方法,即使没有遇到的问题也可以按照原先的思路去解决。
但是,和人的学习略有不同,计算机是通过从大量的数据中找到规律,进行预测和分类,达到即使没有遇到过同类型的问题,它也能解决!
机器学习,顾名思义,机器可以像孩子一样学习。机器不再是简单运行人类程序的工具,它可以自己去学习!变得更加聪明!
机器学习大致上可以分为:监督学习、非监督学习、强化学习三类。 接下来我们依次说明这三类机器学习。

监督学习
在监督学习中,我们会将所有的数据和配对的答案都输入计算机,让计算机去学习这些数据的特征规则和答案之间的联系。

在监督学习中:
-
带有答案的数据是必须的,因为计算机在学习(训练)的过程中,不断在对答案,修正自己的问题。
-
带有答案的数据的数量是巨大的,计算机没有我们想象中聪明,它需要在每次的错误中寻找自己的不足。目前少样本学习或者举一反三,还是只有人类能做到。
监督学习大致可以分为分类问题和回归问题。
分类问题
监督学习中,我们一直在举识别猫的例子,其实这是一种分类的过程,计算机可以将图片进行分类。分类不仅仅局限于图片,我们对于文字内容也可以进行分类哦。
很困扰我们的垃圾邮件就是可以通过计算机识别文字后,进行分类。
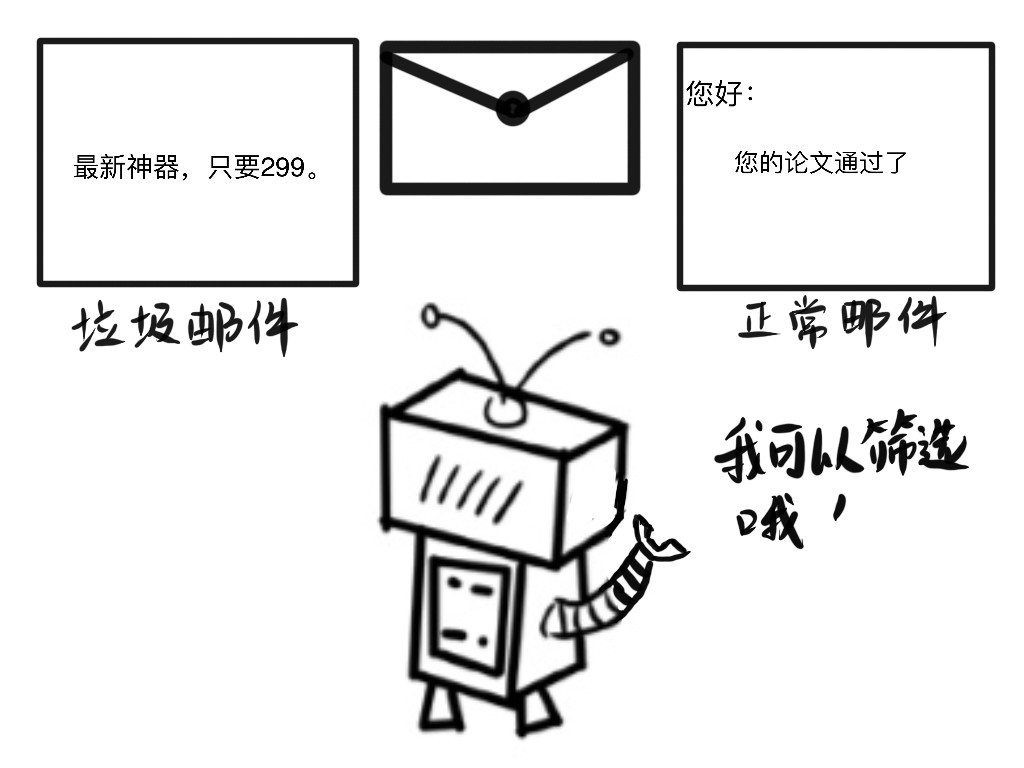
计算机垃圾邮件的分类可不是像我们想象中那样,直接告诉你答案,它会进行垃圾邮件和正常邮件的概率标注。 比如这封邮件里面有大量的“折扣”、“促销”的字眼,是垃圾邮件的概率 92%。我们人类按照计算机具体给出的概率标注进行具体的区分。
除了图片、文字,计算机还可以区分声音。
回归问题
一提到回归问题,好多小伙伴就会感到困惑,什么是回归?回到那儿呀?归到哪儿呀?
其实,回归问题就是预测问题,只不过,在机器学习领域,把它称作回归。
大家熟悉的口袋妖怪-宝可梦的攻击力,我们可以从历史数据中进行预测。

回归就是从一堆数据中,找到能够准确找到这对数据的趋势线,得出一个具体数值的过程。
分类和回归具体的区别:
我们可以将天气预测为晴天、阴天、雨天、雪天,这就是分类的过程。但是如果预测具体的天气温度,就是回归。
过度学习和懒散学习(过拟合问题和欠拟合问题)
我们会不会这么想:是不是给计算机的数据越多,它就能越好地进行分类和回归呢。答案是“NO!”
计算机过度学习在学术上称为“过拟合” !
我举一个自己特别痛苦的例子:在我上初中的时候,有一天老师通知我们说过一段时间要进行数学测验,大家好好复习。我就把课后题全部都做了 3 遍,心想,这次我的成绩肯定会很好! 但是,考试的时候,卷子发下来,发现是数学竞赛,我无语凝噎……

但是,话说回来,如果连课后题都懒得会做,考试就无从谈起了。这就是“懒散学习”,得到结果恐怕不只是眼泪,可能还有肉体的摧残。 这就是“欠拟合“。
写到这里,不禁对咱们中国儒家文化中的“中庸之道”暗自佩服!
非监督学习
世界中的许多问题,都不是监督学习能够解决的,因为好多连人类都不知道答案。
机器学习中的非监督学习,就是让计算机分析一堆不知道答案的数据,然后找出结构和规则的过程。
举例来说,电商对客户分类的过程,就是一种非监督学习。刚开始我们没有办法为客户贴上准确的标签,但是渐渐地,从不同客户群体购买记录、浏览记录中,就可以区分出一些共性特征,将其聚类。 我们经常收到的商品推荐服务,就是电商给某一类标签用户推荐他们可能喜欢的商品。
强化学习
人类会在成功与失败的教训中,学习到如何才能顺利达到目的。
我想大多数同学在小时候家长不在家的时候,都有过玩游戏和写作业之间的纠结。如果玩游戏,现在是爽到了,但是如果爸爸妈妈突然回来;如果明天老师检查……虽然头悬两把利剑,但是很多同学还是拿起了手柄和键盘。
写作业虽然现在很痛苦,但是如果爸妈突然回家,如果考试成绩很好,好处大大滴。
想必是先有了痛苦的经历,很多同学痛定思痛,还是拿起了笔,写作业。

同样的,计算机可以由尝试错误的方式,经历多次失败和成功,然后学习到规律。失败和成功完全就是以奖励的多少决定——这就是强化学习。
让我们大众熟悉人工智能的 AlphaGo ,基本原理就是强化学习。
转自: https://mp.weixin.qq.com/s/bHqQdp2B9NCiEC5SNsBbRA