作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
HDFS:进行分布式计算平台,将多台节点的内容进行汇总分析。
MapReduce:
1、功能:用于处理和生成大规模数据集的相关的实现,将数据切割成数据块分批处理。
2、工作原理:用户定义一个map函数来处理一个Key-Value对以生成一批中间的Key-Value对,再定义一个reduce函数将所有这些中间的有相同Key的Value合并起来,MapReduce模型主要有Mapper和Reducer,Mapper端主要负责对数据的分析处理,最终转化为Key-Value的数据结构;Reducer端主要是获取Mapper出来的结果,对结果进行统计。即分而治之的策略:
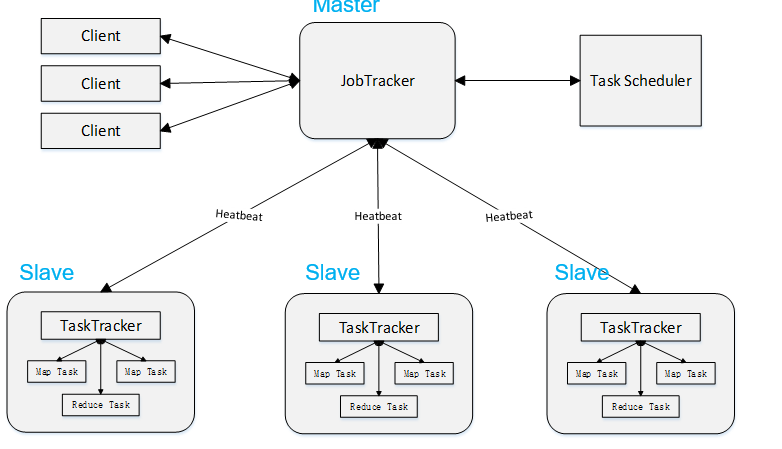
3、工作过程:
将分析的文件切割成多个数据块,将其分配给各个节点处理,每个节点又把数据块分给多个map处理,接着多个map将结果发送给shuffle处理,shuffle再将其交给reduce,最终将其写入到分布式系统文件。
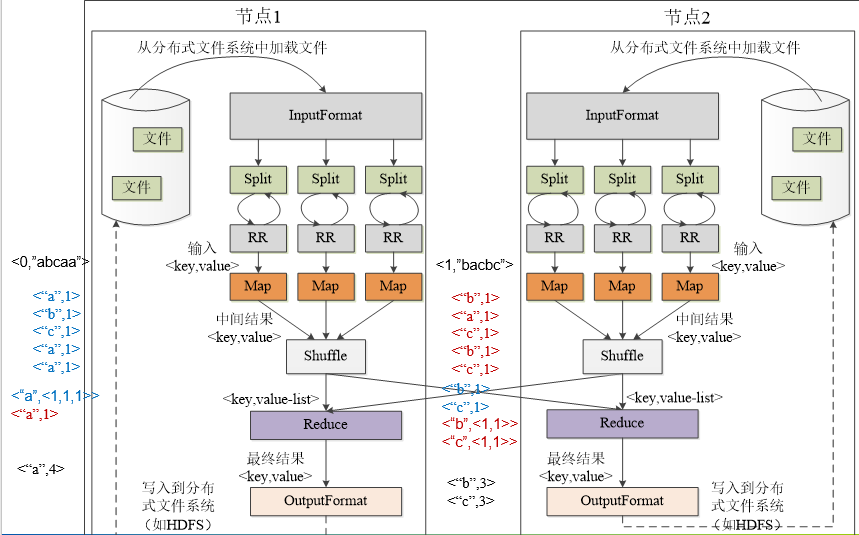
2.HDFS上运行MapReduce
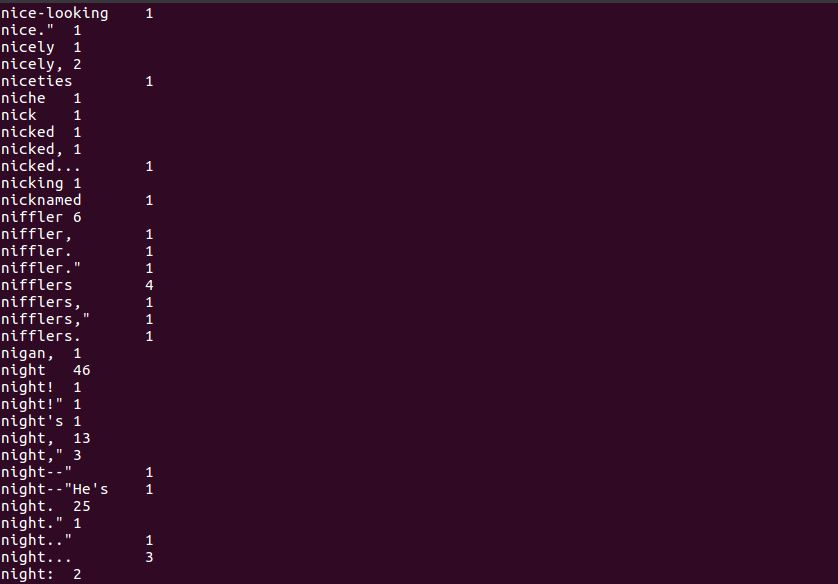
1)查看是否已经安装python:

2)在/home/hadoop/路径下建立wc文件夹,在文件夹内新建mapper.py、reducer.py、run.sh和文本文件HarryPotter.txt:

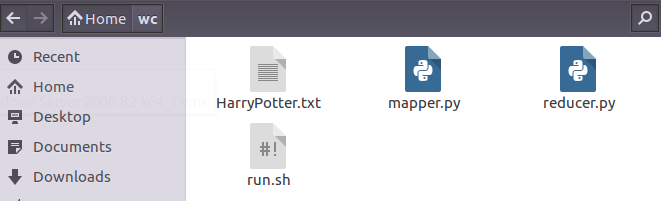
3)查看mapper.py reducer.py run.sh的内容:
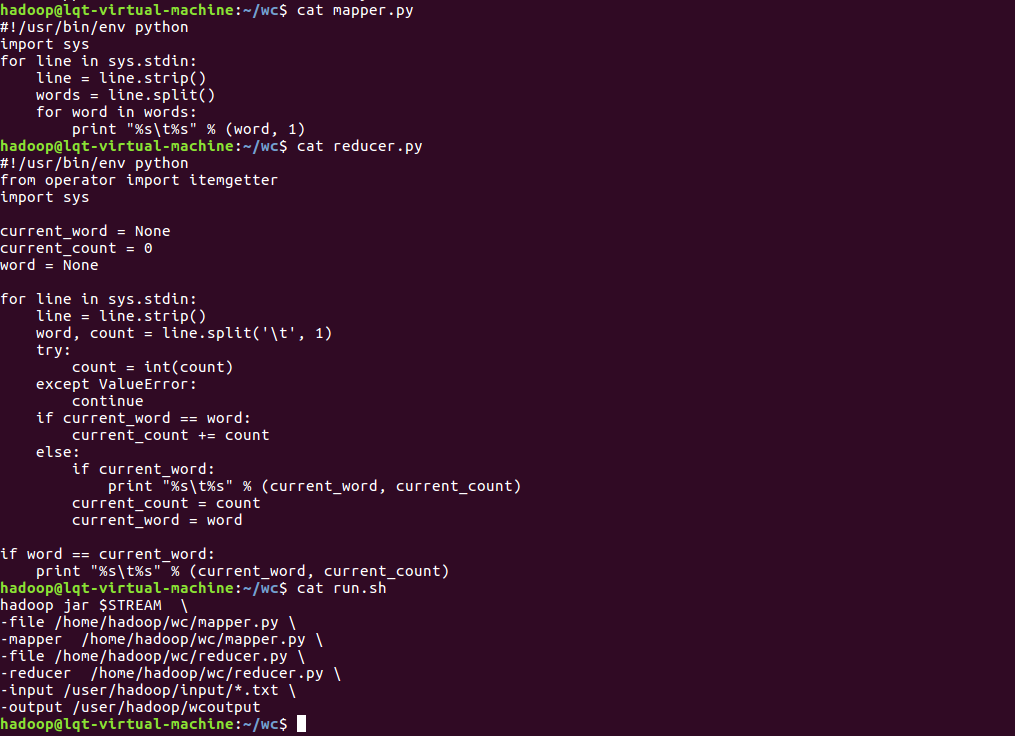
4)修改mapper.py和reducer.py文件的权限:

5)测试mapper.py和reducer.py:


6)启动hadoop:

7)把文本文件上传到hdfs:

8)将hadoop-streaming-2.7.1.jar的路径添加到bashrc文件并且让环境变量生效:


9)运行run.sh文件统计文本: