0.PTA得分截图

1.本周学习总结
1.1 图的存储结构
1.1.1 邻接矩阵
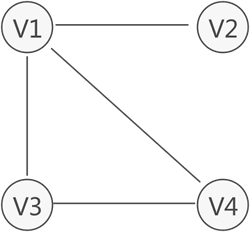
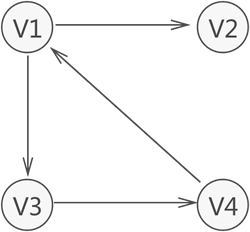
- 概念:用一个一维数组存放图中所有顶点数据;用一个二维数组存放顶点间关系(边或弧)的数据,这个二维数组称为邻接矩阵。用邻接矩阵表示图,很容易确定图中任意两个顶点是否有边相连。邻接矩阵分为有向图邻接矩阵和无向图邻接矩阵。对无向图(无向简单图)而言,邻接矩阵一定是对称的,而且对角线一定为零,有向图则不一定如此。
- 邻接矩阵结构体定义
#define MAXV 最大顶点个数
//声明顶点类型
typedef struct {
int number;/*顶点编号*/
Info Type info;/*顶点其他信息*/
}VertexType;
//声明邻接矩阵类型
typedef struct {
int edges[MAXV][MAXV];/*邻接矩阵*/
int n, e;/*顶点数、边数*/
VertexType vexs[MAXV];/*顶点信息*/
}MatGraph;
- ①无向图:
②有向图:
- 建图
void CreateMGraph(MGraph& g, int n, int e)//邻接矩阵建图
{ //n顶点个数,e边个数
int i, j;
int a, b;
for (i = 1; i <= n; i++) //注意输入的起始顶点值从0还是1开始
for (j = 1; j <= n; j++)
g.edges[i][j] = 0;
for (i = 0; i < e; i++)
{
cin >> a >> b;
g.edges[a][b] = 1;
g.edges[b][a] = 1;
}
g.n = n;
g.e = e;
}
1.1.2 邻接表
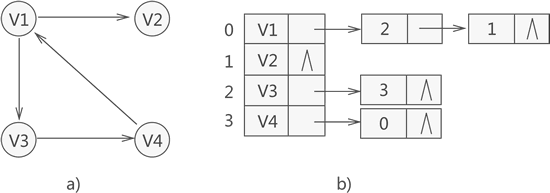
- 概念:邻接表是数组和链表的结合。对于每个顶点都建立一个单链表存储该顶点所有的邻接点。然后将定义一个结构体VNode,里面保存顶点邻接点的链表和顶点其他信息。设置VNode类型的结构体数组AdjGraph[]就可以保存图中所有顶点的邻接点,达到保存图中所有边的目的。结构体数组AdjGraph[]即为邻接表。
- 邻接表的结构体定义
typedef struct ANode //边结点;
{
int adjvex;//指向该边的终点编号;
struct ANode*nextarc;//指向下一个邻接点;
INfoType info;//保存该边的权值等信息;
}ArcNode;
typedef struct //头结点
{
int data;//顶点;
ArcNode *firstarc;//指向第一个邻接点;
}VNode;
typedef struct
{
VNode adjlist[MAX];//邻接表;
int n,e;//图中顶点数n和边数e;
}AdjGraph;
- ①无向图:
- ②有向图:
1.1.3 邻接矩阵和邻接表表示图的区别
- 思路:1、在邻接矩阵表示中,无向图的邻接矩阵是对称的。邻接矩阵需要申请一个二维数组,空间复杂度为O(n2)
2、在邻接表的表示中,无向图的同一条边在邻接表中存储的两次。因为共有e条边和n个结点,需要开辟n个空间来保存结点,e个空间来保存e条边信息,所以,创建邻接表的空间复杂度为O(n+e)
1.2 图遍历
1.2.1 深度优先遍历
1、首先以一个未被访问过的顶点作为起始顶点,沿当前顶点的边走到未访问过的顶点;
2、当没有未访问过的顶点时,则回到上一个顶点,继续试探别的顶点,直至所有的顶点都被访问过。
- 代码
int visited[MaxN]={0}; //记录顶点的访问状态
int result[MaxN]; //result数组记录DFS遍历结果
int N,E,k;// N为顶点数,E为边数,k记录遍历结果下标
void DFS(int v){
visited[v]=1;
result[k++]=v;
for (int i=0;i<N;i++){
if (G[v][i]==1 && visited[i]==0)
DFS(i);
}
}
int main(){
for (int i=0;i<N;i++){
k = 0;
if (visited[i]==0){
DFS(i);
//用{}打印出一个连通分量
cout<<"{ ";
for (int j=0;j<k;j++)
cout<<result[j]<<' ';
cout<<"}"<<endl;
}
}
return 0;
}
1.2.2 广度优先遍历
- 思路:有点类似于树的层序遍历,也就是像剥洋葱一样,“一层一层地剥开♩♩♩”。即从一个选定的点出发,将与其直接相连的点都收入囊中,然后依次对这些点去收与其直接相连的点。重复到所有点都被访问然后结束。
- 代码:
int visited[MaxN]={0}; //记录顶点的访问状态
int result[MaxN]; //result数组记录BFS遍历结果
int N,E,k;// N为顶点数,E为边数,k记录遍历结果下标
void BFS(int v){
queue<int> q;
q.push(v);
visited[v]=1;
result[k++]=v;
while(!q.empty()){
int u = q.front();
q.pop();
for(int i=0;i<N;i++){
if (G[u][i]!=0 && visited[i]!=1){
visited[i]=1;
q.push(i);
result[k++]=i;
}
}
}
}
int main(){
for (int i=0;i<N;i++){
k = 0;
if (visited2[i]==0){
BFS(i);
//用{}打印出一个连通分量
cout<<"{ ";
for (int j=0;j<k;j++)
cout<<result[j]<<' ';
cout<<"}"<<endl;
}
}
return 0;
}
1.3 最小生成树
- 概念:最小生成树是一副连通加权无向图中一棵权值最小的生成树。
1.3.1 Prim算法求最小生成树
- Prim算法代码:
#define INF 32767
void Peim(MGraph g, int v)
{
int lowcost[MAXV];
int min;
int closest[MAXV];
int i, j, k;
for (i = 0; i < g.n; i++)
{
lowcost[i] = g.edges[v][i];//置初值,放入顶点v和所有顶带你的权值
closest[i] = v;
}
for (i = 1; i < g.n; i++)//n-1条边,进行n-1次
{
min = INF;
for (j = 0; j < g.n; j++)//遍历找到权值最小的
{
if (lowcost[j] != 0 && lowcost[j] < min)
{
min = lowcost[j];
k = j;//记录下标
}
}
lowcost[k] = 0;//lowcost为0表示该顶点已使用
for (j = 0; i < g.n; j++)//遍历所有顶点,比较找到的顶点与其他顶点的权值是否比原来小
{
if (lowcsost[j] != 0 && g.edges[k][j] < lowcost[j])
{
lowcost[j] = g.edges[k][j];
closest[j] = k;//改变权值和相邻的顶点
}
}
}
}
- Prim算法的2个辅助数组:
closest数组存储最小边依附的顶点编号,lowcost存储最小边的权重,通过记录比较权重找到最小边的顶点,并连通将二者改变后继顶点的权重。 - 时间复杂度:
代码中存在两层循环,时间复杂度为O(n^2)。
1.3.2 Kruskal算法求解最小生成树
- 概念:假设一个图有m个节点,n条边。首先,我们需要把m个节点看成m个独立的生成树,并且把n条边按照从小到大的数据进行排列。在n条边中,我们依次取出其中的每一条边,如果发现边的两个节点分别位于两棵树上,那么把两棵树合并成为一颗树;如果树的两个节点位于同一棵树上,那么忽略这条边,继续运行。等到所有的边都遍历结束之后,如果所有的生成树可以合并成一条生成树,那么它就是我们需要寻找的最小生成树,反之则没有最小生成树。
- Kruskal算法代码
typedef struct
{
int u;//边的起始顶点
int v;//边的终止顶点
int w;//边的权值
}Edge;
void Kruskal(MatGraph g)//Kruskal算法
{
int i, j, u1, v1, sn1, sn2, k;
int vest[MAXV];
Edge E[MaxSize];//存放图中的所有边
k = 0;//e数组的下标从0开始计
for(i=0;i<g.n;i++)//由g产生边集E,不重复选取同一条边
for(j=0;j<=i;j++)
if (g.edges[i][j] != 0 && g.edges[i][j] != INF)
{
E[k].u = i; E[k].v = j;
E[k].w = g.edgess[i][j];
k++;
}
InsertSort(E, g, e);//采用直接插入排序对E数组按权值递增排序
for (i = 0;i < g.n;i++)//初始化辅助数组
vest[i] = i;
k = 1; j = 0;//k表示当前构造生成树的第几条边,初值为1;E中边的下标,初值为0
while (k < g.n)//生成的边数小于n时循环
{
u1 = E[j].u; v1 = E[j].v;//取一条边的两个顶点
sn1 = vest[u1];
sn2 = vest[v1];//分别得到两个顶点所属的集合编号
if (sn1 != sn2)//两个顶点属于不同的集合,该边是最小生成树的一条边
{
printf("(%d,%d):%d
", u1, v1, E[j].w);//输出最小生成树的一条边
k++;//生成边数增1
for (i = 0;i < g.n;i++)//两个集合统一编号
if (vest[i] == sn2)//集合编号为sn2的改为sn1
vest[i] = sn1;
}
j++;//扫面下一条边
}
}
- 因为Kruskal算法的执行时间仅与图中的边数有关,与顶点个数无关,时间复杂度:O(elog2e)。
1.4 最短路径
1.4.1 Dijkstra算法求解最短路径
- 思路:从起点(或者说源点)开始,将其装进一个“袋子”里,然后不断往这个袋子里搜罗顶点,当顶点收进去后,能保证从源点到该顶点的当前最短路径是确定的。每次收录的顶点是在未收录的集合里寻找最短路径最小的点(即离源点最近的点),然后将与收进去的顶点直接相连的点的最短路径进行更新。
- 该算法需要dist和path两个数组,其中path数组则用于存放最短路径,通过改变path数组的值改变顶点的前继结点,dist数组用于存放最短的路径长度,通过比较其中元素找到最短路径。
- 代码:
void Dijkstra(MGraph g, int v)//源点v到其他顶点最短路径
{
int dist[MAXV], path[MAXV],s[MAXV];
int mindistance,u;//u为每次所选最短路径点
for (int i = 0; i < g.n; i++)//初始化各数组
{
s[i] = 0;//初始已选入点置空
dist[i] = g.edges[v][i];//初始化最短路径
if (dist[i] < INF) path[i] = v;
else path[i] = -1;//即无直接到源点V的边,因此初始化为-1
}
s[v] = 1;//源点入表示已选
for (int j = 0; j < g.n; j++)//要将所有点都选入需循环n-1次
{
mindistance = INF;//每次选之前重置最短路径
for (int i = 1; i < g.n; i++)//每次都遍历源点以外其他点来选入点
{
if (s[i] == 0 && dist[i] < mindistance)//在未选的点中找到最短路径
{
mindistance = dist[i];
u = i;//u记录选入点
}
}
s[u] = 1;//最后记录的u才为最后选入点
for (int i = 1; i < g.n; i++)//修正数组值
{
if (s[i] == 0)//!!仅需修改未被选入点的,已选入的既定
{
if (g.edges[u][i] < INF && dist[u] + g.edges[u][i] < dist[i])//先判断选入点到与该点存在时再比较判断
{
dist[i] = dist[u] + g.edges[u][i];
path[i] = u;
}
}
}
}
Dispath(dist, path, s, g.n, v);
}
- 时间复杂度为O(n^2)。
1.4.2 Floyd算法求解最短路径
- 概念:Floyd算法又称为插点法,是一种利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法,与Dijkstra算法类似。
- 代码:
void Floyd(Graph G)
{
int A[MAXVEX][MAXVEX]; //建立A数组
int path[MAXVEX][MAXVEX]; //建立path数组
int i, j, k;
for (i=0;i<G.n;i++)
for (j=0;j<G.n;j++)
{
A[i][j]=G.edges[i][j];
if (i!=j && G.edges[i][j]<INF)
path[i][j]=i; //i和j顶点之间有一条边时
else
path[i][j]=-1;
}
for (k=0;k<G.n;k++) //求Ak[i][j]
{
for (i=0;i<G.n;i++)
for (j=0;j<G.n;j++)
if (A[i][j]>A[i][k]+A[k][j]) //找到更短路径
{
A[i][j]=A[i][k]+A[k][j]; //修改路径长度
path[i][j]=path[k][j]; //修改最短路径为经过顶点k
}
}
}
- 时间复杂度:O(n³)
1.5 拓扑排序
- 概念:在一个有向图中,如果我们需要访问一个节点,要先把这个节点的所有前驱节点都访问过后,才能访问该节点。按照这样的顺序访问所有节点得到的序列叫做拓扑序列。在一个有向图中求一个拓扑序列的过程叫做拓扑排序。

序列:ABCD或者ACBD - 结构体
typedef struct {
Vertex data;//顶点信息
int count;//存放入度
AreNode *firstarc;//头结点类型
}VNode;
- 代码:
void TopSort(AdjGraph *G)
{
int node[MAXV];
int counts = 0;
int top = -1;
int stacks[MAXV];
ArcNode *p;
int i, j, k = 0;
for (i = 0; i < G->n; i++)//初始化count
{
G->adjlist[i].count = 0;
}
for (i = 0; i < G->n; i++)
{
p = G->adjlist[i].firstarc;
while (p)//计算每个结点入度
{
G->adjlist[p->adjvex].count++;
p = p->nextarc;
}
}
for (i = 0; i < G->n; i++)
{
if (G->adjlist[i].count == 0)//结点为0入栈
{
stacks[++top] = i;
}
}
while (top > -1)
{
i = stacks[top--];
node[k++] = i;//进入数组
counts++;
p = G->adjlist[i].firstarc;
while (p)
{
j = p->adjvex;
G->adjlist[j].count--;//该节点入度-1
if (G->adjlist[j].count == 0)
{
stacks[++top] = j;
}
p = p->nextarc;
}
}
if (counts < G->n)//判断个数是否符合
{
cout << "error!";
}
else
{
for (i = 0; i < k; i++)
{
cout << node[i];
if (i != k - 1)
{
cout << " ";
}
}
}
}
1.6 关键路径
- AOE-网
AOV-网:用顶点表示事件,用有向边e表示活动,边的权c(e)表示活动持续时间。是带权的有向无环图。
AOE-网是在AOV-网的基础上,其中每一个边都具有各自的权值,是一个带权的有向无环网。 - 关键路径概念
整个工程活动完成的时间为:从有向图的源点到汇点的最长路径。又叫关键路径。 - 关键活动
“关键活动”指的是:关键路径中的边。