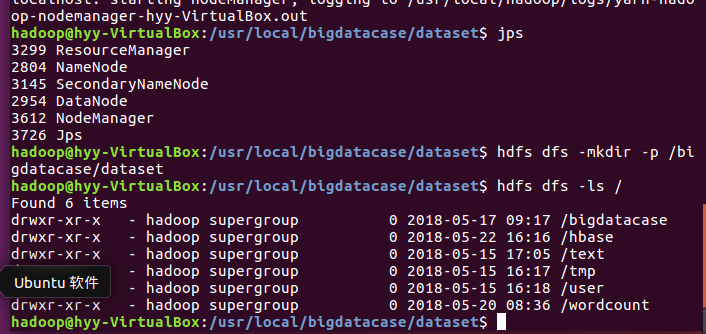
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
解析:因为上一次我的大作业是对电影的爬取,爬出来的文档有些是英语也有些是中文,又因为生成的文档是中文甚至过于庞大,所以这一次的大作业我就下载了几个《简爱》英语版小说的几个章节,文档也是足够大了,有的文档内容太多,所以在我截图中就省略了中间的一部分截图。
实验步骤:
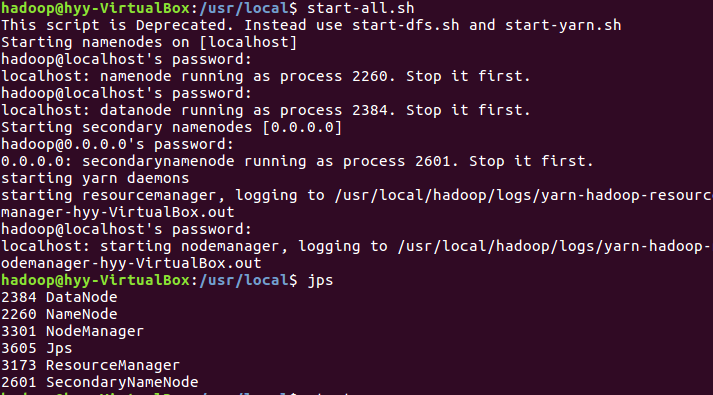
(1)首先启动所有项(以防万一):
usr/local$ start-all.sh
(2)在我的计算机本目录下创建一个english文档并把数据导入:



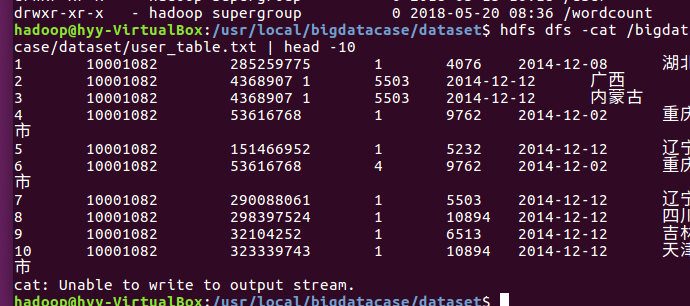
(3)启动hive并创建表和把数据导进hive来:

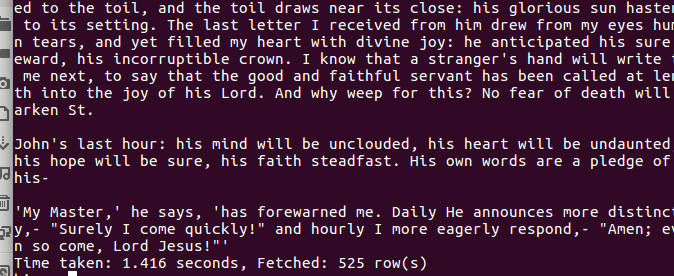
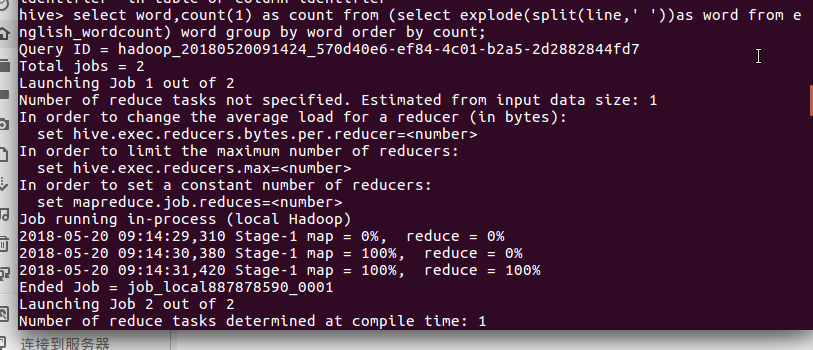

(4)最后把前面和后面的词频统计出来的结果以截图方式展现出来:
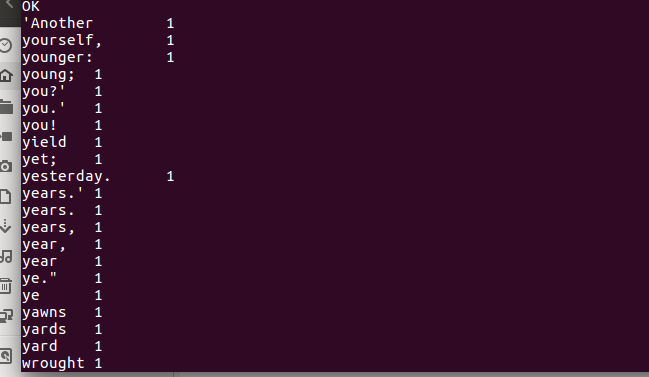
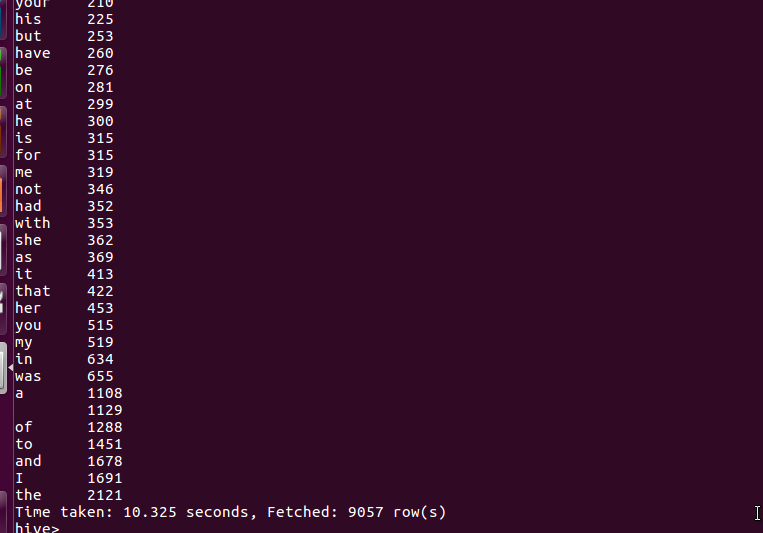
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
分析:在生成一个csv文件时由于文件过大,导致导入数据时虚拟机经常出现卡顿的情况,甚至有时候还出现黑屏,导致什么也干不了。后来想放弃不用那么大的文档来测试,还好没有选择放弃。后面修改了系统的存储空间以及在不断的调试下,终于能把一个几章节的文档英语单词统计了出来。详细的分析结果在上面有介绍。