参考文献:
https://juejin.im/post/5e817b886fb9a03c7d3cee7c#heading-7
https://juejin.im/post/5e6e0ac9e51d4526fb5df679
https://zhuanlan.zhihu.com/p/34280652
https://juejin.im/post/5c8f461c5188252da90125ba
目录
一、HashMap集合简介。
二、jdk1.7与jdk1.8中Hashmap的主要实现区别。
三、HashMap的put、get操作原理。
四、HashMap的扩容机制。
一、HashMap集合简介
(1) HashMap是Map接口的一个重要实现类,基于哈希表,以key-value的形式存储数据,线程不安全;
(2) null可以作为键,这样的键只能有一个,可以有一个或多个键对应的值为null;
(3) 存取元素无序。
二、jdk1.7与jdk1.8中Hashmap的主要实现区别
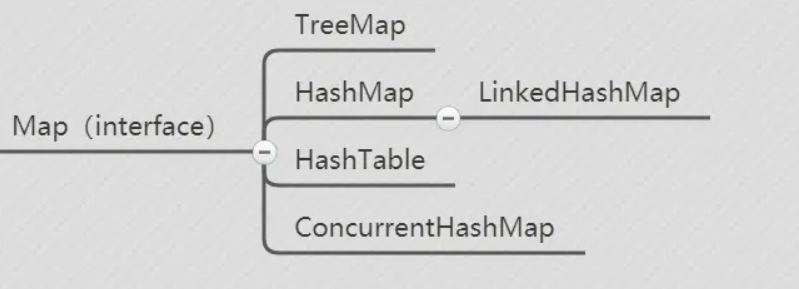
1.底层数据结构方面:
(1) JDK1.7,由数组+链表构成,数组是存储数据的主体,链表是为了解决哈希冲突而存在的;
(2) JDK1.8以后,由数组+链表+红黑树构成,当链表长度大于阈值(默认为8),并且数组长度大于64时,链表会转化为红黑树去解决哈希冲突。如果阈值大于8,但是数组长度小于64,这时链表不会转化为红黑树去存储数据,而是会对数组进行扩容(处于提高性能以及减少搜索时间的目的)。当红黑树结点个数小于等于6,则将红黑树转回为链表结构。
2.链表中数据插入方式:
(1) 在JDK1.7中,无论是发生哈希冲突插入链表元素还是扩容后再哈希转移老数据的方式HashMap中采用的链表插入方式都为头插法,头插法会出现逆序、环形链表、死循环等问题。
(2) 在JDK1.8中,无论是发生哈希冲突插入链表元素或插入红黑树元素还是扩容后转移老数据的方式HashMap中采用的链表插入方式都为尾插法。(注意JDK1.8中,HashMap扩容后无需使用重新哈希确定原数组元素的位置)
3.扩容后存储位置的计算方式
(1) JDK1.7中,扩容的时候需要对原数组中的元素进行重新hash定位在新数组的位置。
(2) JDK1.8中,则采用更简单的判断逻辑,位置不变或索引+旧容量大小。
4.插入数据方式
(1) JDK1.7中,先判断HashMap是否需要扩容,再插入数据。
(2) JDK1.8中,先进行插入数据,插入数据后再判断HashMap是否需要扩容;
其余诸如1.7中hash计算量比1.8中hash计算量大、1.8中新增了一些函数接口、1.8中,Entry被Node替代等等就不提了。
三、HashMap的put、get操作原理

1.put操作流程
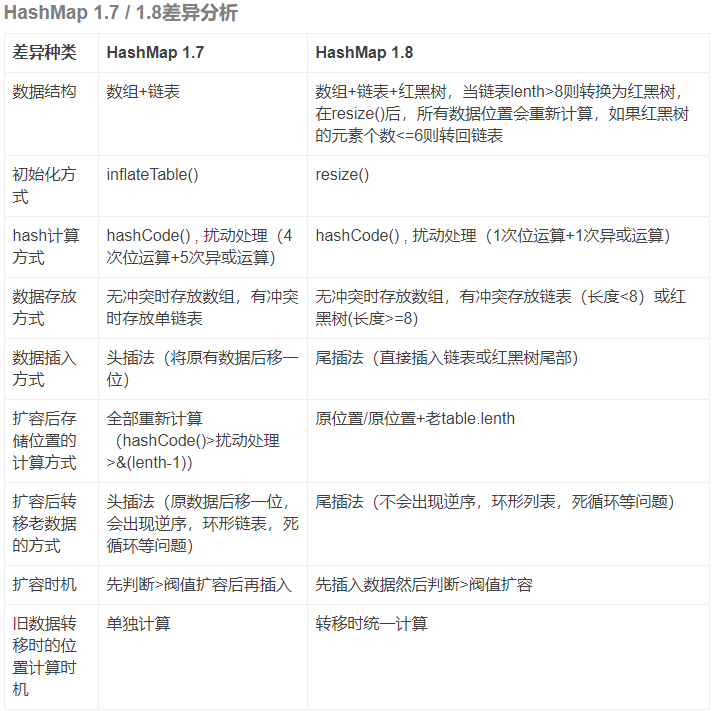
(1) 判断数组是否为空,为空进行初始化;
(2) 不为空,计算 key 的 hash 值,通过(数组长度n - 1) & hash计算应当存放在数组中的下标 index;
(3) 查看 table[index] 是否存在数据,没有数据就构造一个Node节点存放在 table[index] 中;
(4) 存在数据,说明发生了hash冲突(存在两个节点key的hash值一样), 继续判断key是否相等,相等,用新的value替换原数据;
(5) 如果不相等,判断当前节点类型是不是树型节点,如果是树型节点,创造树型节点插入红黑树中;
(6) 如果不是树型节点,创建普通Node加入链表中;判断链表长度是否大于 8以及数组长度是否大于64, 都大于的话链表转换为红黑树;
(7) 插入完成之后判断当前节点数是否大于阈值,如果大于开始扩容为原数组的二倍。
2.HashMap的初始化
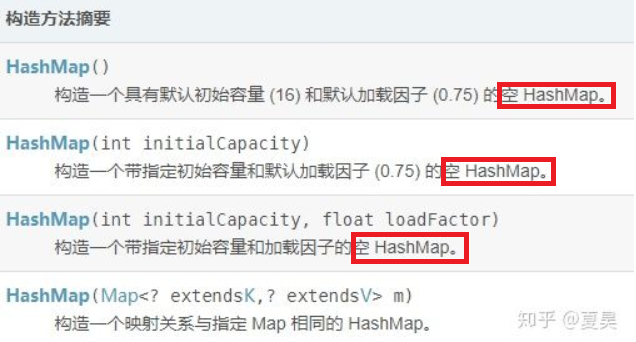
HashMap一共有4个构造函数,一般采用的都是无参构造函数,默认初始容量大小为16,负载因子是0.75。如果自己传入初始大小initialCapacity,初始化大小为 大于initialCapacity的最小2的整数次方,例如如果传10,大小则为16。源码通过右移运算与按位或运算完成。
注意:HashMap通过构造函数进行初始化的时候,是不开辟空间的,也就是HashMap为空,只有在第一次put(key,value)的时候,才会为HashMap开辟空间。

3.HashMap的哈希函数设计以及数组下标的求解
首先判断key值是否为null,如果key == null直接返回0;否则取key的hashcode值,是32位的int值,然后让hashcode的高16位和低16位进行异或操作。
从中也可以看出当key为null时候,该数据元素被放在table下标为0的位置。

(1) 为什么要通过hash函数计算hash值,而不是直接采用hashCode作为hash值呢?
计算hash值的hash函数也叫做扰动函数。将hashcode高位和低位的值进行混合做异或运算之后,低位的信息中加入了高位的信息,这样高位的信息被变相的保留了下来。可以减少哈希碰撞,使数据分配均匀。同时因为采用位运算,效率高。
(2) 为什么数组下标的求解采用(数组长度n - 1) & hash,而不是采用取模运算?
- 当数组长度n大小为2的整数次幂的时候,取模运算的结果等价于(数组长度n - 1) & hash,因为位运算比取模%运算要快。
- 同时使用【(数组长度n - 1) & hash】按位与操作进行下标求解可以减少哈希碰撞,使数据分配均匀。因为2的n次方-1就是n个1;比如2的4次方-1位15,二进制表示为1111。
4.为什么把链表转化为红黑树的阈值是8(同时要求数组长度大于64),红黑树变为链表的阈值是6?
红黑树节点所占空间是普通链表节点的两倍,但是红黑树的查找性能比链表好很多,所以只有当节点足够多的时候,才会将链表转换为红黑树(空间换时间)。
(1) 为什么不把链表全部换为红黑树呢?
- 链表的结构比红黑树简单,构造红黑树要比构造链表复杂,所以在链表的节点不多的情况下,从整体的性能看来,如果把链表全部换为红黑树,效率反而更低。
- HashMap频繁的resize(扩容),扩容的时候需要重新计算节点的索引位置,也就是会将红黑树进行拆分和重组,其实这是很复杂的,这里涉及到红黑树的着色和旋转,所以为链表树化设置一个阀值是非常有必要的。
(2) 那为什么阈值是8?
链表中存储数据的频率符合泊松分布,链表的长度超过8的概率非常非常小(6*10-8),链表长度很难达到8,当链表长度到达8的时候,如果数组长度小于64,首先进行扩容操作,如果数组长度大于64,此时哈希表中的容量很大,结点较多,造成链表性能很差,只能采用红黑树提高性能(利用空间换时间)。
(3)为什么红黑树变为链表的阈值是6?
选择6和8,中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
5.在put过程中,如果两个对象的 hashCode 相同会发生什么?
因为两个对象的hashCode相同,也就是两个对象的hash值相同,所以两个对象所在数组的下标相同,哈希碰撞就此发生。但是哈希碰撞(哈希冲突)不一定会产生Value值的覆盖,只有当哈希碰撞发生且(equals比较内容相同或者“==”操作返回true),才会发生后添加的value值覆盖之前的value值。否则插入链表或者红黑树。

6. get()操作流程
相比于put()方法,get()方法的实现就相对简单多了。主要分为两步,先是通过key的hash值计算目标bucket的下标,然后遍历对应bucket上的链表或者红黑树,逐个对比,得到结果。

四、HashMap的扩容机制
1.什么时候会产生扩容?
- 哈希table为null或长度为0;
- Map中存储的k-v对数量超过了阈值
threshold = 负载因子 * table的长度; - 链表中的长度超过了
TREEIFY_THRESHOLD(阈值一般为8),但哈希表长度却小于MIN_TREEIFY_CAPACITY(阈值64)。
2.HashMap扩容后的大小为多少?
是原来容量的2倍,即HashMap是以2*n进行扩容的。
3.为什么HashMap的容量必须是2的n次方?
因为在计算元素该存放的位置的时候,用到的算法是将对象的hash值与当前hashmap的容量大小-1进行与运算。如果hashmap的长度为2的幂次,那长度-1的二进制一定为11111...这种形式,进行与运算就只需要观察元素的hash值即可,但是如果hashmap的长度不是2的幂次,则会造成hash表中某几个位置就永远都不能存放元素,空间浪费相当大,同时也增加了添加哈希冲突的几率,减慢了查询效率。所以Hashmap的容量是2的幂次。
例子:比如为15,那长度-1就是14,二进制为1110,无论与谁相与最后一位一定是0,0001,0011,0101,1001,1011,0111,1101这几个位置就永远都不能存放元素了,空间浪费相当大。也增加了添加元素是发生碰撞的机会。减慢了查询效率。所以Hashmap的大小是2的幂次。
- 有利于提高计算元素存放位置时的效率,也降低了hash冲突的几率,使数据分配均匀。就算HashMap构造函数传递进来一个不是2次方的数,内部也会通过位运算找到大于或等于 cap 的最小2的幂,来设置给容器。
- 还有一种说法,一般计算哈希值映射数组下标都是采用取模运算,然而取模运算的效率较慢,jdk1.8采用了按位与的操作,然而取模运算(hash%n)的结果等价于【(数组长度n - 1) & hash】按位与操作的前提是数组长度n大小为2的整数次幂。
4.扩容的大致过程
HaspMap扩容就是就是先计算新的hash表容量(是原来容量的两倍)和新的容量阀值,然后初始化一个新的hash表,将旧的键值对重新映射在新的hash表里。旧的键值对在新的hash表中的位置只有两种,原下标位置或原下标+旧数组的大小。这里实现的细节当然没有我说的那么简单,如果在旧的hash表里涉及到红黑树,那么在映射到新的hash表中还涉及到红黑树的拆分。
5.扩容的时候为什么不用重新hash就可以直接定位原节点在新数据的位置呢?
这是由于扩容是扩大为原数组大小的2倍,用于计算数组位置的掩码仅仅只是高位多了一个1.扩容前长度为16,用于计算(n-1) & hash 的二进制n-1为0000 1111,扩容为32后的二进制就高位多了1,为0001 1111。因为是& 运算,1和任何数 & 都是它本身,那就分二种情况:原下标位置或原下标+旧数组的大小