1 前言
data.table 是 R 中一个非常通用和高性能的包,使用简单、方便而且速度快,在 R 语言社区非常受欢迎,每个月的下载量超过 40 万,有近 650 个 CRAN 和 Bioconductor 软件包使用它。如果你是 R 的使用者,可能已经使用过 data.table 包。
而对于 Python 用户,同样存在一个名为 datatable 包,专注于大数据支持、高性能内存/内存不足的数据集以及多线程算法等问题。在某种程度上,datatable 可以被称为是 Python 中的 data.table。
2 Datatable简介

为了能够更准确地构建模型,现在机器学习应用通常要处理大量的数据并生成多种特征,这已成为必要的。而 Python 的 datatable 模块为解决这个问题提供了良好的支持,以可能的最大速度在单节点机器上进行大数据操作 (最多100GB)。datatable 包的开发由 H2O.ai 赞助,它的第一个用户是 Driverless.ai。
2.1 安装
Mac OS系统
pip install datatable
Linux系统
安装过程需要通过二进制分布来实现
# If you have Python 3.5
pip install https://s3.amazonaws.com/h2o-release/datatable/stable/datatable-0.8.0/datatable-0.8.0-cp35-cp35m-linux_x86_64.whl
# If you have Python 3.6
pip install https://s3.amazonaws.com/h2o-release/datatable/stable/datatable-0.8.0/datatable-0.8.0-cp36-cp36m-linux_x86_64.whl
很遗憾的是,目前 datatable 包还不能在 Windows 系统上工作,但 Python 官方也在努力地增加其对 Windows 的支持。更多的信息可以查看 Build instructions 的说明。
https://datatable.readthedocs.io/en/latest/install.html
2.2 数据读取
这里使用的数据集是来自 Kaggle 竞赛中的 Lending Club Loan Data 数据集, 该数据集包含2007-2015期间所有贷款人完整的贷款数据,即当前贷款状态 (当前,延迟,全额支付等) 和最新支付信息等。整个文件共包含226万行和145列数据,数据量规模非常适合演示 datatable 包的功能。
数据集:
"""
链接:https://pan.baidu.com/s/1_vVviJWj6A9I05F7bmQNlg 密码:y4jd
"""
import numpy as np
import pandas as pd
import datatable as dt
首先将数据加载到 Frame 对象中,datatable 的基本分析单位是 Frame,这与Pandas DataFrame 或 SQL table 的概念是相同的:即数据以行和列的二维数组排列展示。
使用datatable读取数据
%%time
dft = dt.fread('loan.csv')
CPU times: user 23.8 s, sys: 2.32 s, total: 26.1 s
Wall time: 2.54 s
这个数据集一共226万行,145列,将近1.2G的数据,通过datatable读取只用了2.54s

如上所示,fread() 是一个强大又快速的函数,能够自动检测并解析文本文件中大多数的参数,所支持的文件格式包括 .zip 文件、URL 数据,Excel 文件等等。此外,datatable 解析器具有如下几大功能:
- 能够自动检测分隔符,标题,列类型,引用规则等。
- 能够读取多种文件的数据,包括文件,URL,shell,原始文本,档案和 glob 等。
- 提供多线程文件读取功能,以获得最大的速度。
- 在读取大文件时包含进度指示器。
- 可以读取 RFC4180 兼容和不兼容的文件。
使用pandas读取数据
%%time
df = pd.read_csv('loan.csv')
CPU times: user 27.3 s, sys: 4.68 s, total: 31.9 s
Wall time: 28.5 s
由此可以看出,结果表明在读取大型数据时 datatable 包的性能明显优于 Pandas,Pandas 需要接近30秒的时间来读取这些数据,而 datatable 只需要2秒多。
2.3 帧转换 (Frame Conversion)
对于当前存在的帧,可以将其转换为一个 Numpy 或 Pandas dataframe 的形式,如下所示:
numpy_df = dft.to_numpy()
pandas_df = dft.to_pandas()
下面,将 datatable 读取的数据帧转换为 Pandas dataframe 形式,并比较所需的时间,如下所示:
由于 Lending Club Loan Data 数据集的数据量过大,使用to_padnas操作,jupyte服务容易挂机,所以使用一个数据集较小的进行测试。
%%time
dft = dt.fread('baba.csv')
pandas_df = dft.to_pandas()
CPU times: user 2.44 ms, sys: 287 µs, total: 2.72 ms
Wall time: 2.62 ms
通过datatable读取数据加上将其转换为DataFrame数组,一共是2.62ms.
%%time
dft = pd.read_csv('baba.csv')
CPU times: user 7.95 ms, sys: 3.18 ms, total: 11.1 ms
Wall time: 14.4 ms
单通过pandas读取数据,总共需要14.4ms。
看起来将文件作为一个 datatable frame 读取,然后将其转换为 Pandas dataframe比直接读取 Pandas dataframe 的方式所花费的时间更少。因此,通过 datatable 包导入大型的数据文件再将其转换为 Pandas dataframe 的做法是个不错的主意。
2.4 帧的基础属性
下面来介绍 datatable 中 frame 的一些基础属性,这与 Pandas 中 dataframe 的一些功能类似。
print(dft.shape) # (nrows, ncols)
print(dft.names[:5]) # top 5 column names
print(dft.stypes[:5]) # column types(top 5)
______________________________________________________________
(2260668, 145)
('id', 'member_id', 'loan_amnt', 'funded_amnt', 'funded_amnt_inv')
(stype.bool8, stype.bool8, stype.int32, stype.int32, stype.float64)
也可以通过使用 head 命令来打印出输出的前 n 行数据,如下所示:
dft.head(10)
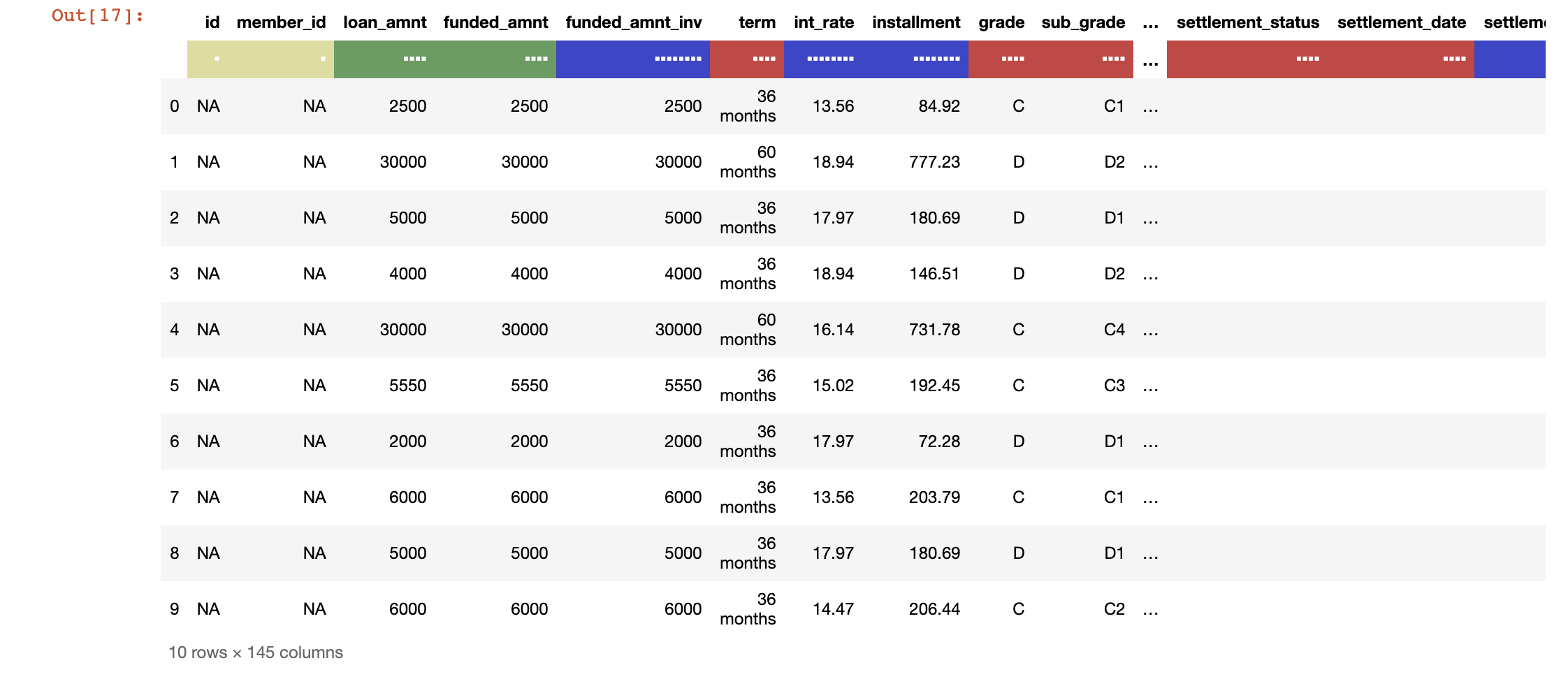
注意:这里用颜色来指代数据的类型,其中红色表示字符串,绿色表示整型,而蓝色代表浮点型。
2.5 统计总结
在 Pandas 中,总结并计算数据的统计信息是一个非常消耗内存的过程,但这个过程在 datatable 包中是很方便的。如下所示,使用 datatable 包计算以下每列的统计信息:
dft.sum() dft.nunique()
dft.sd() dft.max()
dft.mode() dft.min()
dft.nmodal() dft.mean()
下面分别使用 datatable 和Pandas 来计算每列数据的均值,并比较二者运行时间的差异。
Datatable读取
%%time
dft.mean()
__________________________________________________________________
CPU times: user 3.56 s, sys: 5.35 ms, total: 3.56 s
Wall time: 302 ms
Pandas读取
pandas_df.mean()
__________________________________________________________________
Throws memory error.
使用 Pandas 计算时抛出内存错误的异常。
3 数据操作
和 dataframe 一样,datatable 也是柱状数据结构。在 datatable 中,所有这些操作的主要工具是方括号,其灵感来自传统的矩阵索引,但它包含更多的功能。诸如矩阵索引,C/C++,R,Pandas,Numpy 中都使用相同的 DT[i,j] 的数学表示法。下面来看看如何使用 datatable 来进行一些常见的数据处理工作。
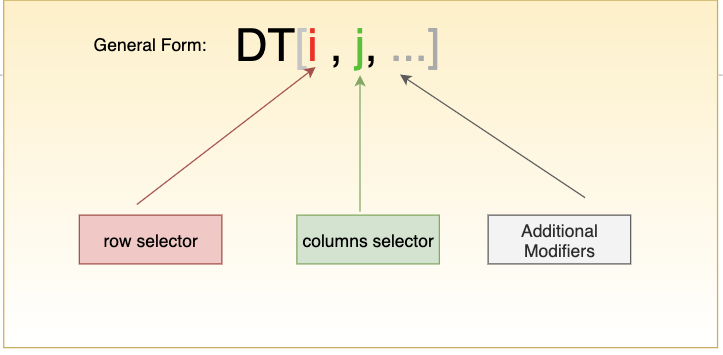
选择行/列的子集
下面的代码能够从整个数据集中筛选出所有行及 funded_amnt 列:
dft[:,'funded_amnt']
展示如何选择数据集中前5行3列的数据,如下所示:
dft[:5,:3]
帧排序
- datatable 排序
在 datatable 中通过特定的列来对帧进行排序操作,如下所示:
%%time
dft.sort('funded_amnt_inv')
CPU times: user 1.47 s, sys: 77.1 ms, total: 1.55 s
Wall time: 147 ms
- Pandas 排序
%%time
pandas_df.sort_values(by = 'funded_amnt_inv')
___________________________________________________________________
CPU times: user 8.76 s, sys: 2.87 s, total: 11.6 s
Wall time: 12.4 s
可以看到两种包在排序时间方面存在明显的差异。
删除行/列
下面展示如何删除 member_id 这一列的数据:
del dft[:, 'member_id']
分组 (GroupBy)
与 Pandas 类似,datatable 同样具有分组 (GroupBy) 操作。下面来看看如何在 datatable 和 Pandas 中,通过对 grade 分组来得到 funded_amout 列的均值:
- datatable 分组
%%time
for i in range(100):
dft[:, dt.sum(dt.f.funded_amnt), dt.by(dt.f.grade)]
CPU times: user 9.45 s, sys: 643 ms, total: 10.1 s
Wall time: 861 ms
- pandas 分组
%%time
for i in range(100):
pandas_df.groupby("grade")["funded_amnt"].sum()
____________________________________________________________________
CPU times: user 12.9 s, sys: 859 ms, total: 13.7 s
Wall time: 13.9 s
.f 代表什么
在 datatable 中,f 代表 frame_proxy,它提供一种简单的方式来引用当前正在操作的帧。在上面的例子中,dt.f 只代表 dt_df。
过滤行
在 datatable 中,过滤行的语法与GroupBy的语法非常相似。下面就来展示如何过滤掉 loan_amnt 中大于 funding_amnt 的值,如下所示。
dft[dt.f.loan_amnt>dt.f.funded_amnt,"loan_amnt"]
保存帧
在 datatable 中,同样可以通过将帧的内容写入一个 csv 文件来保存,以便日后使用。如下所示:
dft.to_csv('output.csv')
有关数据操作的更多功能,可查看 datatable 包的说明文档
地址:https://datatable.readthedocs.io/en/latest/using-datatable.html
总结
在数据科学领域,与默认的 Pandas 包相比,datatable 模块具有更快的执行速度,这是其在处理大型数据集时的一大优势所在。然而,就功能而言,目前 datatable 包所包含的功能还不如 pandas 完善。相信在不久的将来,不断完善的 datatable 能够更加强大。