set接口常用方法

注意
- 添加的顺序和取出的顺序不一致,但取出的顺序是固定的,第二次取得和第一次取得一样
- set中不允许有重复值,但可以有null
hashSet源码解读:
1)底层其实是hashmap来实现

2)添加的时候add的真正含义,源码解读

分析HashSet的添加元素底层是如何实现(hash()+equals())
先说结论:
1)HashSet的底层是一个HashMap
2)添加一个元素的时候,会先得到hash值->转化成索引值
3)找到存储数据表,看这个索引位置是否已经存放的有元素
4)如果没有,直接加入
5)如果有,调用equals比较 (String比较的是内容,不同类实现不同),如果相同,就放弃添加,如果不相同,则添加到最后
6)在Java8中,如果一条链表的元素个数到达TREEIFY_THRESHOLD(默认是8)【树化条件1】,并且table的大小 >= MIN_TREEIFY_CAPCITY(默认64)【树化条件2】,就会进化成红黑树

案例追踪源码
代码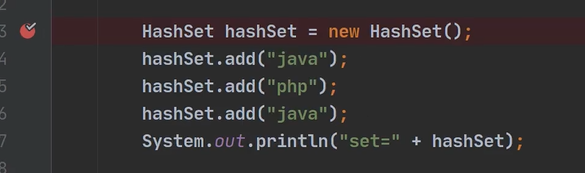
1)执行HashSet
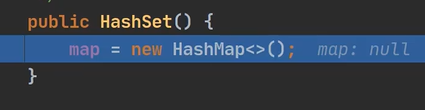
2)进入add方法
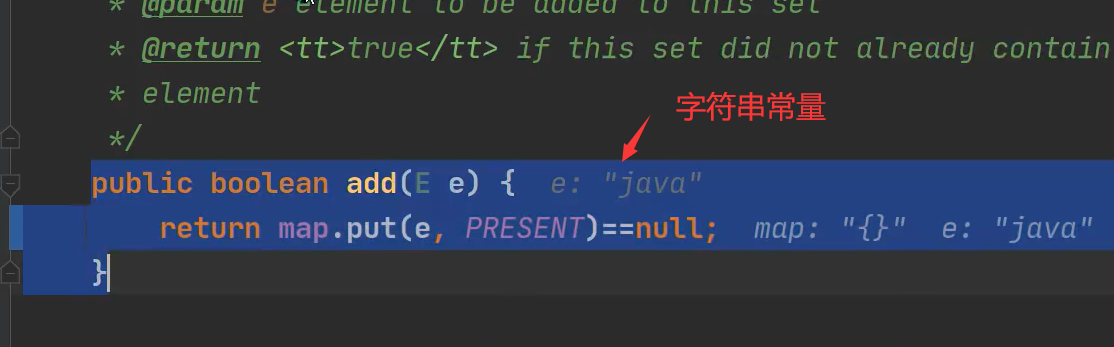
3)执行put方法
key不管怎么变化,value都是固定不变的
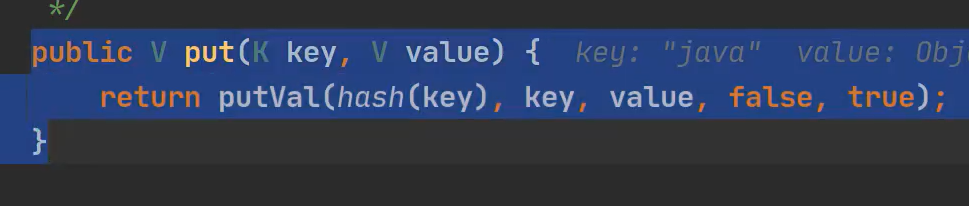
value 是2中的PRESENT

hash(key)方法

4)执行putVal方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
HashMap.Node[] tab; // 辅助结点
int n;
// table是hashmap中的一个数组,类型是node[]
// if 语句表示如果当前table是空或者大小=0
// 第一次扩容到16
if ((tab = this.table) == null || (n = tab.length) == 0) {
n = (tab = this.resize()).length;
// resize()函数解读


// newThr 是临界值,到12的时候我们就要进行扩容了。而不是傻傻的等到16
}
Object p;
int i;
// 1)根据key,得到hash,去计算该key应该存到table表的哪个索引位置
// 并把这个对象赋给p
// 2)判断p 是否为null
// 2.1)如果p为null,表示还没有存放过元素,就创建一个node(key="java",value=PRESENT)
// 2.2)就放在该位置tab[i] = this.newNode(hash, key, value, (HashMap.Node)null);
if ((p = tab[i = n - 1 & hash]) == null) {
// 传进来hash,为了和下一个传进来的对比,如果相等,往后走
tab[i] = this.newNode(hash, key, value, (HashMap.Node)null);
} else {
Object e;
Object k;
if (((HashMap.Node)p).hash == hash && ((k = ((HashMap.Node)p).key) == key || key != null && key.equals(k))) {
e = p;
} else if (p instanceof HashMap.TreeNode) {
e = ((HashMap.TreeNode)p).putTreeVal(this, tab, hash, key, value);
} else {
int binCount = 0;
while(true) {
if ((e = ((HashMap.Node)p).next) == null) {
((HashMap.Node)p).next = this.newNode(hash, key, value, (HashMap.Node)null);
if (binCount >= 7) {
this.treeifyBin(tab, hash);
}
break;
}
if (((HashMap.Node)e).hash == hash && ((k = ((HashMap.Node)e).key) == key || key != null && key.equals(k))) {
break;
}
p = e;
++binCount;
}
}
if (e != null) {
V oldValue = ((HashMap.Node)e).value;
if (!onlyIfAbsent || oldValue == null) {
((HashMap.Node)e).value = value;
}
this.afterNodeAccess((HashMap.Node)e);
return oldValue;
}
}
++this.modCount;
// 判断当前数据是否大于12,如果大于12,再扩容
if (++this.size > this.threshold) {
this.resize();
}
// 这个是hashMap留给子类的一个空函数,为了让子类能有更多实现
this.afterNodeInsertion(evict);
// 返回null 代表add成功
return null;
}
第二次的添加php同上
第三次添加相同java走的源码:
// 此时3的位置已经有java了
if ((p = tab[i = n - 1 & hash]) == null) {
tab[i] = this.newNode(hash, key, value, (HashMap.Node)null);
} else { // 走这里
Object e;
Object k;
// 下面的p
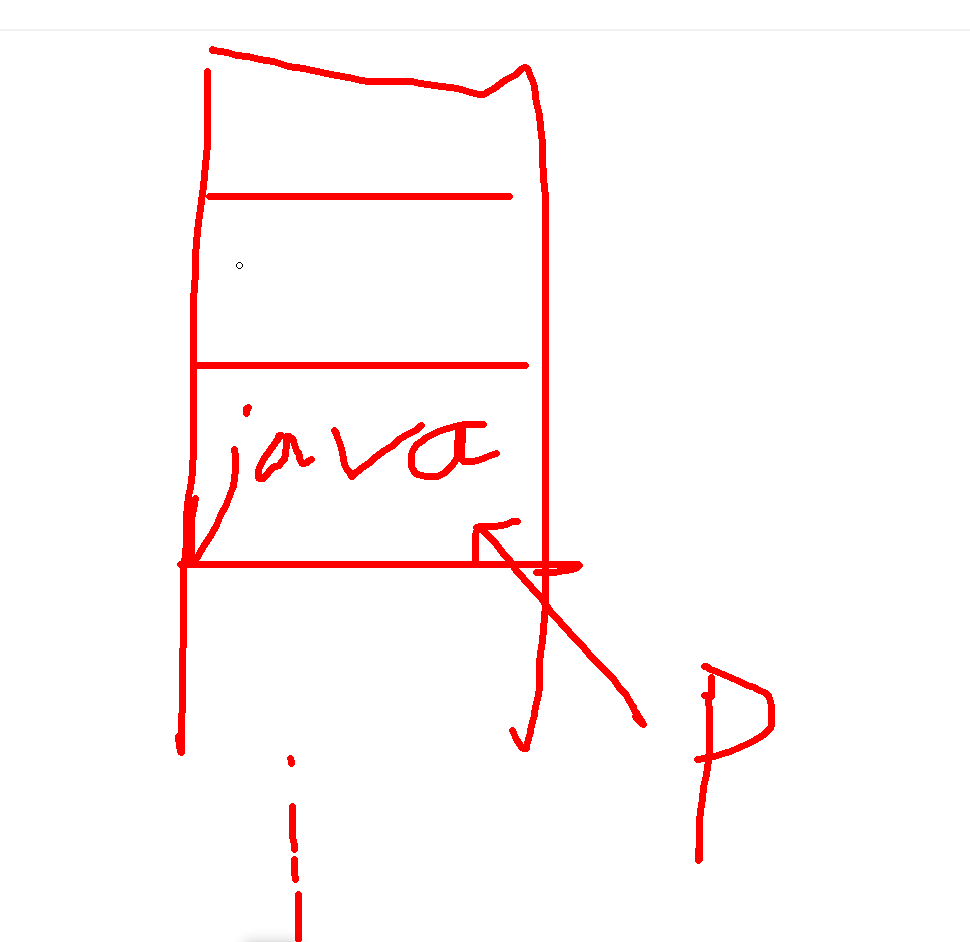
// 如果当前索引位置对应链表的第一个元素和准备添加的key的hash值一样
// 并且满足下面两个条件之一
// 1)准备加入的key和p指向的node结点的key是同一个对象
// 2)p指向的node结点的key的equals()和准备加入的key比较后相同(eauals()重写是程序员自己决定的)
// 就不能加入
if (((HashMap.Node)p).hash == hash &&
((k = ((HashMap.Node)p).key) == key || key != null && key.equals(k))) {
e = p;
}
// 再判断p是不是一颗红黑树
// 如果是一颗红黑树,就调用putTreeVal(),来进行添加
else if (p instanceof HashMap.TreeNode) {
e = ((HashMap.TreeNode)p).putTreeVal(this, tab, hash, key, value);
// 如果table对应索引的位置,已经是一个链表,就使用while循环比较
// 1)依次和该链表的每一个元素比较后,都不相同,则加入到链表的最后
// 注意在把元素添加到链表后,立即判断,该链表是否已经达到8个结点
// 就调用treeifBin()对当前这个链表进行树化(转成红黑树)
// 注意,在转成红黑树的时候,要进行判断,判断条件如下
// if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPCITY(64))
// resize();
// 如果上面条件成立,先table扩容
// 只有上面条件不成立时,才转化成红黑树
// 2)依次和该链表的元素比较的过程中,如果有相同的,就直接break

} else {
int binCount = 0;
while(true) {
if ((e = ((HashMap.Node)p).next) == null) { // 为空
((HashMap.Node)p).next = this.newNode(hash, key, value, (HashMap.Node)null);
if (binCount >= 7) {
this.treeifyBin(tab, hash); // 直接扔进去
}
break;
}
if (((HashMap.Node)e).hash == hash // 如果不为空,比较要加入的和当前存在链表中的结点是否相同
&& ((k = ((HashMap.Node)e).key) == key || key != null && key.equals(k))) {
break;
}
p = e;
++binCount;
}
}
// 上面代码p和e的解读

if (e != null) {
V oldValue = ((HashMap.Node)e).value;
if (!onlyIfAbsent || oldValue == null) {
((HashMap.Node)e).value = value;
}
this.afterNodeAccess((HashMap.Node)e);
return oldValue;
}
}