HBASE 入梦
Hbase 简介
什么是Hbase
目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储。
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
Hbase 特点
-
海量存储
-
列式存储
-
极易扩展
Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
通过横向添加RegionSever的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力。备注:RegionServer的作用是管理region、承接业务的访问,这个后面会详细的介绍通过横向添加Datanode的机器,进行存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力。
-
高并发
-
稀疏
稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
Hbase 架构
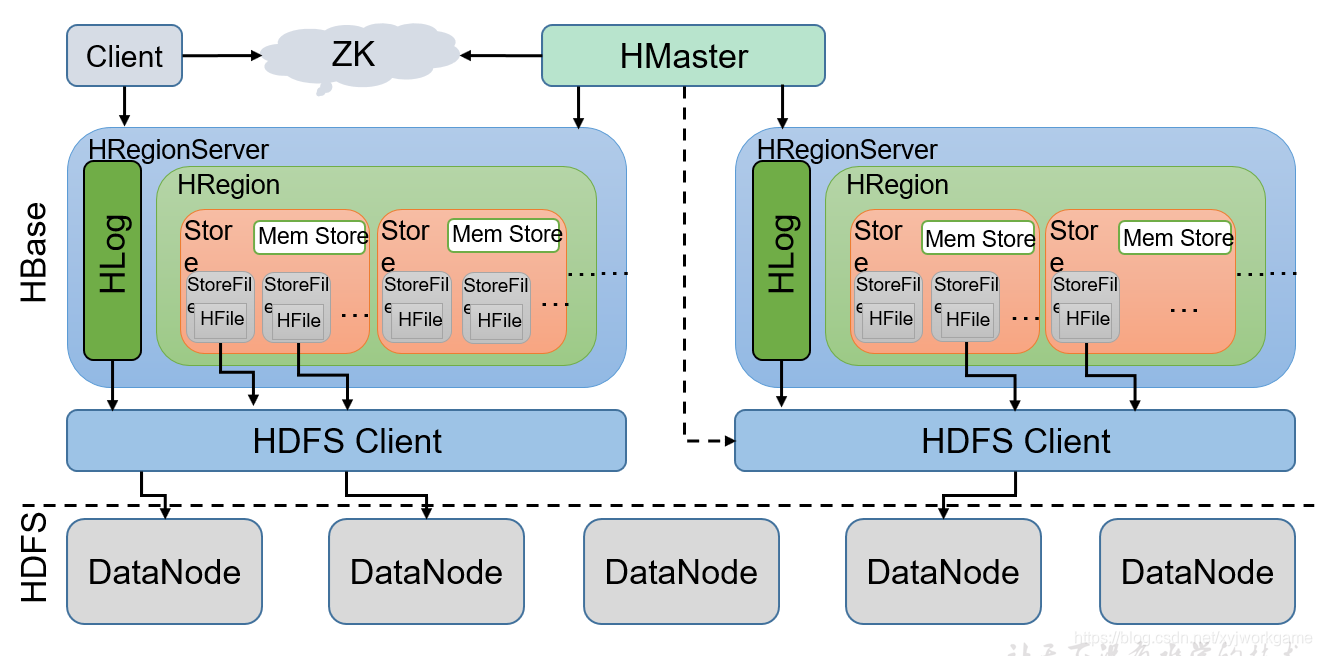
- Client
Client包含了访问Hbase的接口,另外Client还维护了对应的cache来加速Hbase的访问,比如cache的.META.元数据的信息。 - Zookeeper
HBase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。具体工作如下:
通过Zoopkeeper来保证集群中只有1个master在运行,如果master异常,会通过竞争机制产生新的master提供服务
通过Zoopkeeper来监控RegionServer的状态,当RegionSevrer有异常的时候,通过回调的形式通知Master RegionServer上下线的信息
通过Zoopkeeper存储元数据的统一入口地址 - Hmaster
master节点的主要职责如下:
为RegionServer分配Region
维护整个集群的负载均衡
维护集群的元数据信息
发现失效的Region,并将失效的Region分配到正常的RegionServer上
当RegionSever失效的时候,协调对应Hlog的拆分 - HregionServer
HregionServer直接对接用户的读写请求,是真正的“干活”的节点。它的功能概括如下:
管理master为其分配的Region
处理来自客户端的读写请求
负责和底层HDFS的交互,存储数据到HDFS
负责Region变大以后的拆分
负责Storefile的合并工作 - HDFS
HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用(Hlog存储在HDFS)的支持,具体功能概括如下:
提供元数据和表数据的底层分布式存储服务
数据多副本,保证的高可靠和高可用性
Hbase 中的角色
HMaster
功能
1.监控RegionServer
2.处理RegionServer故障转移
3.处理元数据的变更
4.处理region的分配或转移
5.在空闲时间进行数据的负载均衡
6.通过Zookeeper发布自己的位置给客户端
RegionServer
功能
1.负责存储HBase的实际数据
2.处理分配给它的Region
3.刷新缓存到HDFS
4.维护Hlog
5.执行压缩
6.负责处理Region分片
其他组件
1.Write-Ahead logs
HBase的修改记录,当对HBase读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
2.Region
Hbase表的分片,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一个RegionServer中可以有多个不同的region。
3.Store
HFile存储在Store中,一个Store对应HBase表中的一个列族。
4.MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在WAL中之后,RegsionServer会在内存中存储键值对。
5.HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。StoreFile是以Hfile的形式存储在HDFS的。
HBase 安装
Zookeeper 正常部署
bin/zkServer.sh start
bin/zkServer.sh start
bin/zkServer.sh start
hadoop正常部署
sbin/start-dfs.sh
sbin/start-yarn.sh
HBase 安装
1. 解压到目录
tar -zxvf hbase-1.3.1-bin.tar.gz -C /opt/module
2. 配置文件
-
hbase-env.sh 修改内容
export JAVA_HOME=/opt/module/jdk1.8.0_144 export HBASE_MANAGES_ZK=false -
hbase-site.xml 修改内容
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://hadoop102:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 --> <property> <name>hbase.master.port</name> <value>16000</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/opt/module/zookeeper-3.4.10/zkData</value> </property> </configuration> -
regionservers:
hadoop100 hadoop101 hadoop102 -
软连接hadoop配置文件到hbase
ln -s /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml /opt/module/hbase/conf/core-site.xml ln -s /opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml /opt/module/hbase/conf/hdfs-site.xml
同步其他服务器
xsync.sh hbase/
启动服务
-
启动方式1
bin/hbase-daemon.sh start master bin/hbase-daemon.sh start regionserver如果集群之间的节点时间不同步,会导致regionserver无法启动,抛出ClockOutOfSyncException异常。
-
同步时间服务看 hadoop
-
属性hbase.master.maxclockskew设置更大的值
<property> <name>hbase.master.maxclockskew</name> <value>180000</value> <description>Time difference of regionserver from master</description> </property>
-
-
启动方式2
bin/start-hbase.sh
bin/stop-hbase.sh
查看HBase 页面
http://hadoop100:16010
HBase Shell操作
基本操作
-
进入客户端命令行
Bin/hbase shell
-
帮助
help
-
查看当前数据中有哪些表
list
-
如果在shell命令想要删除,ctrl+backspace 进行删除
表的操作
-
创建表
create ‘student’,‘info’
-
插入数据到表
hbase(main):003:0> put 'student','1001','info:sex','male' hbase(main):004:0> put 'student','1001','info:age','18' hbase(main):005:0> put 'student','1002','info:name','Janna' hbase(main):006:0> put 'student','1002','info:sex','female' hbase(main):007:0> put 'student','1002','info:age','20' -
扫描查看数据表
hbase(main):008:0> scan 'student' hbase(main):009:0> scan 'student',{STARTROW => '1001', STOPROW => '1001'} hbase(main):010:0> scan 'student',{STARTROW => '1001'} -
查看表结构
hbase(main):008:0> scan 'student' hbase(main):009:0> scan 'student',{STARTROW => '1001', STOPROW => '1001'} hbase(main):010:0> scan 'student',{STARTROW => '1001'} -
更新指定字段的数据
hbase(main):012:0> put 'student','1001','info:name','Nick' hbase(main):013:0> put 'student','1001','info:age','100' -
查看指定行或指定列族 的数据
hbase(main):014:0> get 'student','1001' hbase(main):015:0> get 'student','1001','info:name' -
统计表数据行数
count 'student' -
删除数据
删除某rowkey的全部数据: hbase(main):016:0> deleteall 'student','1001' 删除某rowkey的某一列数据: hbase(main):017:0> delete 'student','1002','info:sex' -
清空表数据
truncate ‘student’
-
删除表
首先需要先让该表为disable状态: hbase(main):019:0> disable 'student' 然后才能drop这个表: hbase(main):020:0> drop 'student' 提示:如果直接drop表,会报错:ERROR: Table student is enabled. Disable it first. -
变更表信息
hbase(main):022:0> alter 'student',{NAME=>'info',VERSIONS=>3} hbase(main):022:0> get 'student','1001',{COLUMN=>'info:name',VERSIONS=>3}
HBase数据结构
RowKey
与nosql数据库们一样,RowKey是用来检索记录的主键。访问HBASE table中的行,只有三种方式:
1.通过单个RowKey访问
2.通过RowKey的range(正则)
3.全表扫描
RowKey行键 (RowKey)可以是任意字符串(最大长度是64KB,实际应用中长度一般为 10-100bytes),在HBASE内部,RowKey保存为字节数组。存储时,数据按照RowKey的字典序(byte order)排序存储。设计RowKey时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
Column Family
列族:HBASE表中的每个列,都归属于某个列族。列族是表的schema的一部 分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如 courses:history,courses:math都属于courses 这个列族。
Cell
由{rowkey, column Family:columu, version} 唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存贮。
关键字:无类型、字节码
Time Stamp
HBASE 中通过rowkey和columns确定的为一个存贮单元称为cell。每个 cell都保存 着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由HBASE(在数据写入时自动 )赋值,此时时间戳是精确到毫秒 的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版 本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,HBASE提供 了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段 时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
命名空间
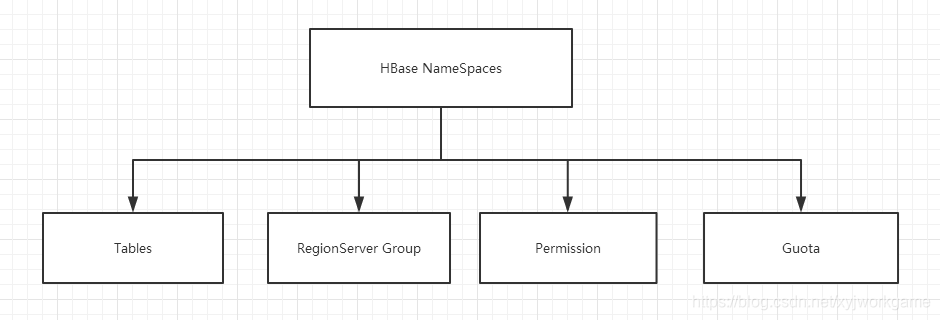
1) Table:表,所有的表都是命名空间的成员,即表必属于某个命名空间,如果没有指定,则在default默认的命名空间中。
2) RegionServer group**:**一个命名空间包含了默认的RegionServer Group。
3) Permission**:**权限,命名空间能够让我们来定义访问控制列表ACL(Access Control List)。例如,创建表,读取表,删除,更新等等操作。
4) Quota**:**限额,可以强制一个命名空间可包含的region的数量。
Hbase 原理
读流程
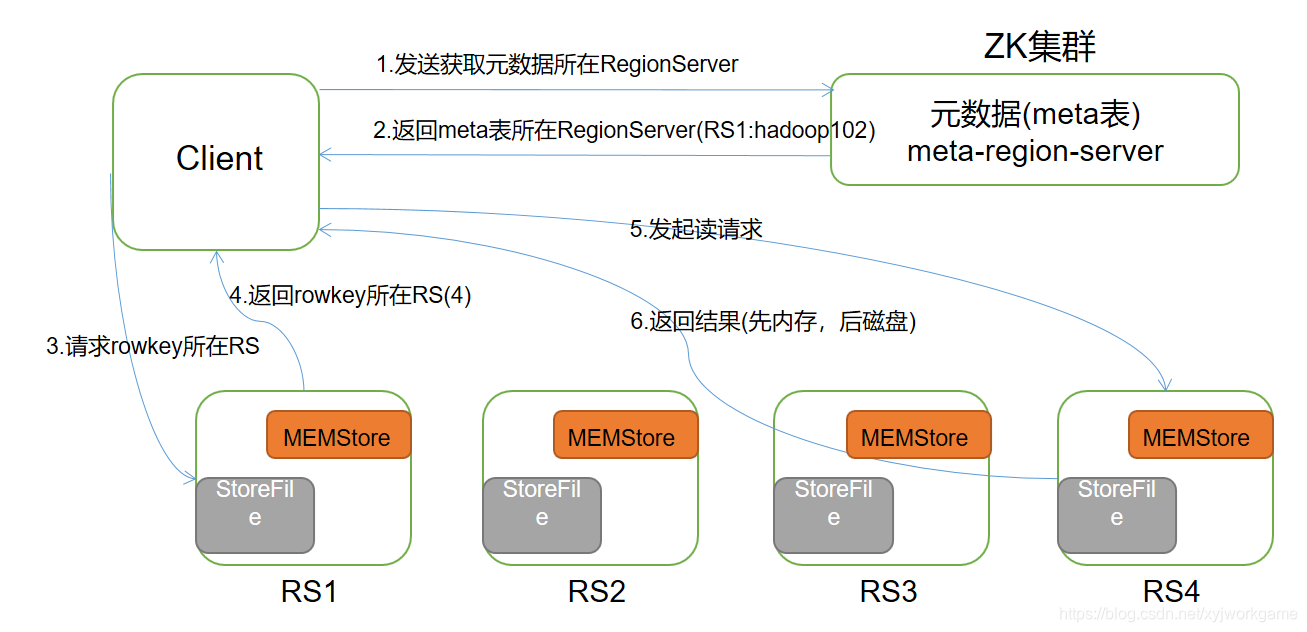
1)Client先访问zookeeper,从meta表读取region的位置,然后读取meta表中的数据。meta中又存储了用户表的region信息;
2)根据namespace、表名和rowkey在meta表中找到对应的region信息;
3)找到这个region对应的regionserver;
4)查找对应的region;
5)先从MemStore找数据,如果没有,再到BlockCache里面读;
6)BlockCache还没有,再到StoreFile上读(为了读取的效率);
7)如果是从StoreFile里面读取的数据,不是直接返回给客户端,而是先写入BlockCache,再返回给客户端。
写流程
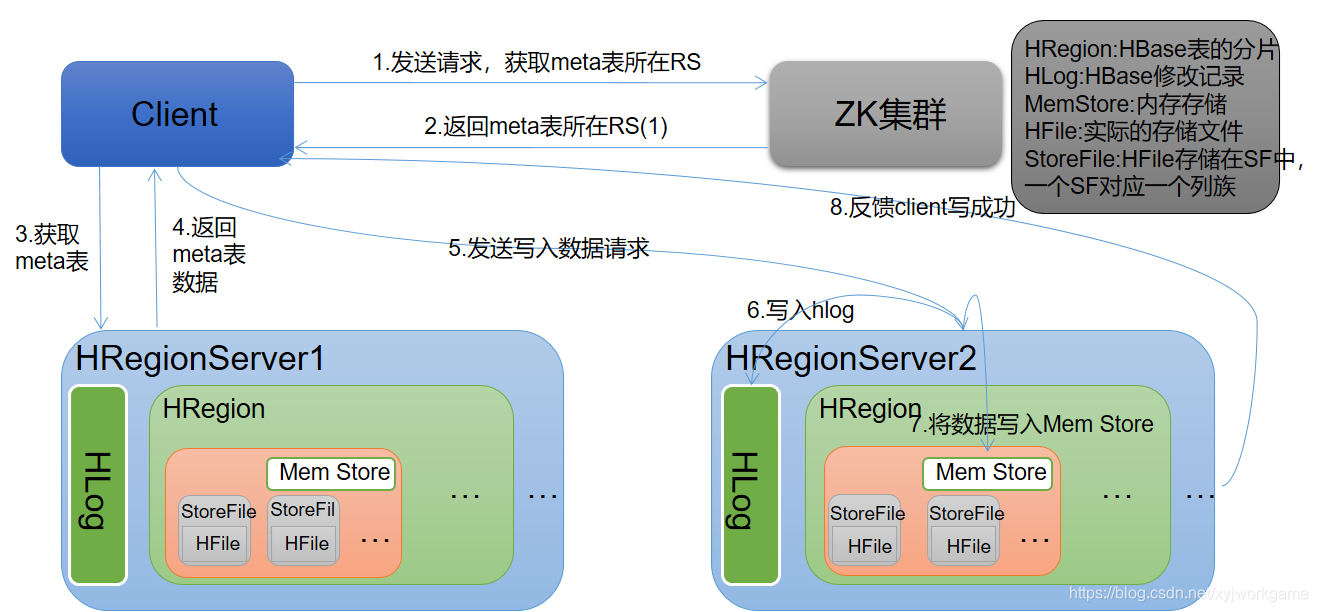
1)Client向HregionServer发送写请求;
2)HregionServer将数据写到HLog(write ahead log)。为了数据的持久化和恢复;
3)HregionServer将数据写到内存(MemStore);
4)反馈Client写成功。
数据Flush过程
1)当MemStore数据达到阈值(默认是128M,老版本是64M),将数据刷到硬盘,将内存中的数据删除,同时删除HLog中的历史数据;
2)并将数据存储到HDFS中;
3)在HLog中做标记点。
数据合并过程
1)当数据块达到4块,Hmaster触发合并操作,Region将数据块加载到本地,进行合并;
2)当合并的数据超过256M,进行拆分,将拆分后的Region分配给不同的HregionServer管理;
3)当HregionServer宕机后,将HregionServer上的hlog拆分,然后分配给不同的HregionServer加载,修改.META.;
4)注意:HLog会同步到HDFS。
HBase Api 操作
环境准备
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.1</version>
</dependency>
HBaseAPI
获取Configuration对象
public static Configuration conf;
static{
//使用HBaseConfiguration的单例方法实例化
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "192.168.9.102");
conf.set("hbase.zookeeper.property.clientPort", "2181");
}
判断表是否存在
public static boolean isTableExist(String tableName) throws MasterNotRunningException,
ZooKeeperConnectionException, IOException{
//在HBase中管理、访问表需要先创建HBaseAdmin对象
//Connection connection = ConnectionFactory.createConnection(conf);
//HBaseAdmin admin = (HBaseAdmin) connection.getAdmin();
HBaseAdmin admin = new HBaseAdmin(conf);
return admin.tableExists(tableName);
}
创建表
public static void createTable(String tableName, String... columnFamily) throws
MasterNotRunningException, ZooKeeperConnectionException, IOException{
HBaseAdmin admin = new HBaseAdmin(conf);
//判断表是否存在
if(isTableExist(tableName)){
System.out.println("表" + tableName + "已存在");
//System.exit(0);
}else{
//创建表属性对象,表名需要转字节
HTableDescriptor descriptor = new HTableDescriptor(TableName.valueOf(tableName));
//创建多个列族
for(String cf : columnFamily){
descriptor.addFamily(new HColumnDescriptor(cf));
}
//根据对表的配置,创建表
admin.createTable(descriptor);
System.out.println("表" + tableName + "创建成功!");
}
}
删除表
public static void dropTable(String tableName) throws MasterNotRunningException,
ZooKeeperConnectionException, IOException{
HBaseAdmin admin = new HBaseAdmin(conf);
if(isTableExist(tableName)){
admin.disableTable(tableName);
admin.deleteTable(tableName);
System.out.println("表" + tableName + "删除成功!");
}else{
System.out.println("表" + tableName + "不存在!");
}
}
向表中插入数据
public static void addRowData(String tableName, String rowKey, String columnFamily, String
column, String value) throws IOException{
//创建HTable对象
HTable hTable = new HTable(conf, tableName);
//向表中插入数据
Put put = new Put(Bytes.toBytes(rowKey));
//向Put对象中组装数据
put.add(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value));
hTable.put(put);
hTable.close();
System.out.println("插入数据成功");
}
删除多行数据
public static void deleteMultiRow(String tableName, String... rows) throws IOException{
HTable hTable = new HTable(conf, tableName);
List<Delete> deleteList = new ArrayList<Delete>();
for(String row : rows){
Delete delete = new Delete(Bytes.toBytes(row));
deleteList.add(delete);
}
hTable.delete(deleteList);
hTable.close();
}
获取所有数据
public static void getAllRows(String tableName) throws IOException{
HTable hTable = new HTable(conf, tableName);
//得到用于扫描region的对象
Scan scan = new Scan();
//使用HTable得到resultcanner实现类的对象
ResultScanner resultScanner = hTable.getScanner(scan);
for(Result result : resultScanner){
Cell[] cells = result.rawCells();
for(Cell cell : cells){
//得到rowkey
System.out.println("行键:" + Bytes.toString(CellUtil.cloneRow(cell)));
//得到列族
System.out.println("列族" + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("列:" + Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println("值:" + Bytes.toString(CellUtil.cloneValue(cell)));
}
}
}
获取某一行数据
public static void getRow(String tableName, String rowKey) throws IOException{
HTable table = new HTable(conf, tableName);
Get get = new Get(Bytes.toBytes(rowKey));
//get.setMaxVersions();显示所有版本
//get.setTimeStamp();显示指定时间戳的版本
Result result = table.get(get);
for(Cell cell : result.rawCells()){
System.out.println("行键:" + Bytes.toString(result.getRow()));
System.out.println("列族" + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("列:" + Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println("值:" + Bytes.toString(CellUtil.cloneValue(cell)));
System.out.println("时间戳:" + cell.getTimestamp());
}
}
获取某一行指定”列族:列“数据
public static void getRowQualifier(String tableName, String rowKey, String family, String
qualifier) throws IOException{
HTable table = new HTable(conf, tableName);
Get get = new Get(Bytes.toBytes(rowKey));
get.addColumn(Bytes.toBytes(family), Bytes.toBytes(qualifier));
Result result = table.get(get);
for(Cell cell : result.rawCells()){
System.out.println("行键:" + Bytes.toString(result.getRow()));
System.out.println("列族" + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("列:" + Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println("值:" + Bytes.toString(CellUtil.cloneValue(cell)));
}
}