了解定时任务添加方式!
及定时任务运行方式!
及其运行原理!
1、安装
pip install apschenduler
2、核心组件
触发器(trigger)包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行。除了他们自己初始配置意外,触发器完全是无状态的。
作业存储(job store)存储被调度的作业,默认的作业存储是简单地把作业保存在内存中,其他的作业存储是将作业保存在数据库中。一个作业的数据讲在保存在持久化作业存储时被序列化,并在加载时被反序列化。调度器不能分享同一个作业存储。
执行器(executor)处理作业的运行,他们通常通过在作业中提交制定的可调用对象到一个线程或者进城池来进行。当作业完成时,执行器将会通知调度器。
调度器(scheduler)是其他的组成部分。你通常在应用只有一个调度器,应用的开发者通常不会直接处理作业存储、调度器和触发器,相反,调度器提供了处理这些的合适的接口。配置作业存储和执行器可以在调度器中完成,例如添加、修改和移除作业。
3.选择正确的调度程序,作业存储,执行程序和触发器
要选择适当的作业存储,您需要确定是否需要作业持久性。如果您总是在应用程序开始时重新创建作业,则可以使用默认值(MemoryJobStore)。但是,如果您需要作业以在调度程序重新启动或应用程序崩溃后继续存在,那么您的选择通常可以归结为编程环境中使用的工具。但是,如果您可以自由选择,则由于其强大的数据完整性保护,因此建议SQLAlchemyJobStore在 PostgreSQL后端上进行选择。
同样,如果您使用上述框架之一,通常会为您选择执行程序。否则,默认值ThreadPoolExecutor应足以满足大多数用途。如果您的工作量涉及CPU密集型操作,则应考虑ProcessPoolExecutor改为使用多个CPU内核。您甚至可以同时使用两者,将进程池执行程序添加为辅助执行程序。
安排工作时,需要为其选择一个触发器。触发器确定将在运行作业时计算日期/时间的逻辑。APScheduler带有三种内置的触发器类型:
也可以将多个触发器组合成一个触发器,该触发器可以在所有参与触发器约定的时间触发,也可以在任何触发器触发时触发。有关更多信息,请参见的文档。combining triggers
您可以在各自的API文档页面上找到每个作业存储,执行程序和触发器类型的插件名称。
4、调度程序
-
BlockingScheduler:当调度程序是您的流程中唯一运行的东西时使用
-
BackgroundScheduler:在不使用以下任何框架且希望调度程序在应用程序内部的后台运行时使用
-
AsyncIOScheduler:如果您的应用程序使用asyncio模块,则使用
-
GeventScheduler:如果您的应用程序使用gevent,则使用
-
TornadoScheduler:在构建Tornado应用程序时使用
-
TwistedScheduler:在构建Twisted应用程序时使用
-
QtScheduler:在构建Qt应用程序时使用
-
UTC作为调度程序的时区
-
默认情况下,对新作业关闭合并
-
新作业的默认最大实例限制为3
5、配置调度
from apscheduler.schedulers.background import BackgroundScheduler
scheduler = BackgroundScheduler()
# Initialize the rest of the application here, or before the scheduler initialization
配置调度器1(一个名为“ mongo”的MongoDBJobStore)
from pytz import utc
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.mongodb import MongoDBJobStore
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
jobstores = {
'mongo': MongoDBJobStore(),
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {
'default': ThreadPoolExecutor(20),
'processpool': ProcessPoolExecutor(5)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BackgroundScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
配置调度器12(一个名为“ default”的SQLAlchemyJobStore(使用SQLite))
from apscheduler.schedulers.background import BackgroundScheduler
# The "apscheduler." prefix is hard coded
scheduler = BackgroundScheduler({
'apscheduler.jobstores.mongo': {
'type': 'mongodb'
},
'apscheduler.jobstores.default': {
'type': 'sqlalchemy',
'url': 'sqlite:///jobs.sqlite'
},
'apscheduler.executors.default': {
'class': 'apscheduler.executors.pool:ThreadPoolExecutor',
'max_workers': '20'
},
'apscheduler.executors.processpool': {
'type': 'processpool',
'max_workers': '5'
},
'apscheduler.job_defaults.coalesce': 'false',
'apscheduler.job_defaults.max_instances': '3',
'apscheduler.timezone': 'UTC',
}) #apscheduler.timezone 是设置存储桶时区也是作业的时间 国内用这个Asia/Shanghai
一个名为“ default”的ThreadPoolExecutor,其工作人员数为20
一个名为“ processpool”的ProcessPoolExecutor,其工作人员数为
from pytz import utc
from apscheduler.schedulers.background importBackgroundScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import
ProcessPoolExecutor
jobstores = {
'mongo': {'type': 'mongodb'},
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {
'default': {'type': 'threadpool', 'max_workers': 20},
'processpool': ProcessPoolExecutor(max_workers=5)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BackgroundScheduler()
# .. do something else here, maybe add jobs etc.
scheduler.configure(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
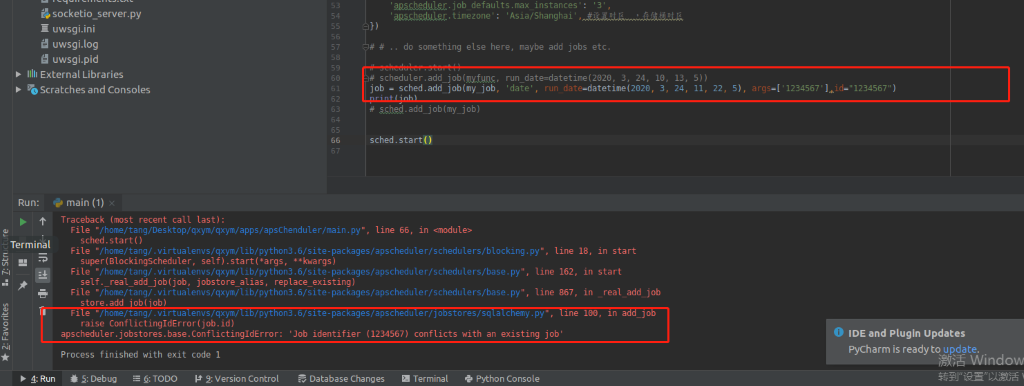
replace_existing=True
程序中断后重新运行时会自动从数据库读取作业信息,而不需要重新再添加到调度器中,如果不注释 21-25 行添加作业的代码,则作业会重新添加到数据库中,这样就有了两个同样的作业,避免出现这种情况可以在 add_job 的参数中增加 replace_existing=True,如
在程序中添加add_job 设置id 那么 没有replace_existing=True
1、会报错,id重复,如果加了重复id 会被过滤不会报错。
apscheduler.jobstores.base.ConflictingIdError: 'Job identifier (1234567) conflicts with an existing job'