一,id,is,==
在Python中,id是什么?id是内存地址,比如你利用id()内置函数去查询一个数据的内存地址:
# 在pycharm中,每次运行id都不同
== 是比较的两边的数值是否相等,而 is 是比较的两边的内存地址是否相等。 如果内存地址相等,那么这两边其实是指向同一个内存地址。

二,代码块。
i = 1
i2 = 3
i3 = 4
一个文件是一个代码块.(函数,类都是一个代码块.)
交互命令中一行就是一个代码块.


代码块的缓存机制
Python在执行同一个代码块的初始化对象的命令时,会检查是否其值是否已经存在,如果存在,会将其重用。换句话说:执行同一个代码块时,遇到初始化对象的命令时,他会将初始化的这个变量与值存储在一个字典中,在遇到新的变量时,会先在字典中查询记录,如果有同样的记录那么它会重复使用这个字典中的之前的这个值。所以在你给出的例子中,文件执行时(同一个代码块)会把i1、i2两个变量指向同一个对象,满足缓存机制则他们在内存中只存在一个,即:id相同。
代码块的缓存机制的适用范围: int(float),str,bool。
int(float):任何数字在同一代码块下都会复用。
bool:True和False在字典中会以1,0方式存在,并且复用。
str:几乎所有的字符串都会符合缓存机制,具体规定如下(了解即可!):
通过相乘的形式构建的字符串长度不能超过20满足同一代码块的驻留机制.
s1 = 'old_' * 5
s2 = 'old_' * 5
print(s1 is s2) # True
同一个代码块:同一代码块的缓存机制,驻留机制.
i1 = 100
i2 = 300
i3 = 100

三,小数据池
大前提:小数据池也是只针对 int(float),str,bool。
小数据池是针对不同代码块之间的缓存机制!!
int: -5 ~256
str: 一定规则的字符串
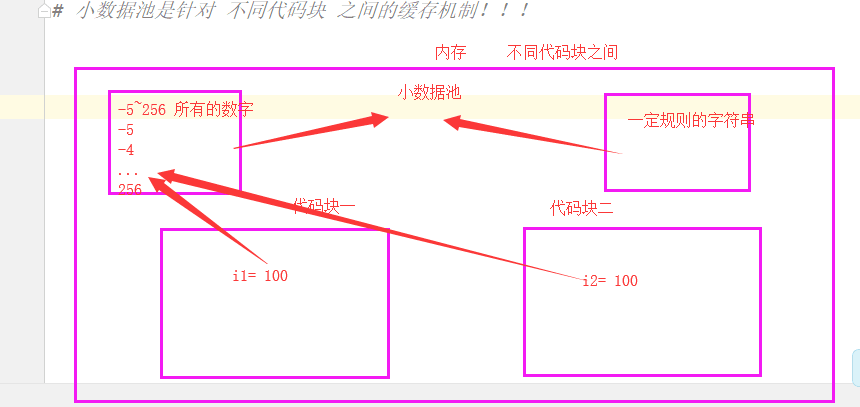
总结
如果在同一代码块下,则采用同一代码块下的换缓存机制。
如果是不同代码块,则采用小数据池的驻留机制。
太白老师博客:
https://www.cnblogs.com/jin-xin/articles/9439483.html
四,python基础数据类型的补充
数据类型之间的转换
Int bool str list tuple dict set
bool 可以与所有的数据类型进行转换.
所有为空的数据类型转化成bool都为Fasle.
0 '' [] () {} None ----> Fasle
str ---> list split 分割
list ---> str join # list里面的元素全部都是str类型
l1 = ['武sir', 'alex', '太白'] print(' '.join(l1))
str ----> tuple # partition
tuple ---> str join
tu1 = ('武sir', 'alex', '太白') ret = ' '.join(tu1) print(ret,type(ret))
list<----->tuple
l1 = ['武sir', 'alex', '太白'] print(tuple(l1)) tu1 = ('武sir', 'alex', '太白') print(list(tu1))
dict ----> list
dic = {'name':'alex','age': 73}
print(list(dic))
# 注: tuple: 如果元组中只有单个元素并且没有 ‘,’ 则类型是元素本身的类型.
tu1 = (1) print(tu1,type(tu1)) tu1 = ('alex',) print(tu1,type(tu1)
dic 补充
dict.fromkeys
dic = dict.fromkeys([1,2,3],'太白') print(dic) #{1: '太白', 2: '太白', 3: '太白'} dic = dict.fromkeys('abcd','太白') print(dic) #{'a': '太白', 'b': '太白', 'c': '太白', 'd': '太白'} dic = dict.fromkeys('abcd',[1,]) print(dic) #{'a': [1], 'b': [1], 'c': [1], 'd': [1]}
# 坑: 如果你的值是一个可变的数据类型, 他在内存中是一个.id相同.
dic = dict.fromkeys('abcd',[]) dic['a'].append(666) print(dic) #{'a': [666], 'b': [666], 'c': [666], 'd': [666]} dic['b'].append(111) print(dic) #{'a': [666, 111], 'b': [666, 111], 'c': [666, 111], 'd': [666, 111]} dic['c'].append(222) print(dic) #{'a': [666, 111, 222], 'b': [666, 111, 222], 'c': [666, 111, 222], 'd': [666, 111, 222]}
l1 = [1,2,3] l2 = l1 l3 = l2 l1.append(666) l2.append(111) print(l1) #[1, 2, 3, 666, 111]
例: l1 = [11, 22, 33, 44, 55]
# 将此列表索引为奇数位对应的元素全部删除.
方法一:
l1 = [11, 22, 33, 44, 55] del l1[1::2] print(l1)
方法二:
l1 = [11, 22, 33, 44, 55] new_l = [] for index in range(len(l1)): if index % 2 == 0: new_l.append(l1[index]) # print(new_l) l1 = new_l print(l1)
方法三:
l1 = [11, 22, 33, 44, 55] for index in range(len(l1)-1,-1,-1): if index % 2 == 1: l1.pop(index) print(l1)
错误示例: (因为删掉前面元素,后面元素会自动往左边移,改变了其本身索引)
循环一个列表时,不要改变列表的大小.这样会影响你最后的结果.
l1 = [11, 22, 33, 44, 55] for index in range(len(l1)): if index % 2 == 1: # index 奇数 l1.pop(index) print(l1) #[11, 33, 44]
例:dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3', 'name': 'alex'}
# 将字典中的key中含有k元素的所有键值对删除.
dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3', 'name': 'alex'}
for key in dic:
if 'k' in key:
dic.pop(key)
print(dic) #报错 dictionary changed size during iteration
dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3', 'name': 'alex'}
l1 = []
for key in dic:
if 'k' in key:
l1.append(key)
print(l1) #['k1', 'k2', 'k3']
for key in l1:
dic.pop(key)
print(dic) #{'name': 'alex'}
# 循环一个字典时,不能改变字典的大小,这样会报错.
五,集合set
回顾:字典特点:
1.key是唯一的.
2.key必须是可以哈希的(不可变数据类型:字符串,元组,数值)
3.key是无序的.
3.6中dict的元素有序是解释器的特点,不是python源码的特点.
xxx.py
Cpython -> 有序
Jpython -> 无序
集合set
实际上就是一种特殊的字典. 所有value都是None的字典,就是集合.
对比字典和集合的特点:
|
字典 |
集合 |
|
Key唯一 |
元素唯一 |
|
Key可以哈希 |
元素可以哈希 |
|
Key无序 |
元素无序 |
如何获取集合?
1.手动创建集合.
1.创建空集合
d = {} (字典)
创建空集合,只有一种方式:调用set函数.
S = set()
2.创建带元素集合
S = {1,2,3}
从可迭代对象中(字符串,列表,元组,字典)创建集合.
s = set(‘abc’)
S = set([1,2,3])
S = set((1,2,3))
S = set({‘name’:’Andy’,’age’:10})
2.通过方法调用
- > str -> list -> set
集合的操作:
查看集合可用的方法:
[x for x in dir(set) if not x.startswith(‘_’)]
['add', 'clear', 'copy', 'difference', 'difference_update', 'discard', 'intersection', 'intersection_update', 'isdisjoint', 'issubset', 'issuperset', 'pop', 'remove', 'symmetric_difference', 'symmetric_difference_update', 'union', 'update']
增:
add:如果元素存在,没有做任何动作.
删:
Pop() :依次从集合中弹出一个元素,如果集合为空,报错
Discard(ele) :从集合中删除指定的元素,如果不存在,什么都不执行
Remove(ele) :从集合中删除指定的元素,如果不存在,报错
Clear() :清空
集合的四大常用操作:
并集:union
交集:intersection
差集:difference
对称差:symmetric_difference
改(更新):
Update :用二者的并集更新当前集合
difference_update:用二者的差集更新当前集合
intersection_update:用二者的交集更新当前集合
symmetric_difference_update:用二者的对称差集更新当前集合
判断功能:
Isdisjoint:判断两个集合是否没有交集
Issubset:判断当前集合是否是后者的子集
Issuperset:判断后者是否是当前集合的子集
查
集合基本没有单独取其中元素的需求.
集合的使用场景:
1.判断一个元素是否在指定的范围之内.
2.方便数学上的集合操作.
并,交,差,对称差
有简化写法:
并:|
交:&
差:-
对称差:^
3.对序列数据类型中的重复元素进行去重
如果想遍历集合中的元素.
通常用for循环.
frozenset:冻结的集合
最大的特点:不可变.
['copy', 'difference', 'intersection', 'isdisjoint', 'issubset', 'issuperset', 'symmetric_difference', 'union']
少了添加,更新的方法.
s = frozenset()
s = frozenset('abcabc')
s = frozenset([1,2,3])
s = frozenset((1,2,3))
s = frozenset({'name':'Andy','age':10})
集合的四大方法:并,交,差,对称差.
set,frozenset是否可以混用?
可以!
总结:
如果两种数据类型混用,方法的主调者的类型决定了最终结果的类型.
frozenset应用场景:
凡是使用到不可改变的数据的场景,都是可以使用frozenset的.
set集合的元素:必须是可以哈希的,set本身不是可以哈希.
但是frozenset是不可变的数据.(可以哈希的),它是可以放到集合中.
set和frozenset可以互相转换.