负载均衡
目的:将请求分发到其他功能相同的服务
- 当系统面临大量的用户访问,负载过高的时候,通常会增加服务器数量来进行横向扩展(集群)
- 多个服务器的负载需要均衡,以免出现服务器负载不均衡,部分服务器负载较大,部分服务器负载较小的情况
- 通过负载均衡,使得集群中服务器的负载保持在稳定高效的状态,从而提高整个系统的处理能力
两种负载均衡
- 软件负载均衡:nginx,lvs
- 硬件负载均衡:F5
我们只关注软件负载均衡
- 第一层可以用DNS,配置多个A记录,让DNS做第一层分发
- 第二层用比较流行的是反向代理,核心原理:代理根据一定规则,将http请求转发到服务器集群的单一服务器上
软件负载均衡分为:服务端(集中式),客户端
- 服务端负载均衡:在客户端和服务端中间使用代理,nginx
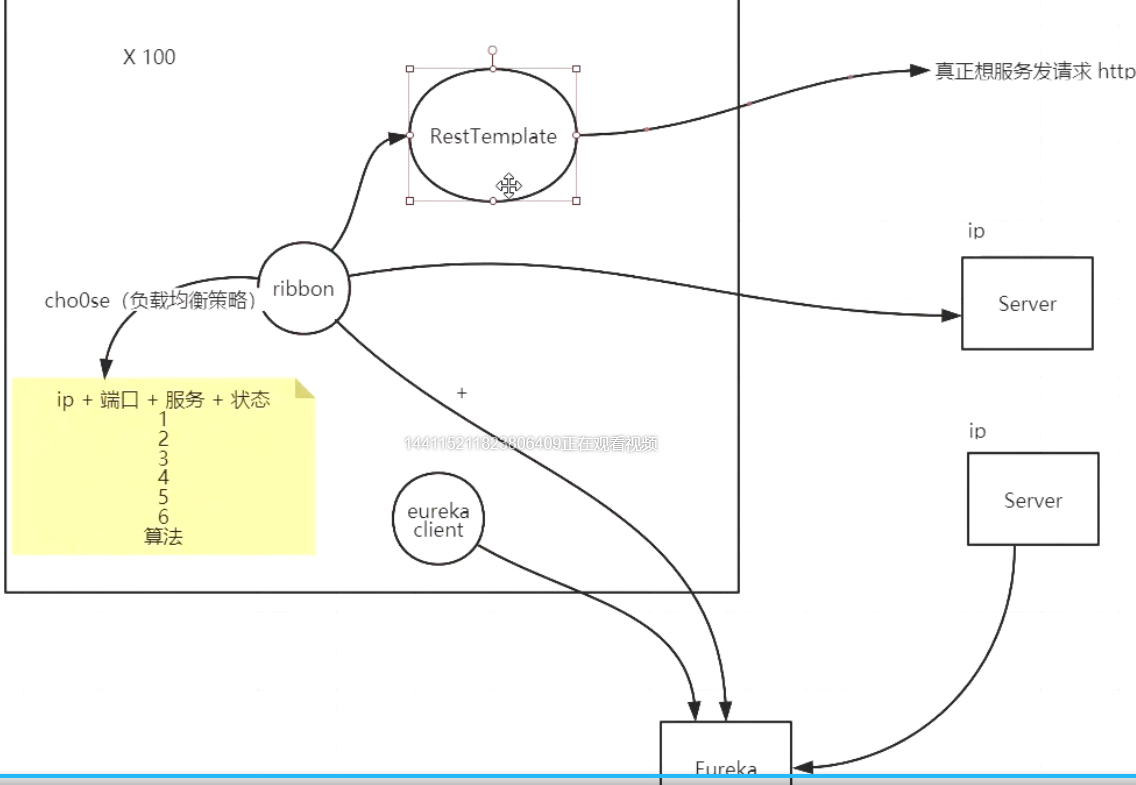
- 客户端负载均衡:根据自己的情况做负载,Ribbon属于其中之一
- 客户端负载均衡和服务端负载均衡最大的区别在于服务端地址列表的存储位置,以及负载算法在哪里
客户端负载均衡
在客户端负载均衡中,所有的客户端节点都有一份自己要访问的服务端地址列表,这些列表统统都是从服务注册中心获取的
- Ribbon
- 在Spring Cloud中如果想要使用客户端负载均衡,使用@LoadBalanced注解即可
- 这样客户端在发起请求的时候会根据负载均衡策略从服务端列表中选择一个服务端,向该服务端发起网络请求,从而实现负载均衡
服务端负载均衡
在服务端负载均衡中,客户端节点只知道单一服务代理的地址,服务代理则知道所有服务端的地址
手写客户端负载均衡
- 知道自己的请求目的地(虚拟主机名,默认是spring.application.name)
- 获取所有服务端地址列表(也就是注册表)
- 选出一个地址,找到虚拟主机名对应的ip、port(将虚拟主机名 对应到 ip和port上)
- 发起实际请求(最朴素的请求)
Ribbon
Ribbon是Netflix开发的客户端负载均衡器,为Ribbon配置"服务提供者地址列表"后,Ribbon就可以基于某种"负载均衡策略算法",自动地帮助服务消费者去请求提供者
Ribbon默认为我们提供了很多负载均衡算法,例如轮询、随机等
Ribbon作为Spring Cloud的负载均衡机制的实现
- Ribbon可以单独使用,作为一个独立的负载均衡组件,只是需要我们手动配置 服务地址列表
- Ribbon与Eureka配合使用时,Ribbon可自动从Eureka Server获取服务提供者地址列表(DiscoveryClient),并基于负载均衡算法,请求其中一个服务提供者实例
- Ribbon与OpenFeign和RestTemplate进行无缝对接,让二者具有负载均衡的能力
- OpenFeign默认集成了ribbon
Ribbon组成
github地址:https://github.com/Netflix/ribbon
- ribbon-core: 核心的通用性代码。api一些配置
- ribbon-eureka:基于eureka封装的模块,能快速集成eureka
- ribbon-examples:学习示例
- ribbon-httpclient:基于apache httpClient封装的rest客户端,集成了负载均衡模块,可以直接在项目中使用
- ribbon-loadbalancer:负载均衡模块
- ribbon-transport:基于netty实现多协议的支持。比如http,tcp,udp等
负载均衡算法
默认实现
ZoneAvoidanceRule(区域权衡策略)
- 复合判断Server所在区域的性能和Server的可用性,轮询选择服务器
其他规则
BestAvailableRule(最低并发策略)
- 先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务。逐个找服务,如果断路器打开,则忽略
RoundRobinRule(轮询策略)
- 以简单轮询选择一个服务器。按顺序循环选择一个server。
RandomRule(随机策略)
- 随机选择一个服务器
AvailabilityFilteringRule(可用过滤策略)
- 会先过滤掉多次访问故障而处于断路器跳闸状态的服务和过滤并发的连接数量超过阀值得服务
- 然后对剩余的服务列表安装轮询策略进行访问
WeightedResponseTimeRule(响应时间加权策略)
- 据平均响应时间计算所有的服务的权重,响应时间越快服务权重越大,容易被选中的概率就越高
- 刚启动时,如果统计信息不中,则使用RoundRobinRule(轮询)策略,等统计的信息足够了会自动的切换到WeightedResponseTimeRule
- 响应时间长,权重低,被选择的概率低。反之,同样道理。此策略综合了各种因素(网络,磁盘,IO等),这些因素直接影响响应时间
RetryRule(重试策略)
- 先按照RoundRobinRule(轮询)的策略获取服务,如果获取的服务失败则在指定的时间会进行重试,进行获取可用的服务
- 如多次获取某个服务失败,就不会再次获取该服务
- 主要是在一个时间段内,如果选择一个服务不成功,就继续找可用的服务,直到超时
切换负载均衡策略
注解方式
@Bean public IRule myRule(){ //return new RoundRobinRule(); //return new RandomRule(); return new RetryRule();
}
配置文件
针对服务定ribbon策略
provider.ribbon.NFLoadBalancerRuleClassName=com.netflix.loadbalancer.RandomRule
给所有服务定ribbon策略
ribbon.NFLoadBalancerRuleClassName=com.netflix.loadbalancer.RandomRule
属性配置方式优先级高于Java代码。
Ribbon脱离Eureka
ribbon.eureka.enabled=false
ribbon.listOfServers=localhost:80,localhost:81
为service-sms设置 请求的网络地址列表
Ribbon可以和服务注册中心Eureka一起工作,从服务注册中心获取服务端的地址信息,也可以在配置文件中使用listOfServers字段来设置服务端地址
RestTemplate
依赖注入
@Bean // 开启负载均衡 @LoadBalanced RestTemplate restTemplate() { return new RestTemplate(); }
接下来便可以使用资源地址调用服务
String url ="http://provider/getHi"; String respStr = restTemplate.getForObject(url, String.class);
get 请求处理
getForEntity
getForEntity方法的返回值是一个ResponseEntity,ResponseEntity是Spring对HTTP请求响应的封装,包括了几个重要的元素,如响应码、contentType、contentLength、响应消息体等。
200,Hi,[Content-Type:"text/plain;charset=UTF-8", Content-Length:"8", Date:"Fri, 10 Apr 2020 09:58:44 GMT", Keep-Alive:"timeout=60", Connection:"keep-alive"]
返回一个Map
调用方
String url ="http://provider/getMap"; ResponseEntity<Map> entity = restTemplate.getForEntity(url, Map.class); System.out.println("respStr: " + entity.getBody());
生产方
@GetMapping("/getMap")
public Map<String, String> getMap() {
HashMap<String, String> map = new HashMap<>();
map.put("name", "500");
return map;
}
返回对象
调用方
ResponseEntity<Person> entity = restTemplate.getForEntity(url, Person.class); System.out.println("respStr:" + ToStringBuilder.reflectionToString(entity.getBody()));
生产方
@GetMapping("/getObj")
public Person getObj() {
Person person = new Person();
person.setId(100);
person.setName("xiaoming");
return person;
}
Person类
private int id; private String name;
传参调用
使用占位符
String url ="http://provider/getObjParam?name={1}";
ResponseEntity<Person> entity = restTemplate.getForEntity(url, Person.class,"hehehe...");
使用map
String url ="http://provider/getObjParam?name={name}";
Map<String, String> map = Collections.singletonMap("name", " memeda");
ResponseEntity<Person> entity = restTemplate.getForEntity(url, Person.class,map);
返回对象
Person person = restTemplate.getForObject(url, Person.class,map);
post 请求处理
调用方
String url ="http://provider/postParam"; Map<String, String> map = Collections.singletonMap("name", " memeda"); ResponseEntity<Person> entity = restTemplate.postForEntity(url, map, Person.class);
生产方
@PostMapping("/postParam")
public Person postParam(@RequestBody String name) {
System.out.println("name:" + name);
Person person = new Person();
person.setId(100);
person.setName("xiaoming" + name);
return person;
}
postForLocation
调用方
String url ="http://provider/postParam"; Map<String, String> map = Collections.singletonMap("name", " memeda"); URI location = restTemplate.postForLocation(url, map, Person.class); System.out.println(location);
生产方
需要设置头信息,不然返回的是null
public URI postParam(@RequestBody Person person,HttpServletResponse response) throws Exception { URI uri = new URI("https://www.baidu.com/s?wd="+person.getName()); response.addHeader("Location", uri.toString());
exchange
可以自定义http请求的头信息,同时保护get和post方法
拦截器
需要实现`ClientHttpRequestInterceptor`接口
public class LoggingClientHttpRequestInterceptor implements ClientHttpRequestInterceptor { @Override public ClientHttpResponse intercept(HttpRequest request, byte[] body, ClientHttpRequestExecution execution) throws IOException { System.out.println("拦截啦!!!"); System.out.println(request.getURI()); ClientHttpResponse response = execution.execute(request, body); System.out.println(response.getHeaders()); return response; }
}
添加到resttemplate中
@Bean @LoadBalanced RestTemplate restTemplate() { RestTemplate restTemplate = new RestTemplate(); restTemplate.getInterceptors().add(new LoggingClientHttpRequestInterceptor()); return restTemplate; }