参考:https://www.cnblogs.com/liulinghua90/p/9935642.html
一、安装第三方库xlrd和pandas
1:pandas依赖处理Excel的xlrd模块,所以我们需要提前安装这个,安装命令是:pip install xlrd
2:步骤1准备好了之后,我们就可以开始安装pandas了,安装命令是:pip install pandas
数据准备,有一个Excel文件:格式为 xls 或 xlsx 或 xlt,表单名分别为:学生信息,人员信息,采购信息
其中人员信息 的表单数据如下所示:
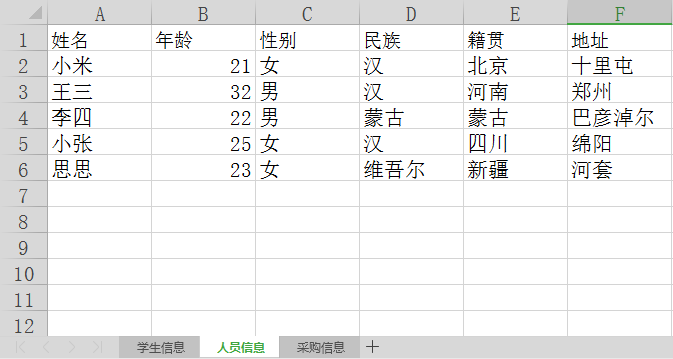
首先导入模块:
import pandas as pd
2:读取Excel文件的几种方式:
#方法一:默认读取第一个表单 df=pd.read_excel('lemon.xlsx') #默认读取前5行的数据 data=df.head() print("获取到所有的值: {0}".format(data)) #格式化输出
#方法二:通过指定表单名的方式来读取 #可以通过sheet_name来指定读取的表单 df=pd.read_excel('lemon.xlsx',sheet_name='人员信息') data=df.head() print("获取到所有的值: {0}".format(data))#格式化输出
#方法三:通过表单索引来指定要访问的表单,0表示第一个表单 #也可以采用表单名和索引的双重方式来定位表单 #也可以同时定位多个表单,方式都罗列如下所示 df=pd.read_excel('lemon.xlsx',sheet_name=['python','student']) #可以通过表单名同时指定多个 # df=pd.read_excel('lemon.xlsx',sheet_name=0) #可以通过表单索引来指定读取的表单 # df=pd.read_excel('lemon.xlsx',sheet_name=['python',1]) #可以混合的方式来指定 # df=pd.read_excel('lemon.xlsx',sheet_name=[1,2]) #可以通过索引 同时指定多个 data=df.values #获取所有的数据,注意这里不能用head()方法哦~ print("获取到所有的值: {0}".format(data))#格式化输出
二、pandas操作Excel的行列
1 df1=pd.read_excel('201709.xls',sheet_name=0)
2 # data=df.head() #默认读取前5行的数据
3 #跳过表头从第二行开始读取,将每一行内容存放在列表中
4 #读取指定一行
5 data = df1.ix[0].values
6 #读取指定2、3、4行
7 data = df1.ix[[1,2,3]].values
8 print(data)
9 # 读取指定行列,即B2 单元格内容
10 data = df1.ix[0,1]
11 print("获取到所有的值:
{0}".format(data))
12 #输出姓名列全部内容,返回列表
13 print("输出姓名列内容
",df1['姓名'].values)
14 # 通过表单索引来指定要访问的表单,0表示第一个表单,1表示第二个表单
15 df2=pd.read_excel('201709.xls',sheet_name=1)
16 #读取第一行第二行第三行的姓名、年龄、籍贯 列的值,这里需要嵌套列表
17 data2 = df2.ix[[0,1,2],['姓名','年龄','籍贯']].values
18 #获取所有行的指定列
19 data2 = df2.ix[:,['姓名','年龄','籍贯']].values
20 #获取行号并打印输出
21 rows_count = df2.index.values
22 #获取列名并打印输出
23 cols_count = df2.columns.values
24 #获取指定行数的值(行是随机的)
25 print(df2.sample(3).values)
三:pandas处理Excel数据成为字典
1 df2=pd.read_excel('xiong.xls',sheet_name=1) 2 3 rows_data = [] 4 for i in df2.index.values: 5 row_data = df2.ix[i,['姓名','年龄','民族','籍贯']].to_dict() 6 rows_data.append(row_data) 7 8 print(rows_data)
最终打印结果:
[{'姓名': '小米', '年龄': 21, '民族': '汉', '籍贯': '北京'}, {'姓名': '王三', '年龄': 32, '民族': '汉', '籍贯': '河南'}, {'姓名': '李四', '年龄': 22, '民族': '蒙古', '籍贯': '蒙古'}, {'姓名': '小张', '年龄': 25, '民族': '汉', '籍贯': '四川'}, {'姓名': '思思', '年龄': 23, '民族': '维吾尔', '籍贯': '新疆'}]