本作品不可用于任何商业途径,仅供学习交流!!!
分析:
在某音乐网站热歌排行榜里面,随便点击一首歌曲,进入歌曲网页,打开浏览器的开发者工具,刷新网页,播放下歌曲,浏览器的抓包工具network抓包如下图:
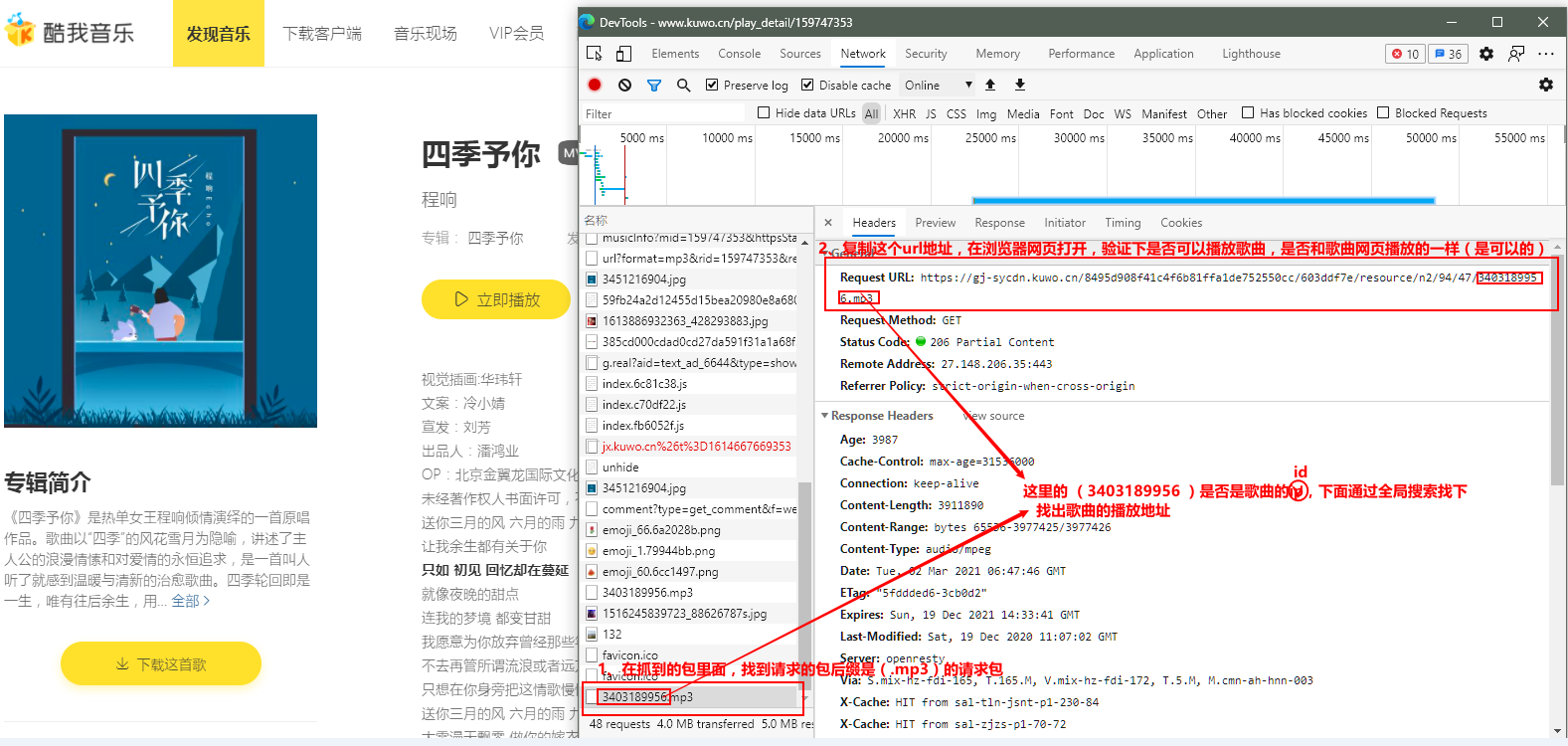

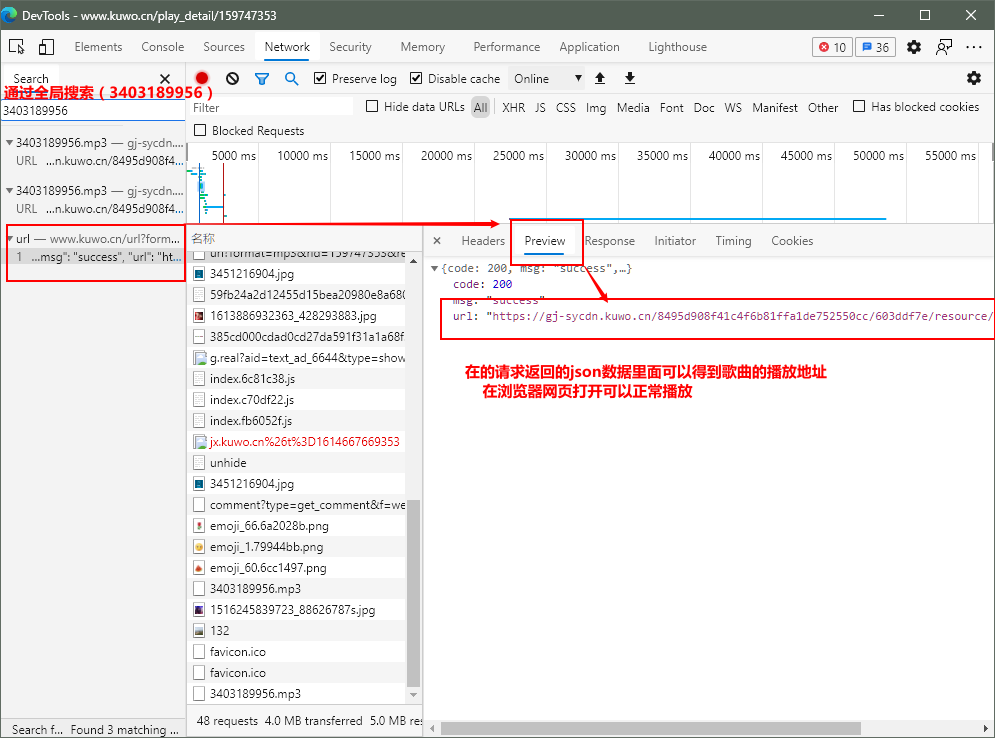

在某音乐网站热歌排行榜网页里面,打开浏览器的开发者工具,刷新网页,浏览器的抓包工具network抓包如下图:
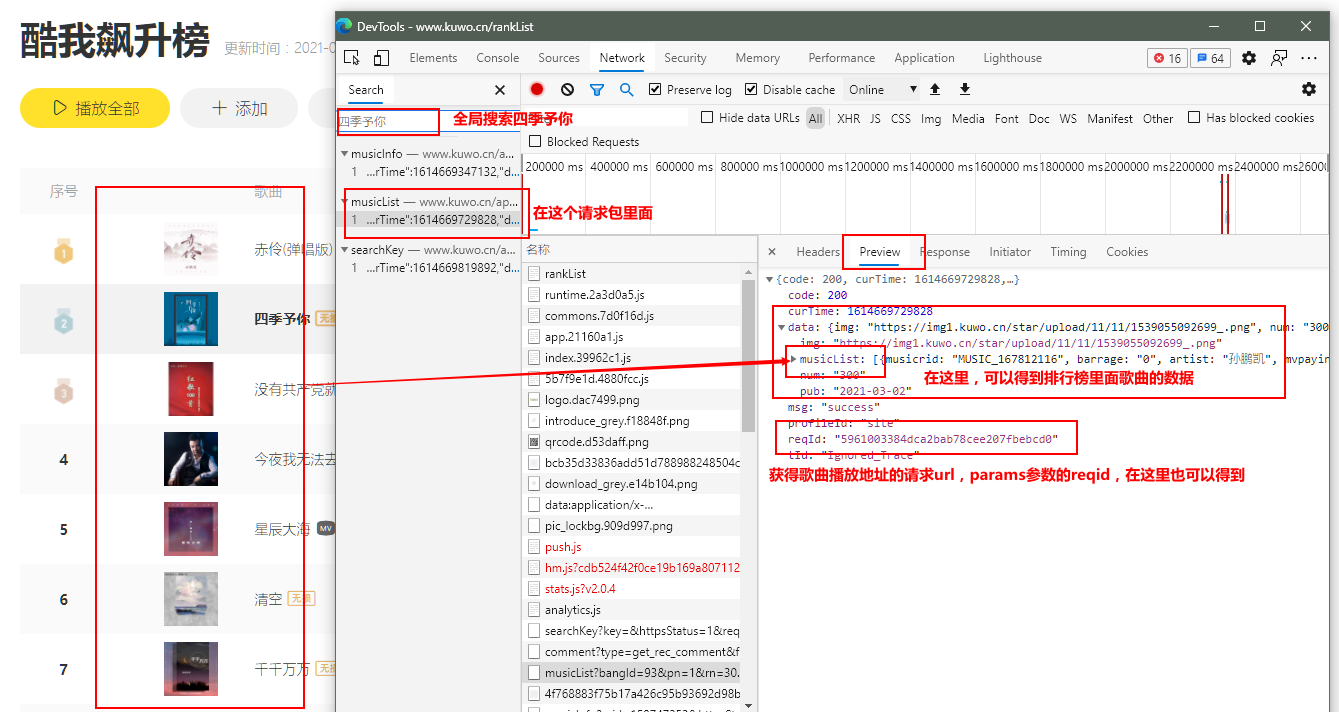
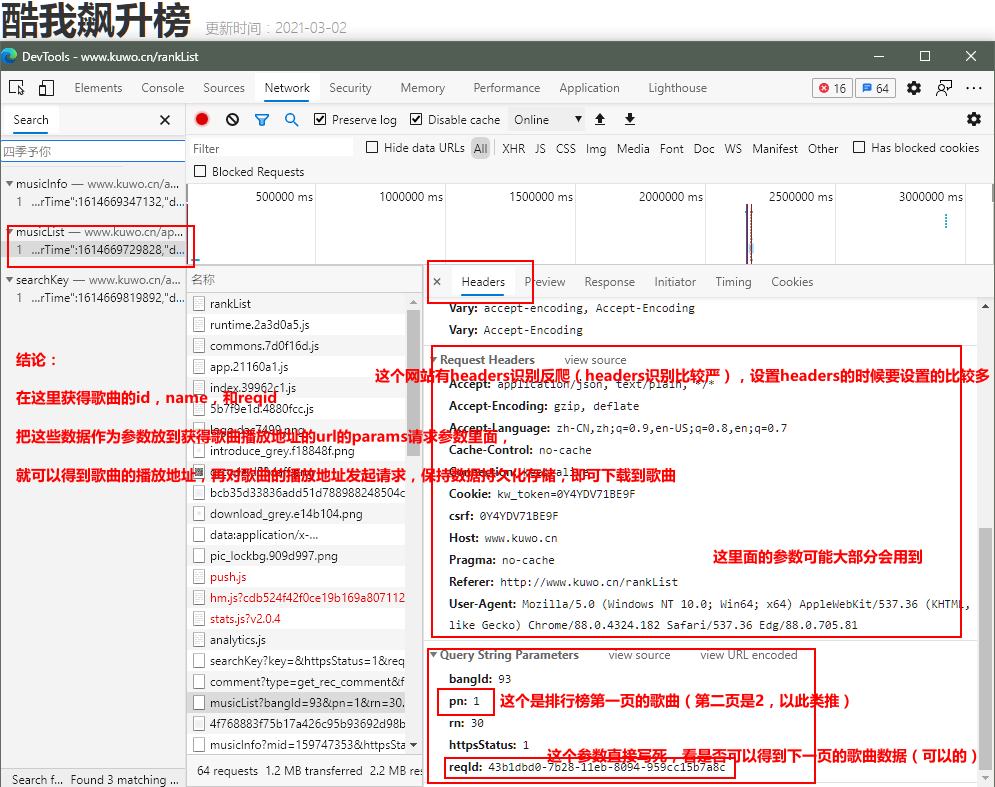
代码部分:
线程池:
from multiprocessing.dummy import Pool
pool.map(callback,alist) ---- 可以使用callback(回调函数)对alist中的每一个元素进行指定形式(回调函数)的异步操作!
抓取到网站排行榜里面歌曲的id和name
import os
import requests,time
from multiprocessing.dummy import Pool#需要用到的包
dirName = 'musickw'
if not os.path.exists(dirName):
os.mkdir(dirName)#设置保存下载歌曲的文件夹
headers = {
'csrf': 'BMULNZWEZ3B',
'Cookie': 'kw_token=BMULNZWEZ3B',
'Referer': 'http://www.kuwo.cn/rankList',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.52',
}#伪装成浏览器,要是headers设置上面这些还报错,再加其他的进去
music_list = []#抓取排行榜前4页歌曲的id,name放在这个music_list列表里面
for page in range(1,4):#抓取排行榜前4页歌曲的id,name
params = {
'bangId': '93',
'pn': str(page),
'rn': '30',
'httpsStatus': '1',
'reqId': '04ae7fd0-79d2-11eb-97b6-f59160d5f14c',
}
session = requests.Session()#requests中sessiondcookie自动处理
id_url = '获取排行榜歌曲id和歌曲name的ajax请求url'
response_dic = session.get(url=id_url,headers=headers,params=params).json()
time.sleep(0.5)#设置个等待时间,避免网站检查到请求频繁被禁出错
reqId = response_dic['reqId']
for i in response_dic['data']['musicList']:
music_id = i['rid']
music_name = i['name']
info_dic = {
'id':music_id,
'name':music_name,
'reqId':reqId,
}
music_list.append(info_dic)#上面是数据定位提取,放在个字典里面,然后把歌曲的id、name以字典的形式放在music_list列表里面
第一个 pool.map(callback,alist) 获取到歌曲的播放地址:
import os
import requests,time
from multiprocessing.dummy import Pool#需要用到的包
dirName = 'musickw'
if not os.path.exists(dirName):
os.mkdir(dirName)#设置保存下载歌曲的文件夹
headers = {
'csrf': 'BMULNZWEZ3B',
'Cookie': 'kw_token=BMULNZWEZ3B',
'Referer': 'http://www.kuwo.cn/rankList',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.52',
}#伪装成浏览器,要是headers设置上面这些还报错,再加其他的进去
music_list = []#抓取排行榜前4页歌曲的id,name放在这个music_list列表里面
for page in range(1,4):#抓取排行榜前4页歌曲的id,name
params = {
'bangId': '93',
'pn': str(page),
'rn': '30',
'httpsStatus': '1',
'reqId': '04ae7fd0-79d2-11eb-97b6-f59160d5f14c',
}
session = requests.Session()#requests中sessiondcookie自动处理
id_url = '获取排行榜歌曲id和歌曲name的ajax请求url'
response_dic = session.get(url=id_url,headers=headers,params=params).json()
time.sleep(0.5)#设置个等待时间,避免网站检查到请求频繁被禁出错
reqId = response_dic['reqId']
for i in response_dic['data']['musicList']:
music_id = i['rid']
music_name = i['name']
info_dic = {
'id':music_id,
'name':music_name,
'reqId':reqId,
}
music_list.append(info_dic)#上面是数据定位提取,放在个字典里面,然后把歌曲的id、name以字典的形式放在music_list列表里面
def get_musicUrl(music_list):
headers = {
'csrf': 'BMULNZWEZ3B',
'Cookie': 'kw_token=BMULNZWEZ3B',
'Referer': 'http://www.kuwo.cn/rankList',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.52',
}
reqId = music_list['reqId']
music_id = music_list['id']
music_name = music_list['name']#把music_list列表里面字典,字典里面的歌曲id、name、reqId提取出来,作为下面params的参数
params = {
'format': 'mp3',
'rid': music_id,
'response': 'url',
'type': 'convert_url3',
'br': '128kmp3',
'from': 'web',
't': str(int(round(time.time() * 1000))),#当前的时间戳
'httpsStatus': '1',
'reqId': reqId,
}
music_url = '获取到歌曲播放地址的ajax请求url'
try:
response_music_url = session.get(url=music_url, headers=headers, params=params).json()['url']
time.sleep(1)#设置个等待时间,避免网站检查到请求频繁被禁出错
info_dic = {
'url':response_music_url,
'name':music_name,
}
return info_dic #把获取到的歌曲播放地址和name封装到字典里面作为回调函数的返回值
except:#处理异常报错
response_music_url = session.get(url=music_url, headers=headers, params=params).json()['url']
info_dic = {
'url': response_music_url,
'name': music_name,
}
return info_dic
if __name__ == '__main__':
pool = Pool(10)
music_url = pool.map(get_musicUrl,music_list)#返回的是歌曲的播放地址和name的字典
pool.close()
pool.join()
第二个 pool.map(callback,alist) 对获取到的歌曲播放地址发起请求:
import os
import requests,time
from multiprocessing.dummy import Pool#需要用到的包
dirName = 'musickw'
if not os.path.exists(dirName):
os.mkdir(dirName)#设置保存下载歌曲的文件夹
headers = {
'csrf': 'BMULNZWEZ3B',
'Cookie': 'kw_token=BMULNZWEZ3B',
'Referer': 'http://www.kuwo.cn/rankList',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.52',
}#伪装成浏览器,要是headers设置上面这些还报错,再加其他的进去
music_list = []#抓取排行榜前4页歌曲的id,name放在这个music_list列表里面
for page in range(1,4):#抓取排行榜前4页歌曲的id,name
params = {
'bangId': '93',
'pn': str(page),
'rn': '30',
'httpsStatus': '1',
'reqId': '04ae7fd0-79d2-11eb-97b6-f59160d5f14c',
}
session = requests.Session()#requests中sessiondcookie自动处理
id_url = '获取排行榜歌曲id和歌曲name的ajax请求url'
response_dic = session.get(url=id_url,headers=headers,params=params).json()
time.sleep(0.5)#设置个等待时间,避免网站检查到请求频繁被禁出错
reqId = response_dic['reqId']
for i in response_dic['data']['musicList']:
music_id = i['rid']
music_name = i['name']
info_dic = {
'id':music_id,
'name':music_name,
'reqId':reqId,
}
music_list.append(info_dic)#上面是数据定位提取,放在个字典里面,然后把歌曲的id、name以字典的形式放在music_list列表里面
def get_musicUrl(music_list):
headers = {
'csrf': 'BMULNZWEZ3B',
'Cookie': 'kw_token=BMULNZWEZ3B',
'Referer': 'http://www.kuwo.cn/rankList',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.52',
}
reqId = music_list['reqId']
music_id = music_list['id']
music_name = music_list['name']#把music_list列表里面字典,字典里面的歌曲id、name、reqId提取出来,作为下面params的参数
params = {
'format': 'mp3',
'rid': music_id,
'response': 'url',
'type': 'convert_url3',
'br': '128kmp3',
'from': 'web',
't': str(int(round(time.time() * 1000))),#当前的时间戳
'httpsStatus': '1',
'reqId': reqId,
}
music_url = '获取到歌曲播放地址的ajax请求url'
try:
response_music_url = session.get(url=music_url, headers=headers, params=params).json()['url']
time.sleep(1)#设置个等待时间,避免网站检查到请求频繁被禁出错
info_dic = {
'url':response_music_url,
'name':music_name,
}
return info_dic #把获取到的歌曲播放地址和name封装到字典里面作为回调函数的返回值
except:#处理异常报错
response_music_url = session.get(url=music_url, headers=headers, params=params).json()['url']
info_dic = {
'url': response_music_url,
'name': music_name,
}
return info_dic
def get_music_content(url_dic):对获取到的歌曲播放地址发起请求
headers = {
'csrf': 'BMULNZWEZ3B',
'Cookie': 'kw_token=BMULNZWEZ3B',
'Referer': 'http://www.kuwo.cn/rankList',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.52',
}
url = url_dic['url']
name = url_dic['name'] #字典里面的歌曲播放地址 、name、提取出来
# music_name = name +'.mp3'
print(time.strftime("%y-%m-%d %H:%M:%S"),':正在下载music:{} ......'.format(name))
music_data = session.get(url=url,headers=headers).content #对歌曲播放地址发起请求
info_dic = {
'content':music_data,
'name':name,
}
return info_dic #把请求获取到的歌曲二进制数据和name封装到字典里面作为回调函数的返回值
if __name__ == '__main__':
pool = Pool(10)
music_url = pool.map(get_musicUrl,music_list)#返回的是歌曲的播放地址和name的字典
music_content = pool.map(get_music_content,music_url)#返回的是歌曲的二进制数据和name的字典
pool.close()
pool.join()
第三个 pool.map(callback,alist) 对获取到的歌曲二进制数据和name持久化存储(全部代码):
import os
import requests,time
from multiprocessing.dummy import Pool#需要用到的包
dirName = 'musickw'
if not os.path.exists(dirName):
os.mkdir(dirName)#设置保存下载歌曲的文件夹
headers = {
'csrf': 'BMULNZWEZ3B',
'Cookie': 'kw_token=BMULNZWEZ3B',
'Referer': 'http://www.kuwo.cn/rankList',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.52',
}#伪装成浏览器,要是headers设置上面这些还报错,再加其他的进去
music_list = []#抓取排行榜前4页歌曲的id,name放在这个music_list列表里面
for page in range(1,4):#抓取排行榜前4页歌曲的id,name
params = {
'bangId': '93',
'pn': str(page),
'rn': '30',
'httpsStatus': '1',
'reqId': '04ae7fd0-79d2-11eb-97b6-f59160d5f14c',
}
session = requests.Session()#requests中sessiondcookie自动处理
id_url = '获取排行榜歌曲id和歌曲name的ajax请求url'
response_dic = session.get(url=id_url,headers=headers,params=params).json()
time.sleep(0.5)#设置个等待时间,避免网站检查到请求频繁被禁出错
reqId = response_dic['reqId']
for i in response_dic['data']['musicList']:
music_id = i['rid']
music_name = i['name']
info_dic = {
'id':music_id,
'name':music_name,
'reqId':reqId,
}
music_list.append(info_dic)#上面是数据定位提取,放在个字典里面,然后把歌曲的id、name以字典的形式放在music_list列表里面
def get_musicUrl(music_list):
headers = {
'csrf': 'BMULNZWEZ3B',
'Cookie': 'kw_token=BMULNZWEZ3B',
'Referer': 'http://www.kuwo.cn/rankList',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.52',
}
reqId = music_list['reqId']
music_id = music_list['id']
music_name = music_list['name']#把music_list列表里面字典,字典里面的歌曲id、name、reqId提取出来,作为下面params的参数
params = {
'format': 'mp3',
'rid': music_id,
'response': 'url',
'type': 'convert_url3',
'br': '128kmp3',
'from': 'web',
't': str(int(round(time.time() * 1000))),#当前的时间戳
'httpsStatus': '1',
'reqId': reqId,
}
music_url = '获取到歌曲播放地址的ajax请求url'
try:
response_music_url = session.get(url=music_url, headers=headers, params=params).json()['url']
time.sleep(1)#设置个等待时间,避免网站检查到请求频繁被禁出错
info_dic = {
'url':response_music_url,
'name':music_name,
}
return info_dic #把获取到的歌曲播放地址和name封装到字典里面作为回调函数的返回值
except:#处理异常报错
response_music_url = session.get(url=music_url, headers=headers, params=params).json()['url']
info_dic = {
'url': response_music_url,
'name': music_name,
}
return info_dic
def get_music_content(url_dic):对获取到的歌曲播放地址发起请求
headers = {
'csrf': 'BMULNZWEZ3B',
'Cookie': 'kw_token=BMULNZWEZ3B',
'Referer': 'http://www.kuwo.cn/rankList',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.52',
}
url = url_dic['url']
name = url_dic['name'] #字典里面的歌曲播放地址 、name、提取出来
# music_name = name +'.mp3'
print(time.strftime("%y-%m-%d %H:%M:%S"),':正在下载music:{} ......'.format(name))
music_data = session.get(url=url,headers=headers).content #对歌曲播放地址发起请求
info_dic = {
'content':music_data,
'name':name,
}
return info_dic #把请求获取到的歌曲二进制数据和name封装到字典里面作为回调函数的返回值
def get_music_mp3(content_dic):
content = content_dic['content']
name = content_dic['name'] #字典里面的歌曲播二进制数据 、name、提取出来
music_name = name + '.mp3'#保存格式
dirName = 'musickw'
fileName = dirName + '/' + music_name
with open(fileName,'wb') as fp:
fp.write(content)
print(time.strftime("%y-%m-%d %H:%M:%S"),': music: {} 下载成功 !!!'.format(name))
if __name__ == '__main__':
pool = Pool(10)
music_url = pool.map(get_musicUrl,music_list)#返回的是歌曲的播放地址和name的字典,把返回参数music_url 给下一个pool.map()作为里面的alist
music_content = pool.map(get_music_content,music_url)#返回的是歌曲的二进制数据和name的字典
pool.map(get_music_mp3,music_content)#最后一个pool.map()可以没有返回
pool.close()#关闭线程池
pool.join()
ok,这样就完成了! 下面是效果图:

本作品不可用于任何商业途径,仅供学习交流!!!