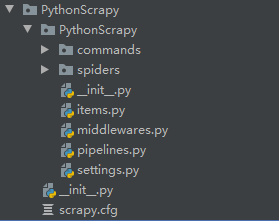
1.爬虫项目厂创建成功后大致的目录结构如下:
commands:大家可以暂时不给予考虑,这是在一个scrapy框架中 启动多个爬虫的解决方案 ,大家有需要 请关注本博客的动态
spider:是编写爬虫逻辑的文件存放出
items:是定义需要爬去的字段内容
middlewares:中间件的使用
piplines:管道
setting:配置文件(配置数据库 设置文件存放地址 以及其他高级设置)
编写爬虫我自己的思路是:
1.先分析 需要爬区的目标网站(找到那些信息 我们是需要的)
2.技术选型---(1.是同个网站爬去多个页面 还是爬去多个网站 2.目标网站是否启用了boot 3....) 关注跟多 请留意本博客的相关动态
2.1 那些字段 字段如何定义
2.2 抓回来的数据怎么存放 存放在哪里
2.3.....
接下来:
1.在item中定义自己需要爬去的字段
2.在配置文件中 配置号自己需要存放的数据相关信息
3.开始写爬虫
看下第一爬虫逻辑的编写:
import scrapy
from ..items import PythonscrapyItem
import re
class CsdnspiderSpider(scrapy.Spider):
# Authname=str(input())
name = 'csdnspider'
allowed_domains = ["blog.csdn.net"]
# start_urls ='https://blog.csdn.net/'+Authname
start_urls ='https://blog.csdn.net/testManger/article/list/'
custom_settings = {
'ITEM_PIPELINES': {'PythonScrapy.pipelines.PythonscrapyPipeline': 300},
}
def start_requests(self):
for i in range(1,11):
yield scrapy.Request(url=self.start_urls+str(i),callback=self.parse)
# offset=1
# start_urls=[start_urls+'/article/list/'+str(offset)]
def parse(self, response,):
for articlitm in response.css('.article-item-box'):
item=PythonscrapyItem()
Ariticle_title_list=articlitm.css('.article-item-box>h4>a::text').extract()
Ariticle_title_list_str=''.join(Ariticle_title_list)
item['Ariticle_title']=Ariticle_title_list_str.strip().replace(' ','').replace(' ','').replace('','').replace('','').replace('\','')
item['Ariticle_Browes_count']=articlitm.css('p>span:nth-child(2)::text').extract()
item['Ariticle_remark']=articlitm.css('.info-box>p>span+.read-num+.read-num::text').extract()
yield item
item中定义的字段:
class PythonscrapyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Ariticle_title=scrapy.Field()
Ariticle_Browes_count=scrapy.Field()
Ariticle_remark=scrapy.Field()
setting中配置的相关信息:(除了这些 还有一些必要的 这里就不展开讲,太多 太多可以设置的东西)
# mongdb
MONGODB_URI = 'mongodb://127.0.0.1:27017'
MONGODB_SERVER= "127.0.0.1"
MONGODB_PORT=27017
MONGODB_DB = "djangocsdn" # 库名
MONGODB_COLLECTION= "mon_csdn_col" # 集合(表)
# redis
REDIS_URL = 'redis://127.0.0.1:6379'
REDIS_SERVER = "127.0.0.1"
REDIS_PORT = 6379
REDIS_DB = 0 # 指定连接的库,0代表索引为0的库
MY_REDIS='keynamenew:keyvalue' #redis数据表中的myspider文件夹下的urls列表
#mysql
MYSQL_HOST = "localhost"
MYSQL_DBNAME ="django2"
MYSQL_USER = "root"
MYSQL_PASSWORD = "123456"
piplines中的代码处理 item中数据存放到数据库中、(只展示mysql的 redis mogodb只需要简单修改)
class PythonscrapyPipeline(object):
def __init__(self):
self.msqlcon = pymysql.connect(host=settings.MYSQL_HOST, user=settings.MYSQL_USER,
password=settings.MYSQL_PASSWORD, db=settings.MYSQL_DBNAME)
self.mysqlcur =self.msqlcon.cursor()
def process_item(self, item, spider):
# .strip(' ')
insert_sql='insert into spidercsdn values("%s","%s","%s")'%(item['Ariticle_title'].strip(),item['Ariticle_Browes_count'][0].lstrip(),item['Ariticle_remark'][0].lstrip())
print(insert_sql)
self.mysqlcur.execute(insert_sql)
self.msqlcon.commit()
def closesprider(self,spider):
self.mysqlcur.close()
self.msqlcon.close()
然后开始启动爬虫:
scrapy crawl csdnspider(这里需要进入 到存放编写spider逻辑的文件夹下 执行不然会说找不到)
那么在看一下爬去回来存放在数据库中的数据:
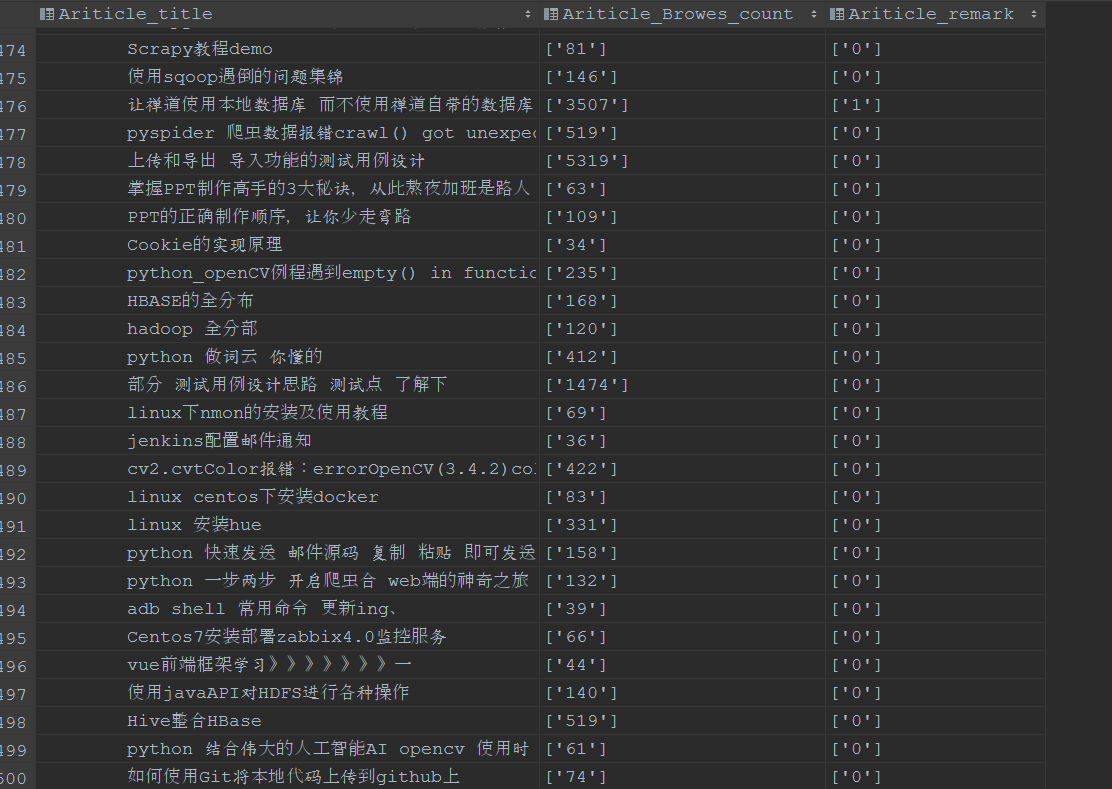
额外的一点小福利:
大家以后可以不用下载什么mysql可视化工具 直接在pycharm中直接可以看到 目标数据库中的相关数据 缺点:只能看单个数据库 (大家留意本博客的相关信息 后期会出一些关于pycharm连接各种数据的相关知识)