//2019.08.03下午
#机器学习算法的数据归一化(feature scaling)
1、数据归一化的必要性:
对于机器学习算法的基础训练数据,由于数据类型的不同,其单位及其量纲也是不一样的,而也正是因为如此,有时它会使得训练集中每个样本的不同列数据大小差异较大,即数量级相差比较大,这会导致在机器学习算法中不同列数据的权重很大的差异,数量级大的数据所体现出来的影响会远远大于数量级小的数据(比如样本中不同列数据对k-近邻算法中欧拉距离大小的影响会因为数据的数量级而存在很大差异)。基于以上的问题,我们需要对于样本的每一行数据进行归一化处理,消除其大小尺寸对于算法训练效果的影响。
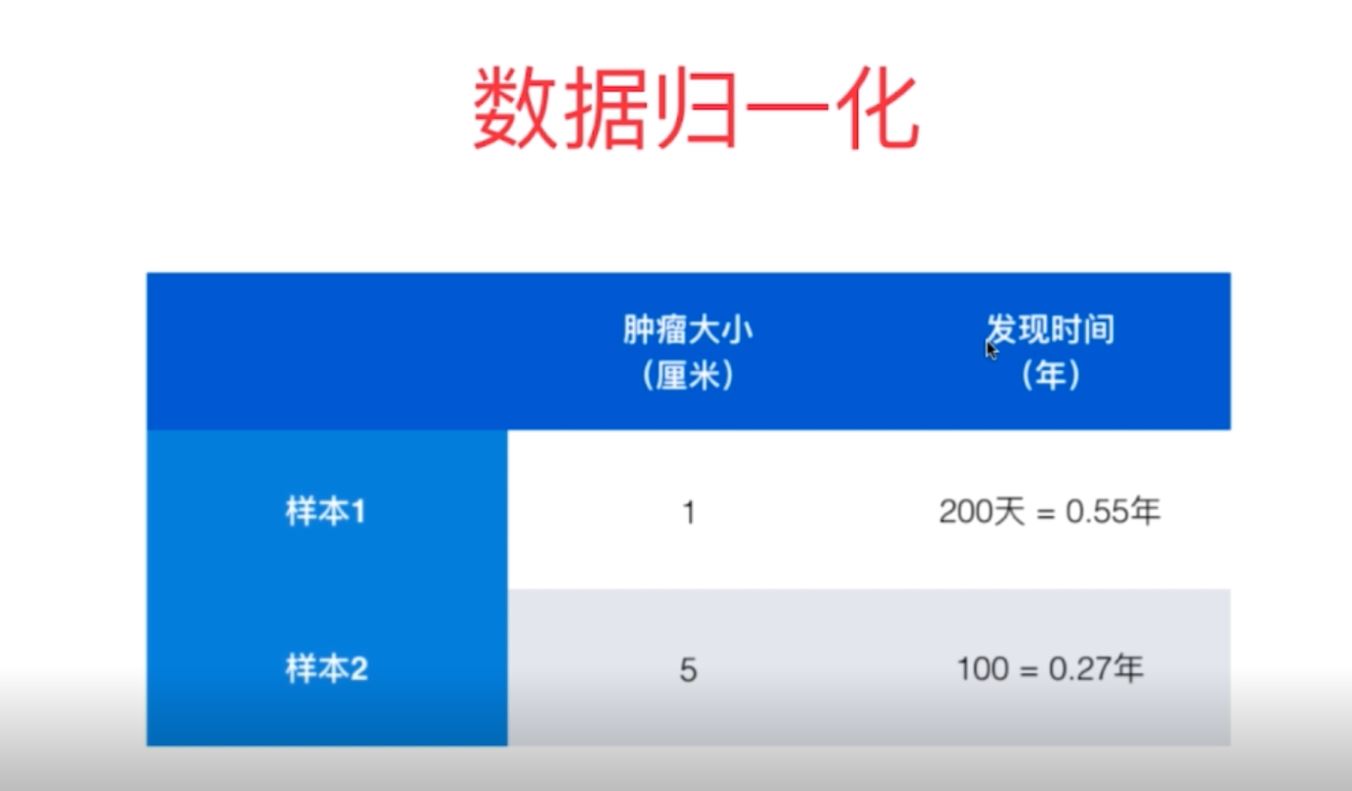
图1
2、数据归一化的处理方式:
(1)最值归一化处理方式(normalization)
将样本每一列属性数据统一归一化映射到0-1之间,最常用方法如下:

图2
这个方法是比较方便简单的归一化处理方式,主要适用于具有边界的数据(比如学生成绩,图片的像素点特征值等)
(2)均值方差归一化处理方式(standardization)
将数据归一化到正负数之间,最终处理为均值为0,方差为1的正态分布中,这种处理方式适用于数据分布没有明显的边界,数据中存在一些极端的数据值;而对于明显存在数据边界的数据也是比较适合的。

图3
综上所述,对于一般的数据分布采用均值方差归一化的方法是比较普适的。
3、数据归一化原理代码实现举例:
import numpy as np
import matplotlib.pyplot as plt
x=np.random.randint(1,100,(50,2))
print(x)
x=np.array(x,dtype=float)
print(x)
x[:,0]=(x[:,0]-np.min(x[:,0]))/(np.max(x[:,0])-np.min(x[:,0]))
x[:,1]=(x[:,1]-np.min(x[:,1]))/(np.max(x[:,1])-np.min(x[:,1])) #1均值归一化处理实现
print(x)
plt.figure()
plt.scatter(x[:,0],x[:,1],color="r")
print(np.mean(x[:,0]))
print(np.std(x[:,0]))
print(np.mean(x[:,1]))
print(np.std(x[:,1]))
x[:,0]=(x[:,0]-np.mean(x[:,0]))/(np.std(x[:,0]))
x[:,1]=(x[:,1]-np.mean(x[:,1]))/(np.std(x[:,1])) #2均值方差归一化处理方式
print(x)
plt.scatter(x[:,0],x[:,1],color="g")
plt.show()
print(np.mean(x[:,0]))
print(np.std(x[:,0]))
print(np.mean(x[:,1]))
print(np.std(x[:,1]))
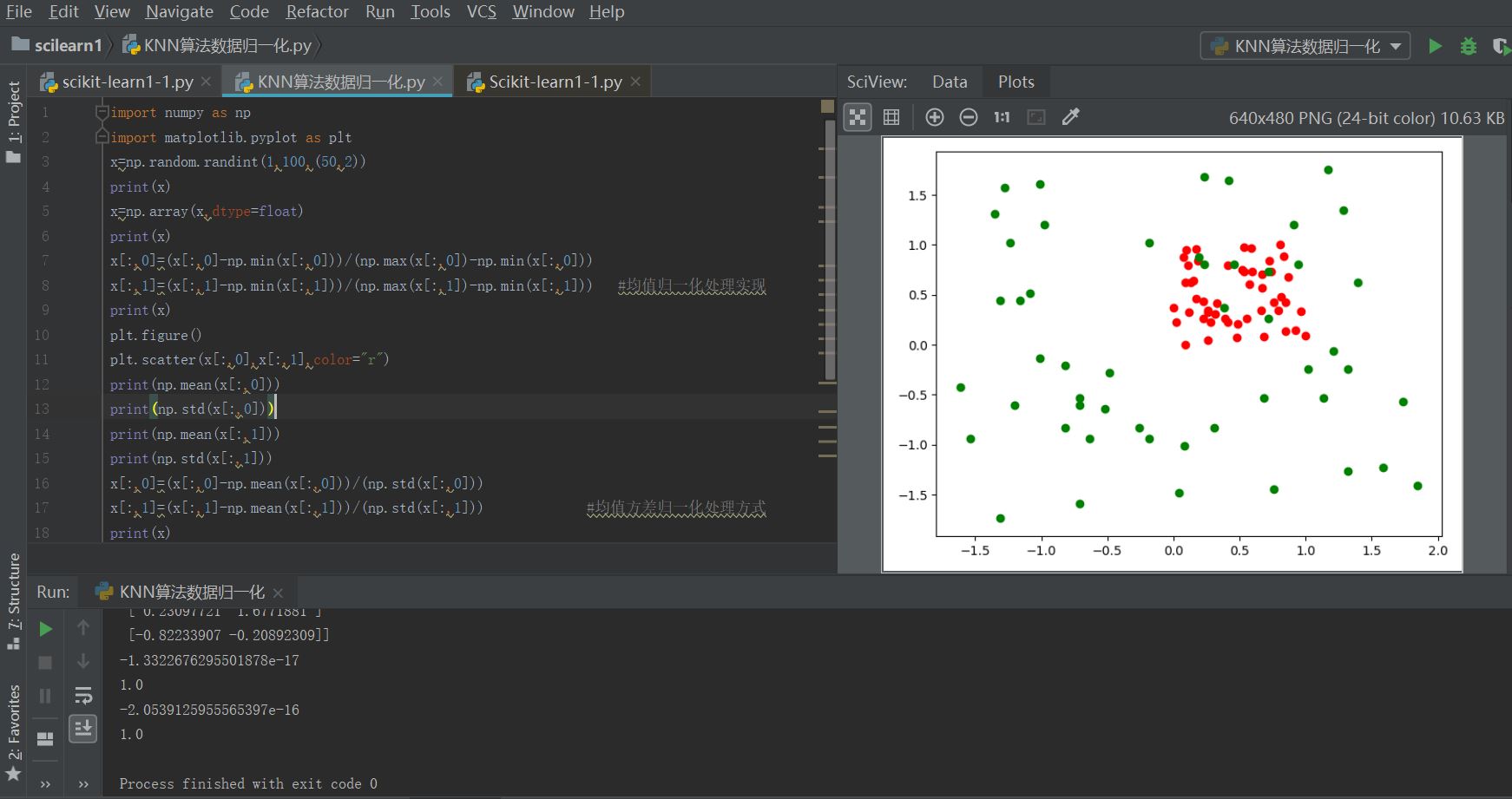
图4
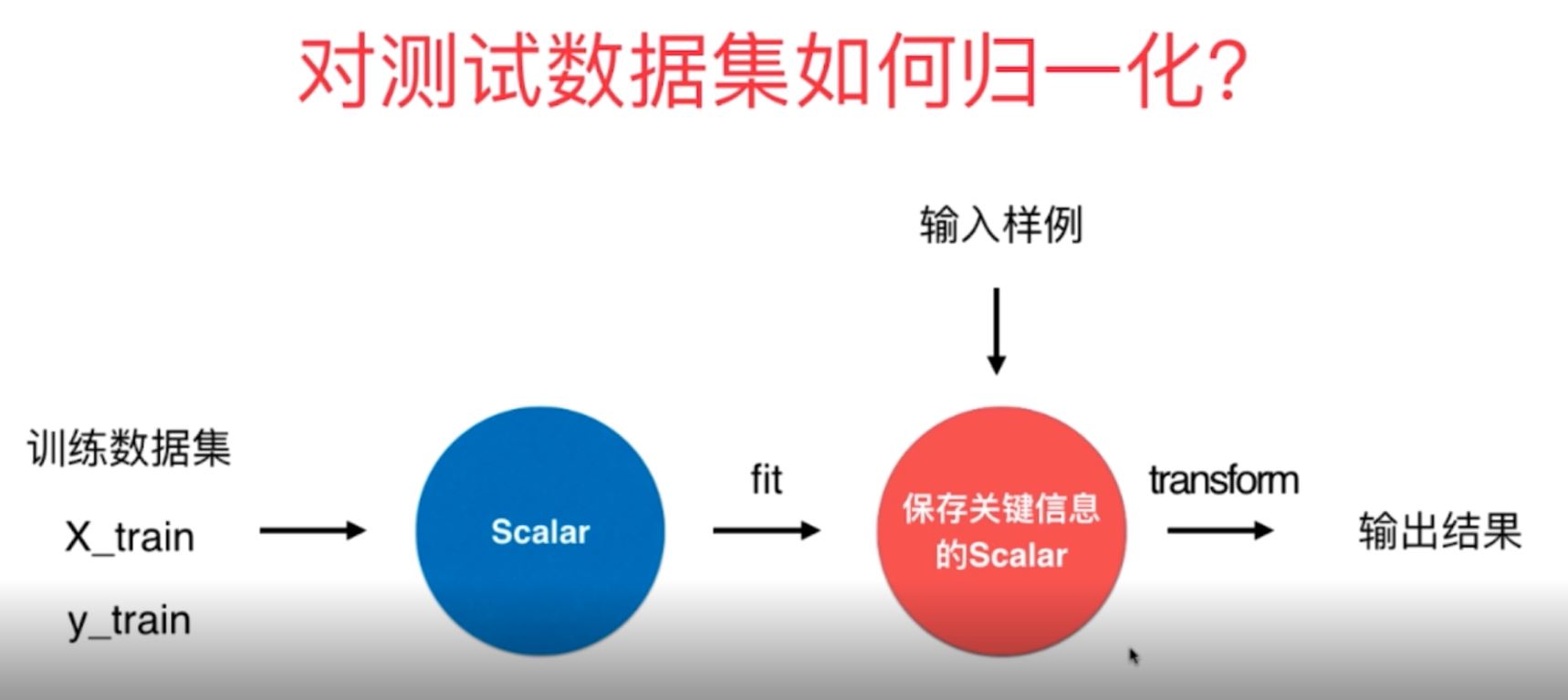
4、对于测试数据是用来模拟真实环境下的数据,而真实数据是没有固定的均值和方差的,因此在对测试数据进行处理的时候不可以利用已有测试数据集的均值与方差进行数据归一化处理,也需要使用训练数据集的平均值和方差进行相应的归一化处理.
5、在scikitlearn中有函数Scaler对于训练数据和测试数据进行相应的归一化,其归一化方式也有多种方式,常用的还是之前讲过的均值归一化MinMaxScaler和均值方差归一化函数StandardScaler,其归一化原理如上所讲。
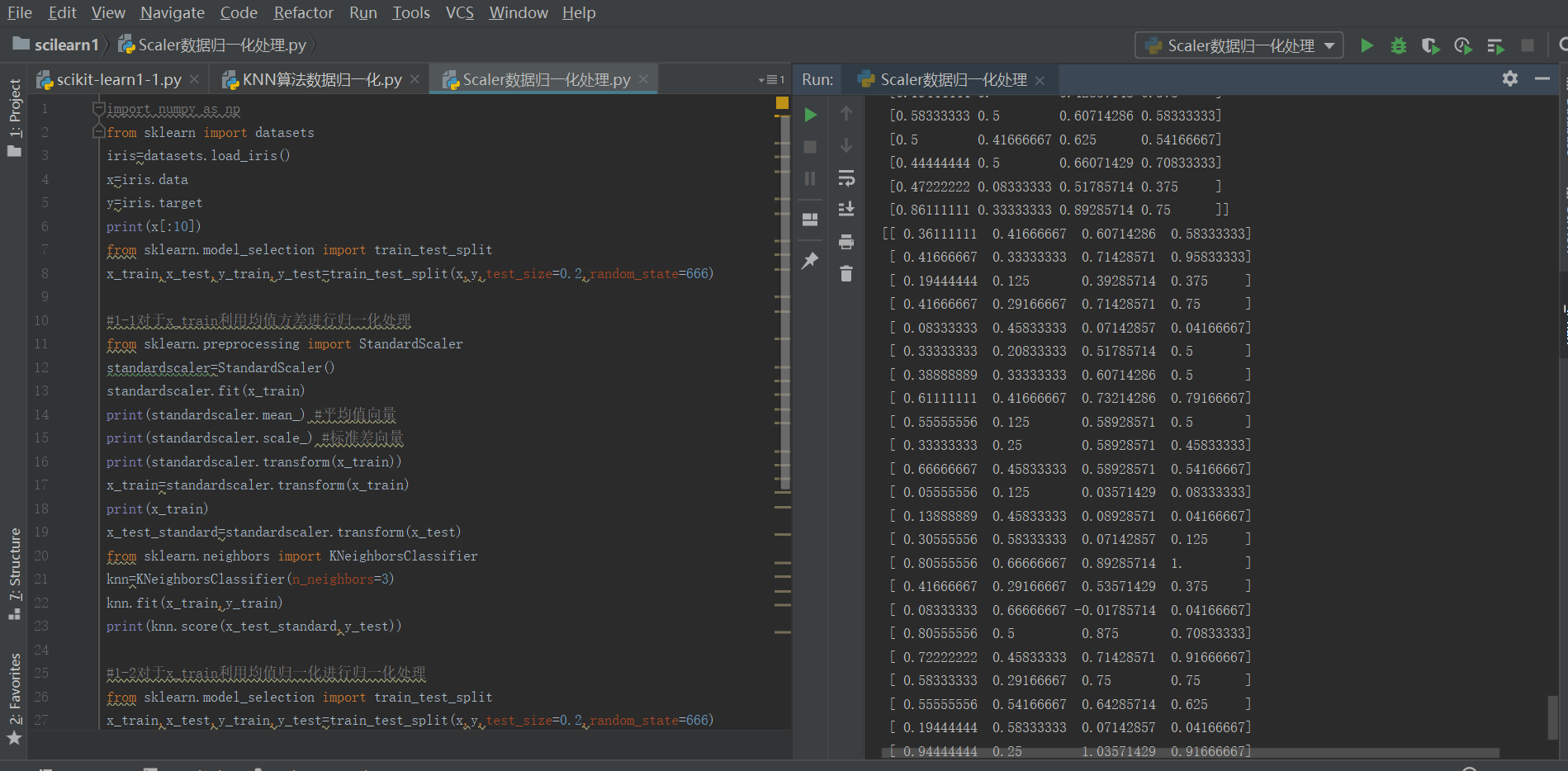
具体k-近邻算法的整体数据归一化处理、训练以及预测过程在scikitlearn中调用如下:
import numpy as np
from sklearn import datasets
#导入训练的数据集
iris=datasets.load_iris()
x=iris.data
y=iris.target #初始化属性数据和标记数据
print(x[:10])
#对于数据进行相应预处理(分割为训练集和测试集数据)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=666)
#1-1对于x_train利用均值方差StandardScaler进行归一化处理
from sklearn.preprocessing import StandardScaler
standardscaler=StandardScaler()
standardscaler.fit(x_train)
print(standardscaler.mean_) #平均值向量
print(standardscaler.scale_) #标准差向量
print(standardscaler.transform(x_train))
x_train=standardscaler.transform(x_train)
print(x_train)
x_test_standard=standardscaler.transform(x_test)
#导入相应的机器学习算法模块
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(n_neighbors=3)
knn.fit(x_train,y_train)
print(knn.score(x_test_standard,y_test))
#1-2对于x_train利用均值MinMaxScaler进行归一化处理(整体过程与上面类似)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=666)
from sklearn.preprocessing import MinMaxScaler
standardscaler1=MinMaxScaler()
standardscaler1.fit(x_train)
x_train=standardscaler1.transform(x_train)
print(x_train)
x_test_standard1=standardscaler1.transform(x_test)
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(n_neighbors=3)
knn.fit(x_train,y_train)
print(x_test_standard1)
print(knn.score(x_test_standard1,y_test))
运行结果如下: