目录
一、信息标记的三种形式
XML格式数据

JSON格式数据

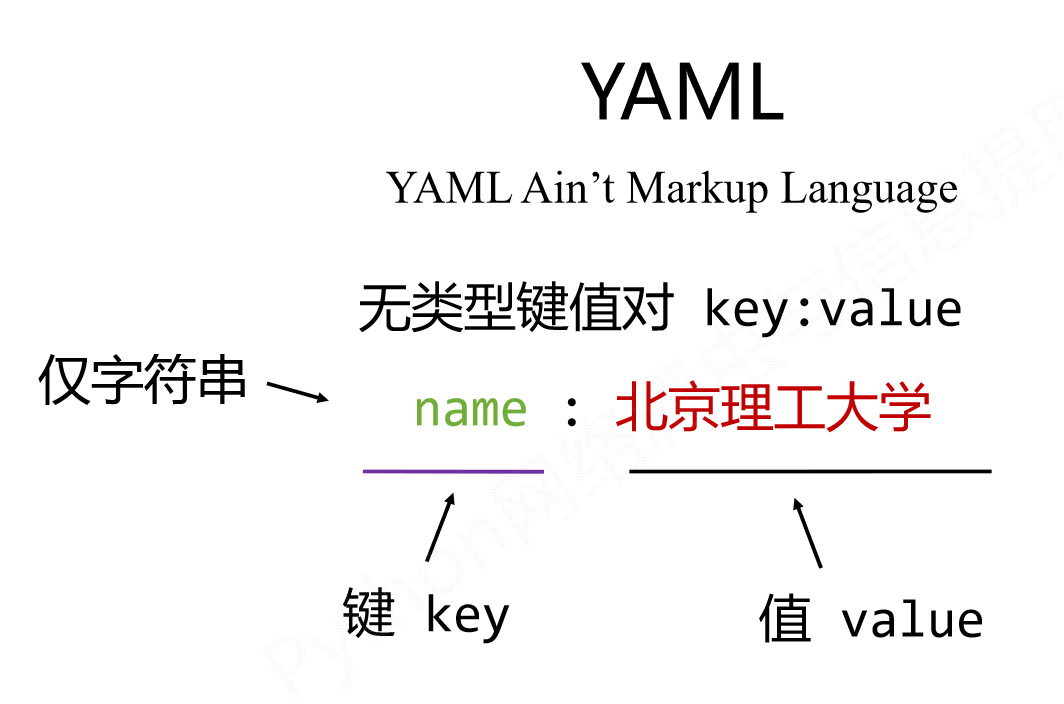
YAML格式数据
二、信息标记形式的比较
XML
- 最早的通用信息标记语言,可扩展性好,但繁琐。
- Internet上的信息交互与传递
JSON
- 信息有类型,适合程序处理(js),较XML简洁
- 移动应用云端和节点的信息通信,无注释、
YAML
- 信息无类型,文本信息比例最高,可读性好
- 各类系统的配置文件,有注释易读
三、信息提取的一般方法
方法一:
-
完整解析信息的标记形式,再提取关键信息
-
XML JSON YAML
需要标记解析器,例如:bs4库的标签树遍历
-
优点:信息解析准确
-
缺点:提取过程繁琐,速度慢
方法二:
-
无视标记形式,直接搜索关键信息
-
搜索
对信息的文本查找函数即可
-
优点:提取过程简洁,速度较快
-
缺点:提取结果准确性与信息内容相关
融合方法:
-
融合方法:结合形式解析与搜索方法,提取关键信息
-
XML JSON YAML 搜索
需要标记解析器及文本查找函数
实例:
提取HTML中所有URL链接
思路:
- 搜索到所有
<a>标签 - 解析
<a>标签格式,提取href后的链接内容
import requests
r = requests.get("http://www.baidu.com") # 得到response响应数据
r.encoding = r.apparent_encoding # 指定字符编码
demo = r.text
import bs4
# 制作soup
soup = bs4.BeautifulSoup(demo,"html.parser") # 要解析的内容,html解析器
# 提取链接内容
for link in soup.find_all("a"): # 查找所有a标签,并遍历
print(link.get("href")) # 标签类型,搜索href标签后的链接内容
四、基于bs4库的HTML内容查找方法
<>.find_all(name,attrs,recursive, string, **kwargs) 方法:
返回一个列表类型,存储查找的结果
- name : 对标签名称的检索字符串
- attrs: 对标签属性值的检索字符串,可标注属性检索
- recursive: 是否对子孙全部检索,默认True
- string: <>…</>中字符串区域的检索字符串
扩展方法
| 方法 | 说明 |
|---|---|
| <>.find() | 搜索且只返回一个结果,同.find_all()参数 |
| <>.find_parents() | 在先辈节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_parent() | 在先辈节点中返回一个结果,同.find()参数 |
| <>.find_next_siblings() | 在后续平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_next_sibling() | 在后续平行节点中返回一个结果,同.find()参数 |
| <>.find_previous_siblings() | 在前序平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_previous_sibling() | 在前序平行节点中返回一个结果,同.find()参数 |
总结:
