什么是数据库?
数据库就是一个文件系统用于存储数据,根据用户访问权限不同实现操作不同,通常一个应用对应一个数据库
数据库是以一定方式储存在一起、能与多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合,可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据进行新增、查询、更新、删除等操作
MySQL :数据库管理软件
软件的安装:https://jingyan.baidu.com/article/77b8dc7fa347d96174eab601.html
软件的卸载:1.在控制面板中删除软件 2.在program文件中删除MySQL文件 3.在C盘program data(隐藏文件)中删除MySQL文件(不删除再次重装会在安装最后一步卡住)
然后接触结构化查询语言SQL
SQL语言的分类
- DDL: 数据库的定义, 与数据库/表结构: create, drop, alter 增删改
- DML: 数据操纵语言: 操作表数据 insert update delete 插入修改删除
- DCL: 数据控制语言: 设置用户的访问权限 安全
- DQL: 数据查询语言: select from where 查询
接下来对数据库进行操作
- 登录数据库服务器
打开命令提示符cmd 输入 mysql -u账户名(一般是root)-p密码 (切记后面不加;)
mysql -uroot -proot - 创建数据库
create database 数据库的名字 (character set 字符集(utf8,gbk ....)collate 校对规则) - 删除数据库
drop database 数据库名字 - 修改数据库
alter database character set 字符集 (这个修改只针对修改数据库的定义) - 查看数据库
1.查看所有数据库 show databases;
2.查看指定的数据库定义 show create database 数据库名字
3.查看当前正在使用的数据库 select database(); - 选中数据库(开始使用)
use 数据库的名字
数据库中有数据表,表中有列,接下来看表结构的操作
- 创建表
create table 表名(
列名 列的类型(长度) 约束,
列名2 列的类型(长度) 约束
);
(长度这一块还不是很了解)
列的类型和约束:点这儿(ps:在主键约束后加入auto_increament(自动添加数值,例如ID 123456的加下去))
例子如下create table student ( sid char(12) primary key, sname char(6) not null, sex char(2) check(sex IN ('boy','girl')), sclass char(15) );
- 删除表
drop table 表名 - 修改表
1.添加列 alter table 表名 add 列名 列的类型 列的约束
2.修改列 alter table 表名 modify 列名 列的类型 列的约束
3.修改列名 alter table 表名 change 旧列名 新列名 列的类型 列的约束
4.删除列 alter table 表名 drop 列名
5.修改表的字符集 alter table 表名 character set 字符集
6.修改表名 rename table 旧表名 to 新的表名 - 查看表
1.查看当前数据库中的所有表名 show tables ;
2.查看表的定义结构/创建语句 show create table 表名:
3.查看表的结构 desc 表名 ;
对表的结构操作完后,就是对数据进行操作
- 插入数据
insert into 表名(列名1,列名2)values(值1,值2);(针对列名添加数据)
insert into 表名 values(值1,值2);(按列名的顺序全部满足了值,不用添加列名) - 批量插入数据
insert into 表名values(值1,值2),(值1,值2),(值1,值2); - 删除数据
1.delete from 表名 [where 条件];
(如果没有添加条件)则 delete from 表名;数据全部删除
2.truncate table 表名;先删除表,再重建表
问题:delete和truncate的删除区别
回答:delete是将数据一条一条删除,truncate是将表删除后重新建新表,数量少delete高效,数量多truncate高效。 - 更新数据
1.单条更新 update 表名 set 列名=值, 列名=值 [where 条件];
例子:update 表名 set name=‘李四’, sex=‘男’ [where ID = 5];(这里要注意一点,参数如果是字符,时间,日期要用单引号括起)
2.全体更新 update 表名 set 列名=值; - 查询数据
1.通用格式: select [distinct] [*] [列名1,列名2] from 表名 where 条件 group by ..having 条件过滤 order by 排序 (以下一步步进行分析)
2.查询表的所有数据,表格形式显示 select * from 表名;
3.查询一列的数据 select 列名 from 表名;
.别名查询 【关键字 as(可省略)】
表别名:select p.列名,p.列名2 from 表名 as p;
列别名:select 列名 as 自定义名 from 表名;
例子:select name as 学生名字 from student;(后表格显示的name是学生名字)
5.显示去除表中重复的值后的表
select distinct 列名 from 表名 ;(应用于查价格类的数据)
6.运算查询 (仅在运算结果上运算)
select * , 列名(+-*/)X(某值) as 自定义名 from 表名;(会出来一列处理后的数据)
例子:select * ,price * 1.5 as 涨价 from product;
7.条件查询 【where 关键字】附加:判断是否为空的关键字【is null , is not null】
select * from 表名 where 条件;(在SQL中,不等于是<>)
例子:查商品价格不等于88的商品 select * from 表名 where price <> 88;
此处有必要提及逻辑运算符【and且 or或 not,between x and y(在x和y之间,y要大于x)】
例如 price>90 and price<100 price>90 or price>100 price between 10 and 100;
8.模糊查询【like 关键字】 _代表一个字符 %代表多个字符
例子:查名字带饼字的商品 select * from 表名 where name like ‘%饼%’;
查第二个字是熊的商品 select * from 表名 where name like ‘_熊%’;
9.在某个范围获得值【in 关键字】
select * from 表名 where 列名 in (范围);
例子:select * from 表名 where ID in (1,4,5);(显示ID是1,4,5的数据)
10.排序查询【order by 关键字】asc(ascend升序)desc(descend降序)默认升序
select * from 表名 order by 列名;--->升序
select * from 表名 order by 列名 desc;--->降序
例子:查找名字有小字,按价格降序排放
select * from 表名 where 列名 like '%小%' order by 列名2 desc;
11.聚合函数 sum()求和,avg()求平均,count()统计数量,max(),min();
例子:所有商品价格总和 select sum(列名) from 表名;
例子:所有商品价格平均价 select avg(列名) from 表名;
例子:所有商品个数 select count(列名) from 表名;
!!!where 条件后不能添加聚合函数
例子:查价格大于平均价格的商品
select * from 表名 where price > (select avg(price) from 表名);
12.分组 【group by 关键字】
例子:根据ID字段分组,统计商品个数,例如ID为1的有几个 select 列名 , count(*)from 表名 group by 列名
例子:分组统计每组平均价且平均价>60; select 列名 , avg (列名2)from 表名 group by 列名 having avg(price)> 60;
(having 作用和 where 差不多,但having可接聚合函数,且放在分组后,而where不可接聚合函数,且放分组前) - 编写顺序SFWGHO select...from ...where...group by... having...order by
- 执行顺序FWGHSO from...where...group by ...having...select...oder by
大致上了解了对数据的操作,接下来就是多表操作
多表之间关系维护是通过外键约束来实现【foreign key 关键字】,列1会参考列2来建立,如果无对应的列2则无法添加列1 ,写法有两种
- (建表后使用)alter table 表名1 add foreign key(受约束的列1)references category(受参考的列2);
例子:alter table product add foreign key (cno) refenences 表名2 (cid); - (建表时使用)另起一行 foreign key (在该表中的列1)references (另一个表名)(另一个表名的列2);
- (建表后使用)alter table 表名1 add foreign key(受约束的列1)references category(受参考的列2);
注意:这里写的时候要是两边数据不相同的话也是会约束失败,像cno中多了另一个cid没有的数值。
如何从分类表中删除分类为5的信息:
- 错误的方法是delete from 表名 where 条件;(因为这里被外键约束了,无法通过这种方法删除)
- 首先得去另一个表删除分类为5的信息,再从原表删除分类为5的信息;
建表原则
我们知道建数据库的原则是:一个项目或一个应用建立一个数据库
那么多表建表原则分为了三种
- 一对一
例如商品和商品分类
在多的一方添加一个外键,指向为一的一方的主键 - 多对多
例如学生和课程
多建一个中间表(就是在数据库中多建一张表),将其拆成一对多来处理,中间表至少有两个外键指向原来表的主键(意味中间表还可以有其他的属性) - 一对多
例如公民和身份证
。。。。。。。。。(这个我也很懵逼,貌似不常用,等我了解清楚再来补充)
这里有个对上面内容的解释
- 主键约束:不能为空,数值唯一,有且只有一个
- 唯一约束:可以为空,数值唯一,不可以作为其他表的外键
安装SQLyog(省略了,网上有大佬分享资源的)
接下来是比较重要的多表查询
- 交叉连接查询(也叫笛卡尔积,得出的是两张表的乘积,得出的数据大多是无意义的,要做数据过滤)
select * from 表名1,表名2;(如下图)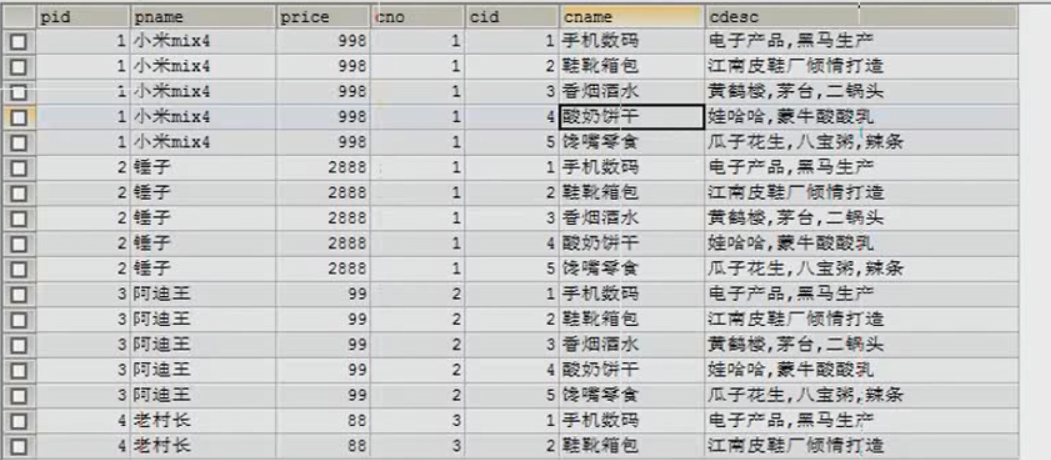
过滤得有意义的数据
select * from 表名1 As p,表名2 As c where 条件(例如:p.cno = c.cid); 就是下面的了 - 内连接查询
1.隐式内连接
select * from 表1 p ,表2 c where 条件(p.列名= c.列名);
2.显式内连接
select * from 表1 p inner join 表2 c on (条件)p.cno=c.cid;
你问他们有什么区别
区别就是隐式内连接在查出结果的基础上做where条件过滤,而显式内连接是带着条件查询结果,相比之下更高效;
3.左/右外连接
select * from 表名1 p left/right outer join 表名2 c on 条件;
就是将左/右表(表名1)中所有数据查出,如果右/左边没有对应数据则用null代替; - 分页查询【limit 关键字】
select * from 表名 limit 索引,显示个数;(索引是从第几个开始(0是第一个),显示个数是一次显示的数据有多少个,每页显示的开始计算公式 startindex = (index - 1)* 显示个数) - 子查询
例子:查询分类名为XXXX的所有商品
select * from 表名 where 列名1(分类名) = (select 列名2 from 表名2 where 列名2 = XXXX);
例子:查询(商品,商品分类)信息
1.左连接方法:select p.pname , c.cname from 表名1 p left outer join 表名2 c on p.cno = c.cid;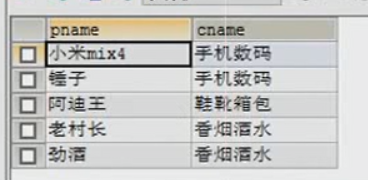
2.子查询方法select pname , (select cname from category c where p.cno= c.cid)As 商品分类名称 from product p;
1.查看mysql的端口号:
show global variables like 'port';
2.查看mysql的连接数:
show processlist;
3.查看mysql全部的连接数:
show full processlist;
4.查看最大的连接数:
show variables like '%max_connections%';
5.修改最大连接数:
set global max_connections =151;
6.查看mysql中的所有变量:
show varables;
7.查看mysql中的变量也可进行模糊查询:
show variables like 'default%';