一、简介:
在默认情况下Quartz将任务调度的运行信息保存在内存中,这种方法提供了最佳的性能,因为内存中数据访问最快。不足之处是缺乏数据的持久性,当程序路途停止或系统崩溃时,所有运行的信息都会丢失。
二、使用:
1、加入pom依赖
<!-- quartz -->
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.2.1</version>
</dependency>
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz-jobs</artifactId>
<version>2.2.1</version>
</dependency>
2、编写自定义任务类:Myjob
import org.quartz.*; import org.quartz.impl.JobDetailImpl; import org.quartz.impl.StdSchedulerFactory; import org.quartz.impl.triggers.SimpleTriggerImpl; import java.util.Date; // 自定义任务类:Myjob public class MyJob implements Job { public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException { System.out.println(new Date() + ": doing something..."); } }
3、编写测试代码
import org.quartz.*; import org.quartz.impl.JobDetailImpl; import org.quartz.impl.StdSchedulerFactory; import org.quartz.impl.triggers.SimpleTriggerImpl; import java.util.Date; public class JobTest { public static void main(String[] args) { //1、创建JobDetial对象 JobDetailImpl jobDetail = new JobDetailImpl(); //设置工作项 jobDetail.setJobClass(MyJob.class); jobDetail.setName("MyJob_1"); jobDetail.setGroup("JobGroup_1"); //2、创建Trigger对象 SimpleTriggerImpl strigger = new SimpleTriggerImpl(); strigger.setName("Trigger_1"); strigger.setGroup("Trigger_Group_1"); strigger.setStartTime(new Date()); //设置重复间隔时间 strigger.setRepeatInterval(1000 * 1L); //设置重复执行次数 strigger.setRepeatCount(3); //3、创建Scheduler对象,并配置JobDetail和Trigger对象 SchedulerFactory sf = new StdSchedulerFactory(); Scheduler scheduler = null; try { scheduler = sf.getScheduler(); scheduler.scheduleJob(jobDetail, strigger); //4、并执行启动、关闭等操作 scheduler.start(); } catch (SchedulerException e) { e.printStackTrace(); } } }
执行结果:
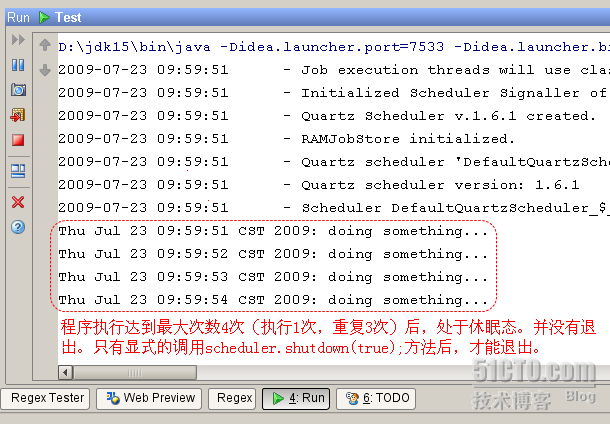
从这里也可以看出,scheduler是个容器,scheduler控制jobDetail的执行,控制的策略是通过trigger。当scheduler容器启动后,jobDetail才能根据关联的trigger策略去执行。当scheduler容器关闭后,所有的jobDetail都停止执行。