一、初识DRF
Django REST framework是基于Django实现的一个RESTful风格API框架,能够帮助我们快速开发RESTful风格的API。
二、初试DRF
1:下载并在setting中注册djangorestframework
pip install djangorestframework


INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'APP01.apps.App01Config', 'rest_framework', ]
2:配置路由
"""BookStore URL Configuration The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/3.0/topics/http/urls/ Examples: Function views 1. Add an import: from my_app import views 2. Add a URL to urlpatterns: path('', views.home, name='home') Class-based views 1. Add an import: from other_app.views import Home 2. Add a URL to urlpatterns: path('', Home.as_view(), name='home') Including another URLconf 1. Import the include() function: from django.urls import include, path 2. Add a URL to urlpatterns: path('blog/', include('blog.urls')) """ from django.contrib import admin from django.urls import path from django.conf.urls import url,include from APP01 import url as app01_books_url_v1 from APP01 import url2 as app01_books_url_v2 urlpatterns = [ url(r'^api/yango/v1/books/',include(app01_books_url_v1)), url(r'^api/yango/v2/', include(app01_books_url_v2)), ]
from django.conf.urls import url from . import views2 as views urlpatterns = [ ] # drf中的路由 from rest_framework.routers import DefaultRouter router = DefaultRouter() router.register(r'books', views.BookInfoModelViewSet, basename="books") urlpatterns += router.urls
3:views视图
from rest_framework import serializers from rest_framework.viewsets import ModelViewSet from .models import BookInfo # 1:定义序列化器(转换,校验) class BookInfoModelSerializer(serializers.ModelSerializer): class Meta: model=BookInfo fields="__all__" #2:视图集 class BookInfoModelViewSet(ModelViewSet): serializer_class = BookInfoModelSerializer queryset = BookInfo.objects.all()
4:测试
1)获取所有图书数据 http://127.0.0.1:8000/api/yango/v2/books/
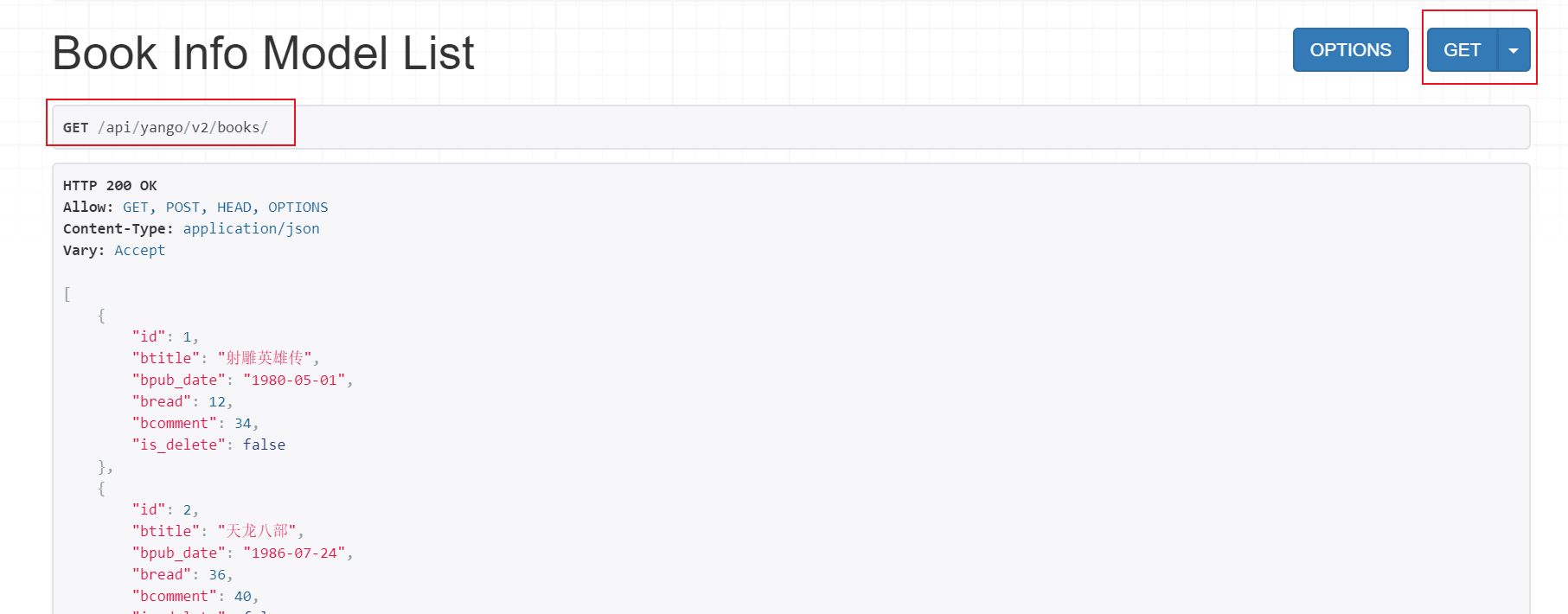
2)获取单一图书数据 http://127.0.0.1:8000/api/yango/v2/books/1
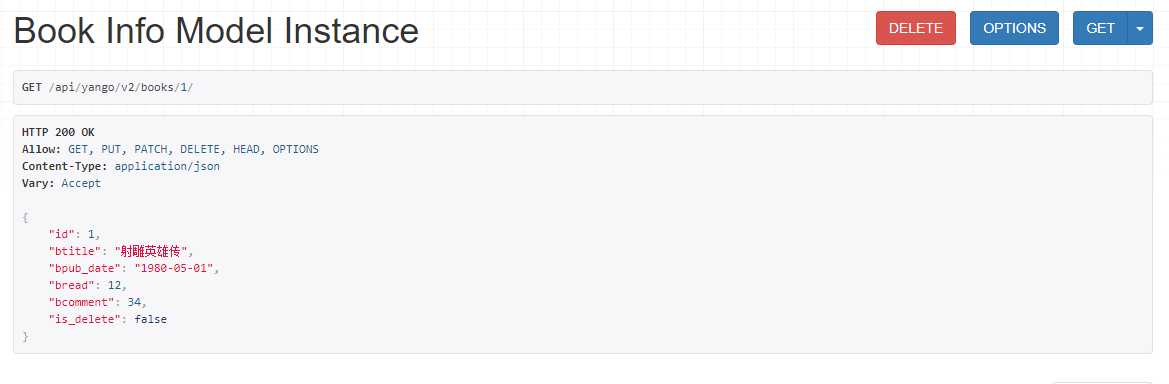
3)新增图书数据 http://127.0.0.1:8000/api/yango/v2/books/
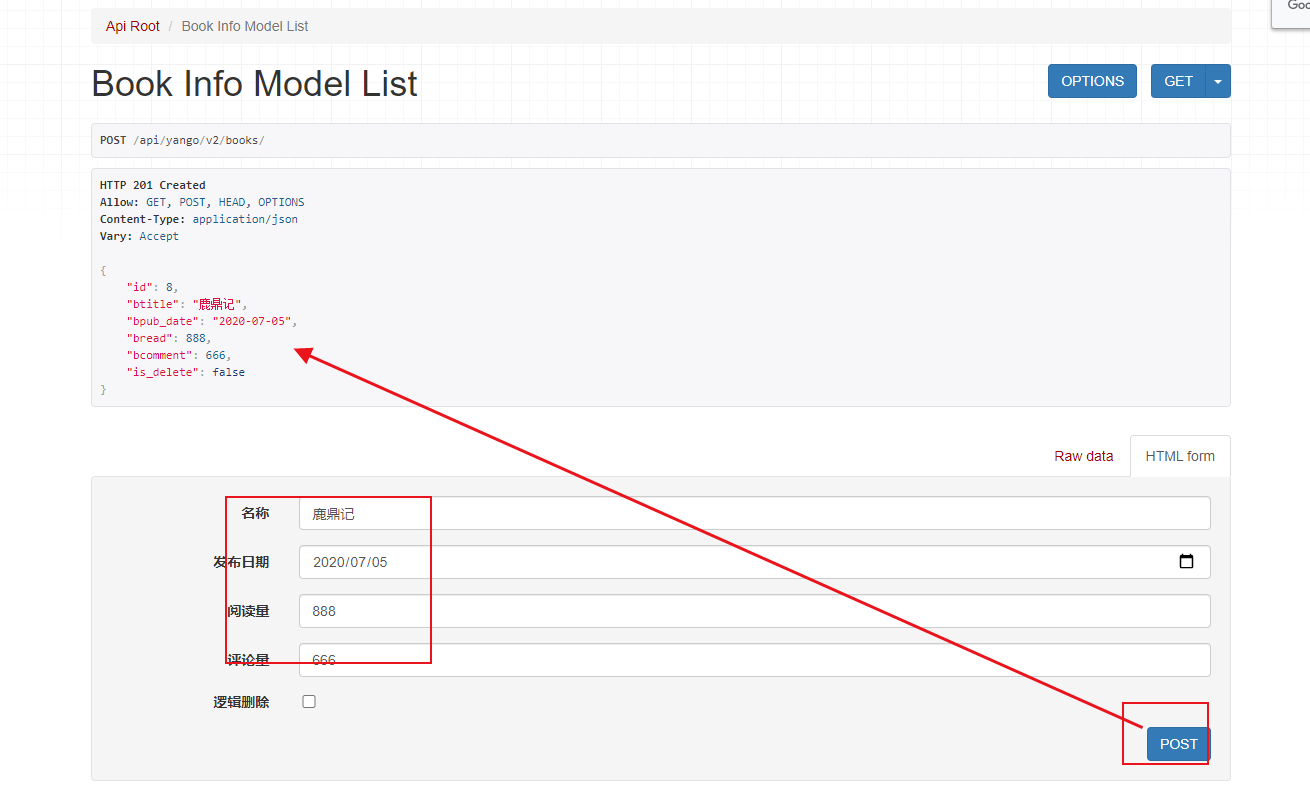
4)修改图书数据 http://127.0.0.1:8000/api/yango/v2/books/8/
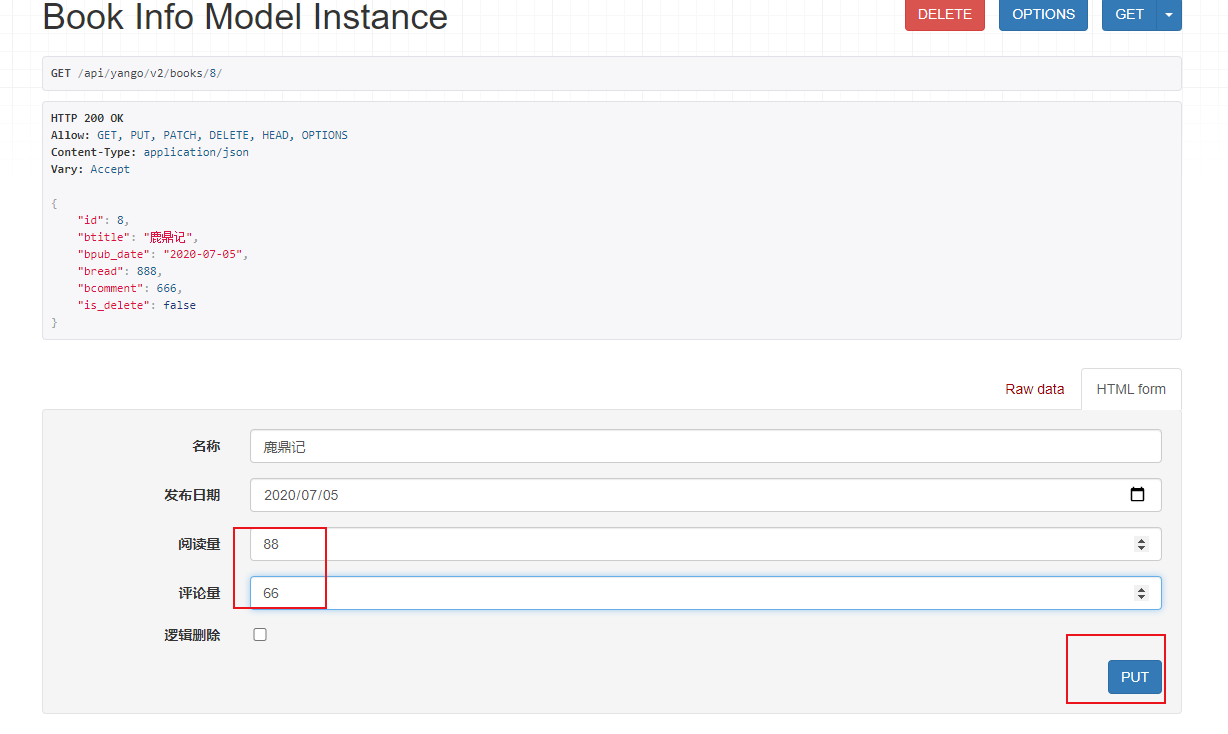
5)删除图书数据 http://127.0.0.1:8000/api/yango/v1/books/info/6/

三、初使DRF
1:序列化器
将程序中的一个数据结构类型转换为其他格式(字典、JSON、XML等),例如将Django中的模型类对象装换为JSON字符串,这个转换过程我们称为序列化。
反之,称为反序列化,例如将前端传递的Json转换成模型类的对象。
1.1 定义序列化器原则
-
- 与模型类【字段名】一致
- 与模型类【字段类型】一致
- 与模型列【字段选项】一致
1.2 定义序列化器
''' 定义序列化器 1:定义类,继承自Serializer 2:与模型类【字段名】一致: 3:与模型类【字段类型】一致: 4:与模型列【字段选项】一致 ''' from rest_framework import serializers # 1:定义书籍序列化器,继承自Serializer class BookInfoSerializer(serializers.Serializer): id=serializers.IntegerField(label="id",read_only=True) btitle =serializers.CharField(label='名称',max_length=20) bpub_date =serializers.DateField(label='发布日期') bread =serializers.IntegerField(label='阅读量',default=0) bcomment =serializers.IntegerField(label='评论量',default=0) is_delete =serializers.BooleanField(label='逻辑删除',default=False)
1.3 序列化器,序列化单个对象
from APP01.models import BookInfo,HeroInfo from APP01.Serializers import BookInfoSerializer,HeroInfoSerializer '''===================1,序列化器,序列化单个书籍====================''' #1:获取书籍对象 book = BookInfo.objects.get(id=1) #2:创建序列化器 serializer=BookInfoSerializer(instance=book) # instance=book 表示将book进行序列化 #3:转换数据 print(serializer.data) # 取到序列化的结果 #####{'id': 1, 'btitle': '射雕英雄传', 'bpub_date': '1980-05-01', 'bread': 12, 'bcomment': 34, 'is_delete': False}
{'id': 1, 'btitle': '射雕英雄传', 'bpub_date': '1980-05-01', 'bread': 12, 'bcomment': 34, 'is_delete': False}
1.4 序列化器,序列化列表对象
'''===================2,序列化器,序列化多个书籍====================''' # 1:获取书籍列表 book_list = BookInfo.objects.all() # 2:创建可以序列化列表的序列化器 serializer_list = BookInfoSerializer(instance=book_list,many=True) # 3:转换数据 print(serializer_list.data)
'''[
OrderedDict([('id', 1), ('btitle', '射雕英雄传'), ('bpub_date', '1980-05-01'), ('bread', 12), ('bcomment', 34), ('is_delete', False)]),
OrderedDict([('id', 2), ('btitle', '天龙八部'), ('bpub_date', '1986-07-24'), ('bread', 36), ('bcomment', 40), ('is_delete', False)]),
OrderedDict([('id', 3), ('btitle', '笑傲江湖'), ('bpub_date', '1995-12-24'), ('bread', 20), ('bcomment', 80), ('is_delete', False)]),
OrderedDict([('id', 4), ('btitle', '雪山飞狐'), ('bpub_date', '1987-11-11'), ('bread', 58), ('bcomment', 24), ('is_delete', False)]),
OrderedDict([('id', 5), ('btitle', '白马啸西风'), ('bpub_date', '2020-02-02'), ('bread', 0), ('bcomment', 0), ('is_delete', False)]),
OrderedDict([('id', 7), ('btitle', '连城诀'), ('bpub_date', '2020-02-02'), ('bread', 0), ('bcomment', 0), ('is_delete', False)])
]
'''
1.5 英雄序列化器,关联外键
''' 定义序列化器 1:定义类,继承自Serializer 2:与模型类【字段名】一致: 3:与模型类【字段类型】一致: 4:与模型列【字段选项】一致 ''' from rest_framework import serializers from APP01.models import BookInfo # 1:定义书籍序列化器,继承自Serializer class BookInfoSerializer(serializers.Serializer): id=serializers.IntegerField(label="id",read_only=True) btitle =serializers.CharField(label='名称',max_length=20) bpub_date =serializers.DateField(label='发布日期') bread =serializers.IntegerField(label='阅读量',default=0) bcomment =serializers.IntegerField(label='评论量',default=0) is_delete =serializers.BooleanField(label='逻辑删除',default=False) class HeroInfoSerializer(serializers.Serializer): """英雄数据序列化器""" GENDER_CHOICES = ( (0, 'male'), (1, 'female') ) id = serializers.IntegerField(label='ID', read_only=True) hname = serializers.CharField(label='名字', max_length=20) hgender = serializers.ChoiceField(choices=GENDER_CHOICES, label='性别', required=False) hcomment = serializers.CharField(label='描述信息', max_length=200, required=False, allow_null=True) # 1:关联书籍外键,read_only=True 表示只读(方式一) 【使用主表的主键作为展示字段】 hbook=serializers.PrimaryKeyRelatedField(read_only=True) # 关联书籍外键(方式二) 【使用主表的主键作为展示字段】 hbook=serializers.PrimaryKeyRelatedField(queryset=BookInfo.objects.all()) #2,关联书籍,使用模型类__str__方法返回值 【使用主表的str方法中内容作为展示字段】 hbook = serializers.StringRelatedField(read_only=True) #3,关联书籍序列化器 【使用主表的模型作为展示字段】 hbook=BookInfoSerializer()
'''===================3,序列化器,英雄通过外键关联书籍====================''' from APP01.models import BookInfo,HeroInfo from APP01.Serializers import BookInfoSerializer,HeroInfoSerializer #1:获取英雄对象 hero = HeroInfo.objects.get(id=1) #2:创建序列化器 heroserializer=HeroInfoSerializer(instance=hero) #3:转换数据 print(heroserializer.data) # 取到序列化的结果
{'id': 1, 'hname': '郭靖', 'hgender': 1, 'hcomment': '降龙十八掌', 'hbook':1}
#hbook=serializers.PrimaryKeyRelatedField(read_only=True)
{'id': 1, 'hname': '郭靖', 'hgender': 1, 'hcomment': '降龙十八掌', 'hbook': '射雕英雄传'}
# hbook=serializers.PrimaryKeyRelatedField(queryset=BookInfo.objects.all())
{'id': 1, 'hname': '郭靖', 'hgender': 1, 'hcomment': '降龙十八掌', 'hbook': '射雕英雄传'}
# hbook = serializers.StringRelatedField(read_only=True)
{'id': 1, 'hname': '郭靖', 'hgender': 1, 'hcomment': '降龙十八掌', 'hbook': OrderedDict([('id', 1), ('btitle', '射雕英雄传'), ('bpub_date', '1980-05-01'), ('bread', 12), ('bcomment', 34), ('is_delete', F
alse)])}
# hbook=BookInfoSerializer()
1.6 书籍序列化器,关联many
''' 定义序列化器 1:定义类,继承自Serializer 2:与模型类【字段名】一致: 3:与模型类【字段类型】一致: 4:与模型列【字段选项】一致 ''' from rest_framework import serializers from APP01.models import BookInfo class HeroInfoSerializer(serializers.Serializer): """英雄数据序列化器""" GENDER_CHOICES = ( (0, 'male'), (1, 'female') ) id = serializers.IntegerField(label='ID', read_only=True) hname = serializers.CharField(label='名字', max_length=20) hgender = serializers.ChoiceField(choices=GENDER_CHOICES, label='性别', required=False) hcomment = serializers.CharField(label='描述信息', max_length=200, required=False, allow_null=True) # 1:关联书籍外键,read_only=True 表示只读(方式一) 【使用主表的主键作为展示字段】 hbook = serializers.PrimaryKeyRelatedField(read_only=True) # 关联书籍外键(方式二) 【使用主表的主键作为展示字段】 hbook = serializers.PrimaryKeyRelatedField(queryset=BookInfo.objects.all()) # 2,关联书籍,使用模型类__str__方法返回值 【使用主表的str方法中内容作为展示字段】 hbook = serializers.StringRelatedField(read_only=True) # 3,关联书籍序列化器 【使用主表的模型作为展示字段】 # hbook = BookInfoSerializer() # 1:定义书籍序列化器,继承自Serializer class BookInfoSerializer(serializers.Serializer): id = serializers.IntegerField(label="id", read_only=True) btitle = serializers.CharField(label='名称', max_length=20) bpub_date = serializers.DateField(label='发布日期') bread = serializers.IntegerField(label='阅读量', default=0) bcomment = serializers.IntegerField(label='评论量', default=0) is_delete = serializers.BooleanField(label='逻辑删除', default=False) # 1:关联英雄,主键 heroinfo_set = serializers.PrimaryKeyRelatedField(read_only=True, many=True) # 2:关联英雄,str方法返回值 heroinfo_set = serializers.StringRelatedField(read_only=True, many=True) # 3:关联英雄,str方法返回值 heroinfo_set = HeroInfoSerializer(many=True)
'''===================序列化器,序列化一个书籍,中所有的英雄====================''' #1:获取书籍对象 book = BookInfo.objects.get(id=1) #2:创建序列化器 serializer=BookInfoSerializer(instance=book) # instance=book 表示将book进行序列化 #3:转换数据 print(serializer.data) # 取到序列化的结果
{'id': 1, 'btitle': '射雕英雄传', 'bpub_date': '1980-05-01', 'bread': 12, 'bcomment': 34, 'is_delete': False, 'heroinfo_set': [1, 2, 3, 4, 5]}
#heroinfo_set = serializers.PrimaryKeyRelatedField(read_only=True, many=True)
{'id': 1, 'btitle': '射雕英雄传', 'bpub_date': '1980-05-01', 'bread': 12, 'bcomment': 34, 'is_delete': False, 'heroinfo_set': ['郭靖', '黄蓉', '黄药师', '欧阳锋', '梅超风']}
#heroinfo_set = serializers.StringRelatedField(read_only=True, many=True)
{'id': 1, 'btitle': '射雕英雄传', 'bpub_date': '1980-05-01', 'bread': 12, 'bcomment': 34, 'is_delete': False, 'heroinfo_set': [OrderedDict([('id', 1), ('hname', '郭靖'), ('hgender', 1), ('hcomment', '降
龙十八掌'), ('hbook', '射雕英雄传')]), OrderedDict([('id', 2), ('hname', '黄蓉'), ('hgender', 0), ('hcomment', '打狗棍法'), ('hbook', '射雕英雄传')]), OrderedDict([('id', 3), ('hname', '黄药师'), ('hgend
er', 1), ('hcomment', '弹指神通'), ('hbook', '射雕英雄传')]), OrderedDict([('id', 4), ('hname', '欧阳锋'), ('hgender', 1), ('hcomment', '蛤蟆功'), ('hbook', '射雕英雄传')]), OrderedDict([('id', 5), ('hna
me', '梅超风'), ('hgender', 0), ('hcomment', '九阴白骨爪'), ('hbook', '射雕英雄传')])]}
#heroinfo_set = HeroInfoSerializer(many=True)
反序列化主要包括两部分:校验和入库
1.7 校验
- 校验【字段类型】
- 校验【字段选项】
- 校验【单字段】
- 校验【多字段】
- 校验【自定义】
1.7.1 校验【字段类型】
主要校验字段的类型与传递的值是否一致。eg:字段类型是IntegerField,如果传递过来的是字符串,就会报错
常见的字段类型有:
- IntegerField,整数
- CharField,字符串
- DateField,日期
- BooleanField 布尔值
1.7.2 校验【字段选项】
主要校验字段的选项与传递的值是否一致。eg:字段选项是max_length=20,如果传递过来的是字符串超过20个长度,就会报错
常见的字段选项有:
- max_length,最大长度
- min_length,最小长度
- required,默认为True,必须传递,除非设置了default | false | read_only
- read_only,只读,只序列化,不进行反序列化
1.7.3 校验【单字段】
主要是对某个字段进行校验。eg:题目中不能含有中文逗号。
# 【单字段】校验 :题目(btitle)中不能含有中文逗号
def validate_XXX(self, value):
'''业务逻辑'''
if True:
raise serializers.ValidationError("错误信息")
return value
# 【单字段】校验 :题目(btitle)中不能含有中文逗号 def validate_btitle(self, value): '''业务逻辑''' if "," in value: raise serializers.ValidationError("书籍题目中不能含有,") return value
1.7.4 校验【多字段】
主要是对两两与两两字段之间进行比较。eg:验证码是否正确,两次输入密码是否一致
# 【多字段】校验
def validate(self, attrs):
'''
:param attrs: 外界传递过来的字典数据
:return:
'''
# 1:获取字段
XX1=attrs["XX1"]
XX2=attrs["XX2"]
if XX1!=XX2:
raise serializers.ValidationError("错误信息")
return attrs
# 【多字段】校验 :评论量不能大于阅读量 def validate(self, attrs): ''' :param attrs: 外界传递过来的字典数据 :return: ''' # 1:获取字段 bread=attrs["bread"] bcomment=attrs["bcomment"] if bread<bcomment: raise serializers.ValidationError("评论量不能大于阅读量!") return attrs
1.7.5 校验【自定义方法】
主要是自定义一些规则和单字段校验类似。eg:书籍出版日期必须大于1949年
# 【自定义】校验 :
def XXX(self, value):
'''业务逻辑'''
if True:
raise serializers.ValidationError("错误信息")
return value
注意定义数据字段的时候需要添加 validators
bpub_date = serializers.DateField(label='发布日期',validators=[XXX])
def check_bpub_date(value): if value.year < 1949: raise serializers.ValidationError("书籍出版年份要大于1949年!") return value # 1:定义书籍序列化器,继承自Serializer class BookInfoSerializer(serializers.Serializer): id = serializers.IntegerField(label="id", read_only=True) btitle = serializers.CharField(label='名称', max_length=20, ) bpub_date = serializers.DateField(label='发布日期', validators=[check_bpub_date]) bread = serializers.IntegerField(label='阅读量', default=0) bcomment = serializers.IntegerField(label='评论量', default=0) is_delete = serializers.BooleanField(label='逻辑删除', default=False) # 1:关联英雄,主键 # heroinfo_set = serializers.PrimaryKeyRelatedField(read_only=True, many=True) # # 2:关联英雄,str方法返回值 # heroinfo_set = serializers.StringRelatedField(read_only=True, many=True) # 3:关联英雄,str方法返回值 # heroinfo_set = HeroInfoSerializer(many=True) # 【单字段】校验 :题目(btitle)中不能含有中文逗号 def validate_btitle(self, value): '''业务逻辑''' if "," in value: raise serializers.ValidationError("书籍题目中不能含有,") return value # 【多字段】校验 :评论量不能大于阅读量 def validate(self, attrs): ''' :param attrs: 外界传递过来的字典数据 :return: ''' # 1:获取字段 bread = attrs["bread"] bcomment = attrs["bcomment"] if bread < bcomment: raise serializers.ValidationError("评论量不能大于阅读量!") return attrs
1.8 入库
- create【新增数据】
- update【更新数据】
1.8.1 入库【新增数据】
- 必须在序列化器中实现create方法
- save()入库
def create(self, validated_data): ''' :param validated_data: 校验成功之后的数据 :return: ''' # 1:创建Book对象,设置属性 # 2:入库 book=BookInfo.objects.create(**validated_data) # 3:返回 return book
'''===================4,序列化器,反序列化,保存书籍====================''' from APP01.models import BookInfo,HeroInfo from APP01.Serializers import BookInfoSerializer,HeroInfoSerializer # 1:准备数据 book_dict={ "btitle": "鹿鼎记", "bpub_date": "2020-02-02", "bread": 10, "bcomment": 8 } # 2:创建序列化器 serializer=BookInfoSerializer(data=book_dict) # 3:校验 serializer.is_valid(raise_exception=True) # 4:入库 serializer.save()
1.8.2 入库【更新数据】
- 创建序列化器,必须同时实现序列化和反序列化(序列化:被更新的数据,反序列化 :新的数值)
- 示例
- 必须在序列化器中实现update方法
- save()入库
# 1:定义书籍序列化器,继承自Serializer class BookInfoSerializer(serializers.Serializer): id = serializers.IntegerField(label="id", read_only=True) btitle = serializers.CharField(label='名称', max_length=20, ) bpub_date = serializers.DateField(label='发布日期', validators=[check_bpub_date]) bread = serializers.IntegerField(label='阅读量', default=0) bcomment = serializers.IntegerField(label='评论量', default=0) is_delete = serializers.BooleanField(label='逻辑删除', default=False) # 1:关联英雄,主键 # heroinfo_set = serializers.PrimaryKeyRelatedField(read_only=True, many=True) # # 2:关联英雄,str方法返回值 # heroinfo_set = serializers.StringRelatedField(read_only=True, many=True) # 3:关联英雄,str方法返回值 # heroinfo_set = HeroInfoSerializer(many=True) # 【单字段】校验 :题目(btitle)中不能含有中文逗号 def validate_btitle(self, value): '''业务逻辑''' if "," in value: raise serializers.ValidationError("书籍题目中不能含有,") return value # 【多字段】校验 :评论量不能大于阅读量 def validate(self, attrs): ''' :param attrs: 外界传递过来的字典数据 :return: ''' # 1:获取字段 bread = attrs["bread"] bcomment = attrs["bcomment"] if bread < bcomment: raise serializers.ValidationError("评论量不能大于阅读量!") return attrs def create(self, validated_data): ''' :param validated_data: 校验成功之后的数据 :return: ''' # 1:创建Book对象,设置属性 # 2:入库 book = BookInfo.objects.create(**validated_data) # 3:返回 return book def update(self, instance, validated_data): ''' :param instance: 外结传入的book对象 :param validated_data:校验成功之后的book_dict数据 :return: ''' # 1,更新数据 instance.btitle = validated_data["btitle"] instance.bpub_date = validated_data["bpub_date"] instance.bread = validated_data["bread"] instance.bcomment = validated_data["bcomment"] instance.is_delete = validated_data["is_delete"] # 2,入库 instance.save() # 3,返回 return instance
'''===================6,序列化器,反序列化,更新书籍====================''' from APP01.models import BookInfo,HeroInfo from APP01.Serializers import BookInfoSerializer,HeroInfoSerializer # 1:准备数据 book_dict={ "btitle": "鹿鼎记", "bpub_date": "2020-02-02", "bread": 100, "bcomment": 88 } book=BookInfo.objects.get(id=9) # 2:创建序列化器 serializer=BookInfoSerializer(instance=book,data=book_dict) # 3:校验 serializer.is_valid(raise_exception=True) # 4:入库 serializer.save()
2:通过序列化器完善代码
2.1 路由配置
"""BookStore URL Configuration The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/3.0/topics/http/urls/ Examples: Function views 1. Add an import: from my_app import views 2. Add a URL to urlpatterns: path('', views.home, name='home') Class-based views 1. Add an import: from other_app.views import Home 2. Add a URL to urlpatterns: path('', Home.as_view(), name='home') Including another URLconf 1. Import the include() function: from django.urls import include, path 2. Add a URL to urlpatterns: path('blog/', include('blog.urls')) """ from django.contrib import admin from django.urls import path from django.conf.urls import url,include from APP01 import url as app01_books_url_v1 from APP01 import url2 as app01_books_url_v2 from APP01 import url3 as app01_books_url_v3 urlpatterns = [ url(r'^api/yango/v1/books/',include(app01_books_url_v1)), url(r'^api/yango/v2/', include(app01_books_url_v2)), url(r'^api/yango/v3/books/', include(app01_books_url_v3)), ]
from django.conf.urls import url from . import views urlpatterns = [ url(r'^info$', views.BooksAPIView.as_view()), url(r'^info/(?P<pk>d+)/$', views.BookAPIView.as_view()), ]
2.2 完整版序列化器
''' 定义序列化器 1:定义类,继承自Serializer 2:与模型类【字段名】一致: 3:与模型类【字段类型】一致: 4:与模型列【字段选项】一致 ''' from rest_framework import serializers from APP01.models import BookInfo def check_bpub_date(value): if value.year < 1949: raise serializers.ValidationError("书籍出版年份要大于1949年!") return value class HeroInfoSerializer(serializers.Serializer): """英雄数据序列化器""" GENDER_CHOICES = ( (0, 'male'), (1, 'female') ) id = serializers.IntegerField(label='ID', read_only=True) hname = serializers.CharField(label='名字', max_length=20) hgender = serializers.ChoiceField(choices=GENDER_CHOICES, label='性别', required=False) hcomment = serializers.CharField(label='描述信息', max_length=200, required=False, allow_null=True) # 1:关联书籍外键,read_only=True 表示只读(方式一) 【使用主表的主键作为展示字段】 # hbook = serializers.PrimaryKeyRelatedField(read_only=True) # # 关联书籍外键(方式二) 【使用主表的主键作为展示字段】 # hbook = serializers.PrimaryKeyRelatedField(queryset=BookInfo.objects.all()) # # # 2,关联书籍,使用模型类__str__方法返回值 【使用主表的str方法中内容作为展示字段】 # hbook = serializers.StringRelatedField(read_only=True) # 3,关联书籍序列化器 【使用主表的模型作为展示字段】 # hbook = BookInfoSerializer() # 1:定义书籍序列化器,继承自Serializer class BookInfoSerializer(serializers.Serializer): id = serializers.IntegerField(label="id", read_only=True) btitle = serializers.CharField(label='名称', max_length=20, ) bpub_date = serializers.DateField(label='发布日期', validators=[check_bpub_date]) bread = serializers.IntegerField(label='阅读量', default=0) bcomment = serializers.IntegerField(label='评论量', default=0) is_delete = serializers.BooleanField(label='逻辑删除', default=False) # 1:关联英雄,主键 # heroinfo_set = serializers.PrimaryKeyRelatedField(read_only=True, many=True) # # 2:关联英雄,str方法返回值 # heroinfo_set = serializers.StringRelatedField(read_only=True, many=True) # 3:关联英雄,str方法返回值 # heroinfo_set = HeroInfoSerializer(many=True) # 【单字段】校验 :题目(btitle)中不能含有中文逗号 def validate_btitle(self, value): '''业务逻辑''' if "," in value: raise serializers.ValidationError("书籍题目中不能含有,") return value # 【多字段】校验 :评论量不能大于阅读量 def validate(self, attrs): ''' :param attrs: 外界传递过来的字典数据 :return: ''' # 1:获取字段 bread = attrs["bread"] bcomment = attrs["bcomment"] if bread < bcomment: raise serializers.ValidationError("评论量不能大于阅读量!") return attrs def create(self, validated_data): ''' :param validated_data: 校验成功之后的数据 :return: ''' # 1:创建Book对象,设置属性 # 2:入库 book = BookInfo.objects.create(**validated_data) # 3:返回 return book def update(self, instance, validated_data): ''' :param instance: 外结传入的book对象 :param validated_data:校验成功之后的book_dict数据 :return: ''' # 1,更新数据 instance.btitle = validated_data["btitle"] instance.bpub_date = validated_data["bpub_date"] instance.bread = validated_data["bread"] instance.bcomment = validated_data["bcomment"] instance.is_delete = validated_data["is_delete"] # 2,入库 instance.save() # 3,返回 return instance
2.3 完整版视图
from APP01.models import BookInfo, HeroInfo from APP01.Serializers import BookInfoSerializer, HeroInfoSerializer from django.shortcuts import render, HttpResponse from django.views import View from datetime import datetime from django.http import JsonResponse import json ''' 功能 请求方式 请求路径 获取所有书籍 GET /books 创建单本书籍 POST /books 获取单本书籍 GET /books/{pk} 修改单本书籍 PUT /books/{pk} 删除单本书籍 DELETE /books/{pk} ''' # 1,列表视图 class BooksAPIView(View): ''' 查询所有屠苏,增加图书 ''' def get(self, request): """ 查询所有图书 路由:GET /books/info/ """ book_list = BookInfo.objects.all() # 2:创建可以序列化列表的序列化器 serializer_list = BookInfoSerializer(instance=book_list, many=True) # 3:转换数据 return JsonResponse(serializer_list.data, safe=False) def post(self, request): """ 新增图书 路由:POST /books/info/ """ json_bytes = request.body json_str = json_bytes.decode() book_dict = json.loads(json_str, encoding="utf-8") # 创建序列化器 serializer = BookInfoSerializer(data=book_dict) # 校验 serializer.is_valid(raise_exception=True) # 入库 serializer.save() return JsonResponse(serializer.data, status=201) class BookAPIView(View): ''' 查询所有图书,增加图书 ''' def get(self, request, pk): """ 根据图书ID查询图书 路由:GET /books/info/pk/ """ try: book = BookInfo.objects.get(id=pk) except BookInfo.DoesNotExist: return HttpResponse(status=404) serializer=BookInfoSerializer(instance=book) return JsonResponse(serializer.data, safe=False, status=201) def put(self, request, pk): """ 根据图书ID修改图书 路由:PUT /books/info/pk/ """ try: book = BookInfo.objects.get(id=pk) except BookInfo.DoesNotExist: return HttpResponse(status=404) json_bytes = request.body json_str = json_bytes.decode() book_dict = json.loads(json_str) # 2:创建序列化器 serializer = BookInfoSerializer(instance=book, data=book_dict) # 3:校验 serializer.is_valid(raise_exception=True) # 4:入库 serializer.save() serializer = BookInfoSerializer(instance=book) return JsonResponse(serializer.data, safe=False, status=201) def delete(self, request, pk): """ 根据图书ID删除图书 路由:DELETE /books/info/pk/ """ try: book = BookInfo.objects.get(id=pk) except BookInfo.DoesNotExist: return HttpResponse(status=404) book.delete() return JsonResponse({ "id": book.id, "btitle": book.btitle, "bpub_date": book.bpub_date, "bread": book.bread, "bcomment": book.bcomment }, status=204)
2.4 测试(Postman)
1)获取所有图书数据 http://127.0.0.1:8000/api/yango/v3/books/info
1 [ 2 { 3 "id": 1, 4 "btitle": "射雕英雄传", 5 "bpub_date": "1980-05-01", 6 "bread": 12, 7 "bcomment": 34, 8 "is_delete": false 9 }, 10 { 11 "id": 2, 12 "btitle": "天龙八部", 13 "bpub_date": "1986-07-24", 14 "bread": 36, 15 "bcomment": 40, 16 "is_delete": false 17 }, 18 { 19 "id": 3, 20 "btitle": "笑傲江湖", 21 "bpub_date": "1995-12-24", 22 "bread": 20, 23 "bcomment": 80, 24 "is_delete": false 25 }, 26 { 27 "id": 4, 28 "btitle": "雪山飞狐", 29 "bpub_date": "1987-11-11", 30 "bread": 58, 31 "bcomment": 24, 32 "is_delete": false 33 }, 34 { 35 "id": 5, 36 "btitle": "白马啸西风", 37 "bpub_date": "2020-02-02", 38 "bread": 0, 39 "bcomment": 0, 40 "is_delete": false 41 }, 42 { 43 "id": 7, 44 "btitle": "连城诀", 45 "bpub_date": "2020-02-02", 46 "bread": 0, 47 "bcomment": 0, 48 "is_delete": false 49 }, 50 { 51 "id": 9, 52 "btitle": "鹿鼎记", 53 "bpub_date": "2020-02-02", 54 "bread": 100, 55 "bcomment": 88, 56 "is_delete": false 57 } 58 ]
2)获取单一图书数据 http://127.0.0.1:8000/api/yango/v3/books/info/1
{ "id": 1, "btitle": "射雕英雄传", "bpub_date": "1980-05-01", "bread": 12, "bcomment": 34, "is_delete": false }
3)新增图书数据 http://127.0.0.1:8000/api/yango/v3/books/info
{ "btitle":"倚天屠龙记", "bpub_date":"2020-02-02" }
{ "id": 10, "btitle": "倚天屠龙记", "bpub_date": "2020-02-02", "bread": 0, "bcomment": 0, "is_delete": false }
4)修改图书数据 http://127.0.0.1:8000/api/yango/v3/books/info/10/
{ "btitle":"倚天屠龙记", "bread":90, "bcomment":80, "bpub_date":"2020-03-03" }
{ "id": 10, "btitle": "倚天屠龙记", "bpub_date": "2020-03-03", "bread": 90, "bcomment": 80, "is_delete": false }
5)删除图书数据 http://127.0.0.1:8000/api/yango/v3/books/info/10/
{ "id": null, "btitle": "倚天屠龙记", "bpub_date": "2020-03-03", "bread": 90, "bcomment": 80 }
3:模型类序列化器ModelSerializer
-
不用自己定义字段,基于模型类生成一系列字段
-
不用自己定义校验,基于模型类自动为Serializer生成validators, 比如unique_together
-
包含默认的create()和update()的实现
from rest_framework import serializers from APP01.models import BookInfo class BookInfoSerializer(serializers.ModelSerializer): """图书数据序列化""" class Meta: model=BookInfo fields='__all__'
python manage.py shell from APP01.serializer import BookInfoSerializerserializer = BookInfoSerializer() print(serializer) ''' BookInfoSerializer(): id = IntegerField(label='ID', read_only=True) btitle = CharField(label='名称', max_length=20) bpub_date = DateField(label='发布日期') bread = IntegerField(label='阅读量', max_value=2147483647, min_value=-2147483648, required=False) bcomment = IntegerField(label='评论量', max_value=2147483647, min_value=-2147483648, required=False) is_delete = BooleanField(label='逻辑删除', required=False) '''
4.2 指定字段
-
fields='__all__' ,表示所有字段,也可以明确具体字段
-
fields = ('id', 'btitle', 'bpub_date')
-
使用exclude可以明确排除掉哪些字段
-
exclude = ('is_delete',)
-
depth 表示嵌套层级,用整数表示,默认表示使用主键作为关联字段,进行嵌套
-
depth = 1
-
read_only_fields指明只读字段
-
read_only_fields = ('id', 'bread', 'bcomment')
-
extra_kwargs参数为ModelSerializer添加或修改原有的选项参数
-
extra_kwargs = { 'bread': {'min_value': 0, 'required': True}, 'bcomment': {'min_value': 0, 'required': True}, }
from APP01.models import BookInfo,HeroInfo from APP01.serializer import BookInfoSerializer,HeroInfoSerializer '''===================1,ModelSerializer序列化器,序列化所有字段,fields='__all__'====================''' from APP01.serializer import BookInfoSerializer serializer = BookInfoSerializer() print(serializer) ''' class BookInfoSerializer(serializers.ModelSerializer): """图书数据序列化""" class Meta: model=BookInfo fields='__all__' BookInfoSerializer(): id = IntegerField(label='ID', read_only=True) btitle = CharField(label='名称', max_length=20) bpub_date = DateField(label='发布日期') bread = IntegerField(label='阅读量', max_value=2147483647, min_value=-2147483648, required=False) bcomment = IntegerField(label='评论量', max_value=2147483647, min_value=-2147483648, required=False) is_delete = BooleanField(label='逻辑删除', required=False) ''' '''===================2,ModelSerializer序列化器,序列化指定字段,fields=('YY'.'XX')====================''' from APP01.serializer import BookInfoSerializer serializer = BookInfoSerializer() print(serializer) ''' class BookInfoSerializer(serializers.ModelSerializer): """图书数据序列化""" class Meta: model=BookInfo fields=('id','btitle') BookInfoSerializer(): id = IntegerField(label='ID', read_only=True) btitle = CharField(label='名称', max_length=20) ''' '''===================3,ModelSerializer序列化器,排除序列化指定字段,exclude=('YY'.'XX')====================''' from APP01.serializer import BookInfoSerializer serializer = BookInfoSerializer() print(serializer) ''' class BookInfoSerializer(serializers.ModelSerializer): """图书数据序列化""" class Meta: model=BookInfo exclude=('id','btitle') BookInfoSerializer(): bpub_date = DateField(label='发布日期') bread = IntegerField(label='阅读量', max_value=2147483647, min_value=-2147483648, required=False) bcomment = IntegerField(label='评论量', max_value=2147483647, min_value=-2147483648, required=False) is_delete = BooleanField(label='逻辑删除', required=False) ''' '''===================3,ModelSerializer序列化器,排除序列化指定字段,exclude=('YY'.'XX')====================''' from APP01.serializer import HeroInfoSerializer serializer = HeroInfoSerializer() print(serializer) ''' class HeroInfoSerializer(serializers.ModelSerializer): """英雄数据序列化""" class Meta: model = HeroInfo fields = '__all__' depth = 1 HeroInfoSerializer(): id = IntegerField(label='ID', read_only=True) hname = CharField(label='名称', max_length=20) hgender = ChoiceField(choices=((0, 'female'), (1, 'male')), label='性别', required=False, validators=[<django.core.validators.MinValueValidator object>, <django.core.validators.MaxValueValidator obje ct>]) hcomment = CharField(allow_null=True, label='描述信息', max_length=200, required=False) is_delete = BooleanField(label='逻辑删除', required=False) hbook = NestedSerializer(read_only=True): id = IntegerField(label='ID', read_only=True) btitle = CharField(label='名称', max_length=20) bpub_date = DateField(label='发布日期') bread = IntegerField(label='阅读量', max_value=2147483647, min_value=-2147483648, required=False) bcomment = IntegerField(label='评论量', max_value=2147483647, min_value=-2147483648, required=False) is_delete = BooleanField(label='逻辑删除', required=False) '''
4:通过模型类序列化器ModelSerializer完善代码
只需要优化序列化器,其余的代码逻辑可保持不变
from rest_framework import serializers from APP01.models import BookInfo, HeroInfo class BookInfoSerializer(serializers.ModelSerializer): """图书数据序列化""" class Meta: model = BookInfo fields = '__all__' class HeroInfoSerializer(serializers.ModelSerializer): """英雄数据序列化""" class Meta: model = HeroInfo fields = '__all__'