李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube、网易云课堂、B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对这些知识内容的理解与补充。(本笔记配合李宏毅老师的视频一起使用效果更佳!)
Lecture 8:Why deep?
1.Shallow network VS Deep network
在比较浅层网络与深层网络时,要让“矮胖”的网络和“高瘦”的网络的参数数目相等,这样比较才公平,如下图所示
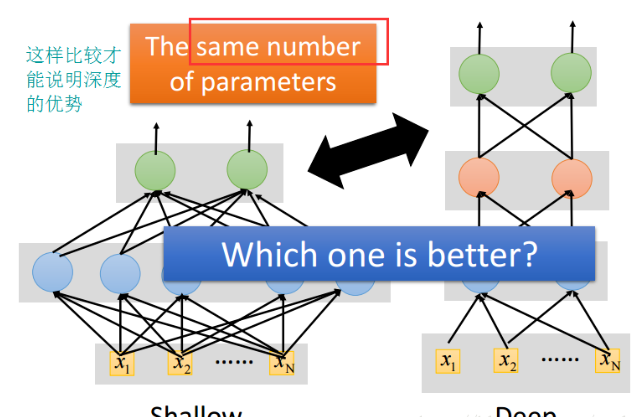
比较结果如下图所示:
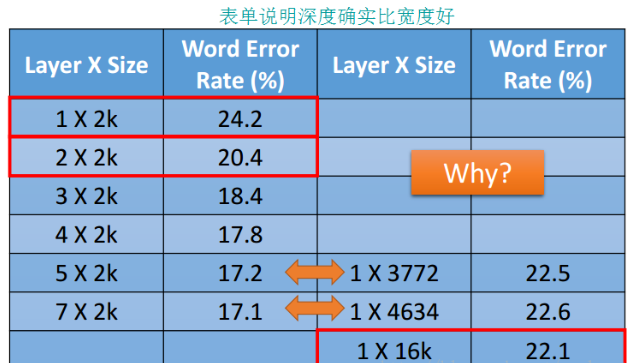
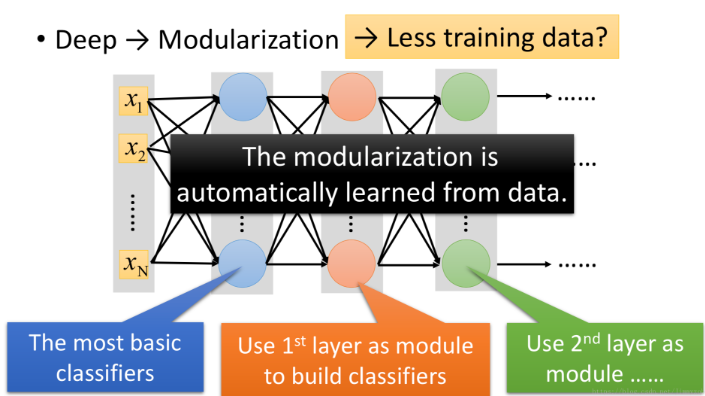
从上图可以看出:即便是在深层网络参数较少的情况下,深层网络也会比浅层网络表现好。 这是因为“深层”其实相当于“模组化”,第一个隐层是最基本的分类器,第二个隐层是用第一个隐层建造的分类器,以此类推。
2.模组化(Modularization)
(1)举个图像识别的例子,识别长发男生、长发女生、短发男生和短发女生,如下,由于长发男生样本少,所以模型训练出来的效果对测试集上的长发男生效果会比较差(样本不平衡)
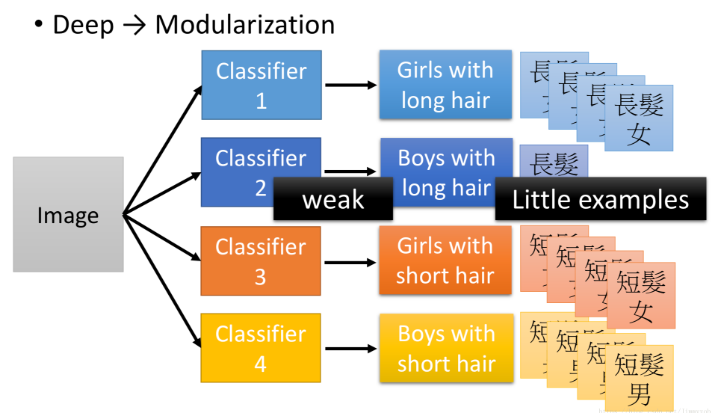
因此接下来让我们使用模组化的思想解决这一问题,我们先考虑识别基础类别(男女、长发短发),即我们先input一张图片,识别这是长发还是短发,这是男还是女,此时样本比例是相当的,由此训练的效果不会变差,且由两个基础类别的组合可以得到最终的四个类别。
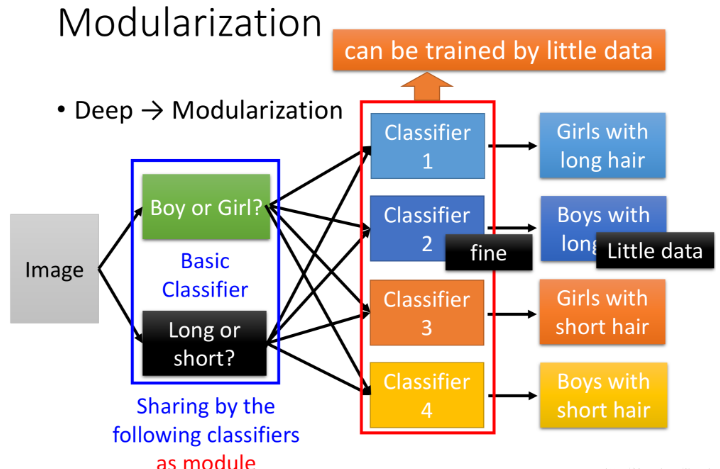
深度学习的优势就体现在模组化的处理方式,第二层的神经元把第一层的神经元当作modile,第三层的神经元把第二层的神经元当作module(具体module由算法自动学习)。此时复杂的问题变成简单问题,深度学习需要的数据比较少。
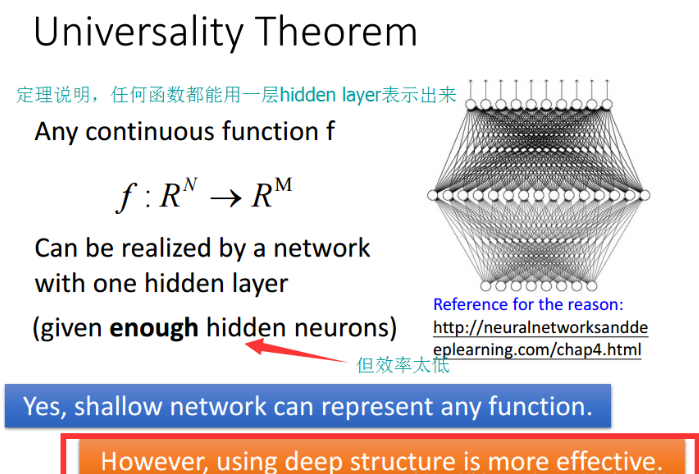
3.浅层网络确实可以表示任意函数,但是使用深层结构更有效率
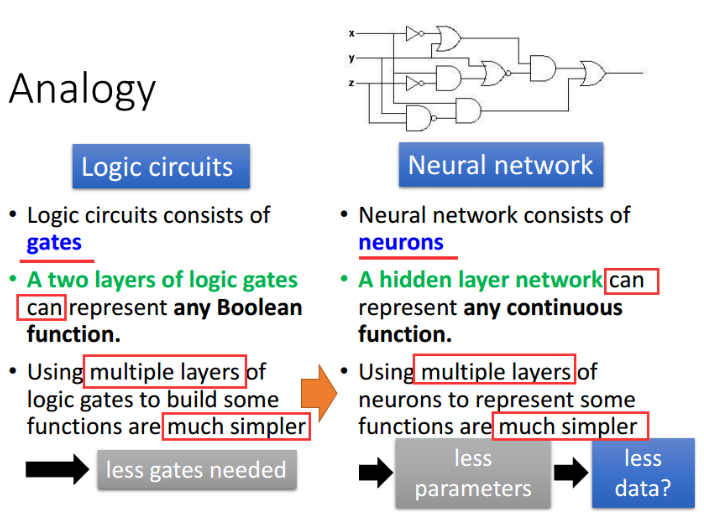
具体可以通过逻辑门电路例子来解释这个理论:用两层逻辑门就可以实现任何布尔函数,但是用多层结构更简单、需要的逻辑门更少,更少的逻辑门代表着更高的效率
4.最后,在本节课老师采用了语音识别,MNIST数据集识别等例子再次证明和强调了Why Deep?和Deep带来的好处!
Lecture 9:Semi-supervised
1.Introduction

(1)半监督学习的训练数据,有一部分是标注数据,有一部分是无标注数据。
(2)Transductive learning和Inductive learning都可算是半监督学习,区别在于前者的无标注数据是测试数据(除去label),而后者的无标注数据不包括测试数据。实际中用哪种常取决于是否有测试集。
(3)无标注数据的分布会让我们做出一些假设,半监督学习有没有用就取决于假设是否合理。
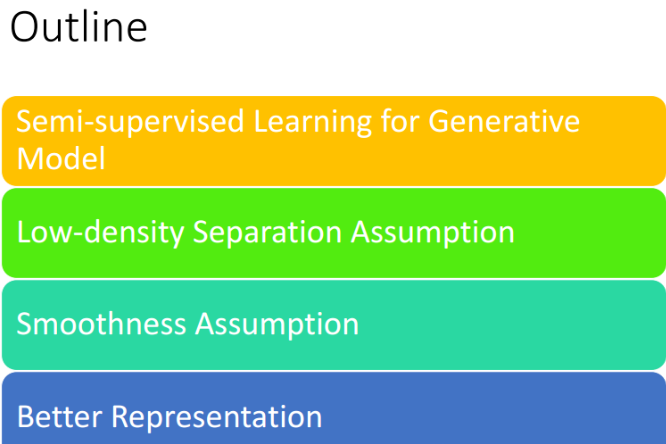
(4)介绍半监督学习的大纲:如下图所示
2.Semi-supervised Learning for Generative Model
(1)先让我们看看监督学习和半监督学习的生成模型的对比,(Supervised Generative Model VS Semi-supervised Generative Model)
监督学习:

非监督学习:

从上图可以看出,无标注数据有助于重新估计生成模型假设中的参数,从而影响决策边界
(2)求解模型采用的方法
求解该模型采用的是EM算法,EM算法也是机器学习十大算法之一,求解步骤如下图所示:

3.Low-density Separation Assumption
(1)之前提过半监督学习有没有用很大一部分就取决于假设是否合理,现在让我们了解一下第一个假设“低密度分离”--------非黑即白。
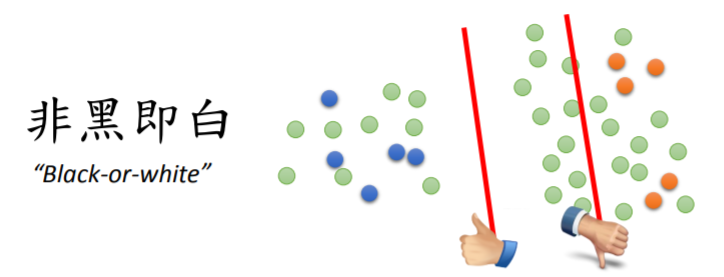
(2)该假设的应用过程如下:

- 给你一堆初始数据,该数据包括有标记和无标记的
- 从有标记的数据中训练出一个模型f*.
- 从数据中选出一些无标记的数据,将这些数据扔入模型f*中,将得到的结果赋予这些无标记的数据的标签,然后将这些数据从无标记数据集中删除并加入有标记的数据集中,重复此过程。
(3)Self-training结果优化:如果神经网络的输出是一个分布,我们希望这个分布要集中

4.Smoothness Assumption(第二个假设)
(1)核心思想:假设特征的部分是不均匀的(在某些地方集中,某些地方分散),如果两个特征在高密度区域是相近的,那么二者的标签是相同的。

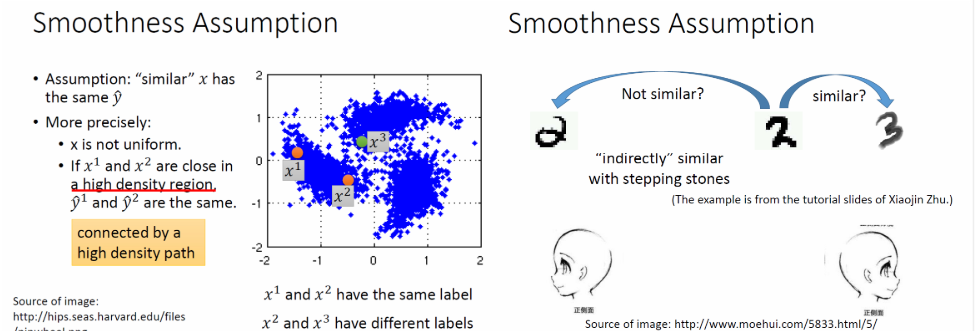
就拿上图数字辨识的例子来看,可以通过一条high density path完成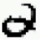 ------->
------->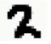 的转变
的转变
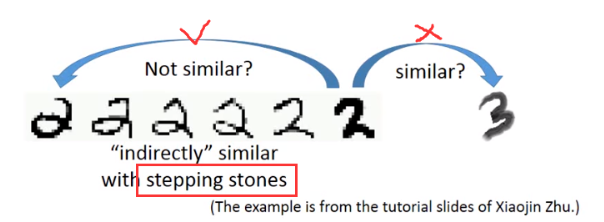
(2)如果数据量很大,如何做到确定这条high density path呢?
Cluster(群集):
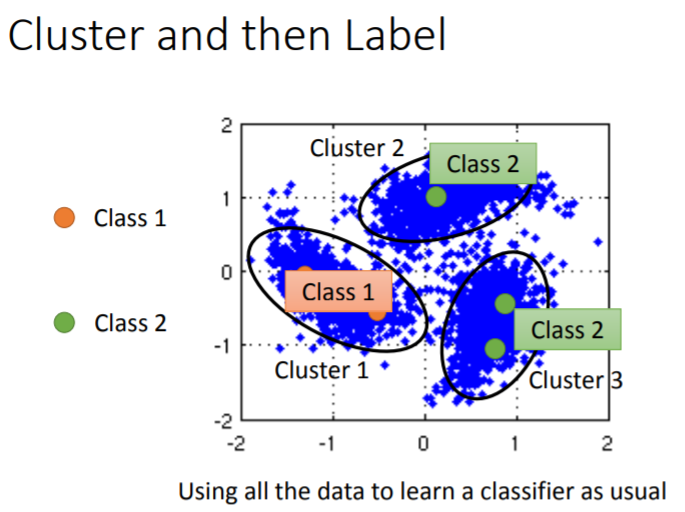
这种方法有明显的缺点:它只适用于每个class的分类较为清晰。所以引入另外一种办法
Graph-based Approach
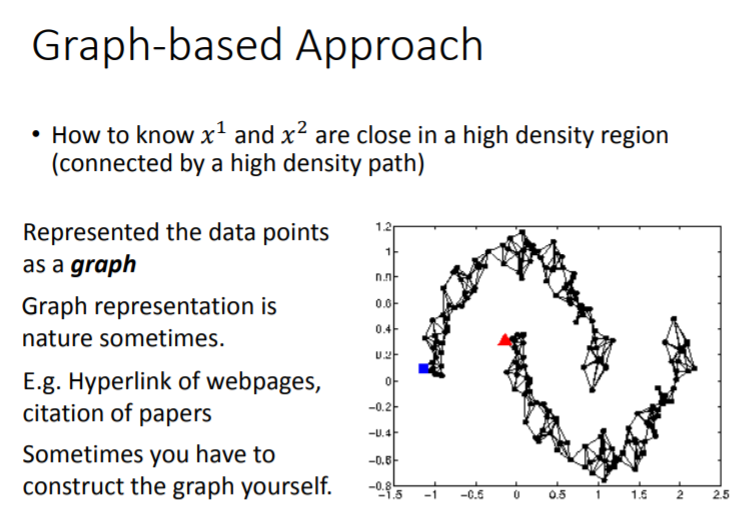
1)如何构建这个图呢?

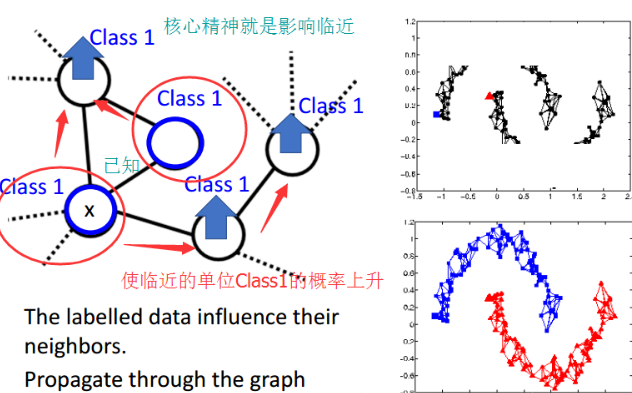
2)如何在图中定量的表示平滑度呢?
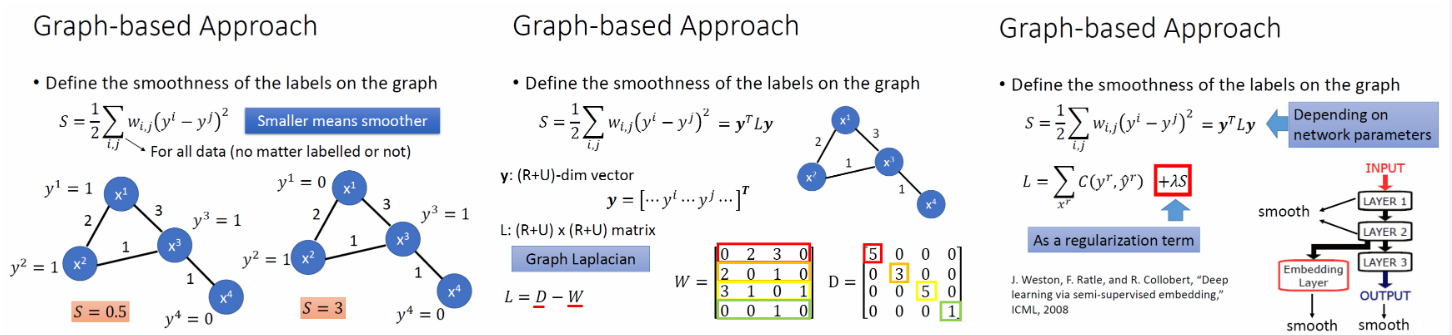
其中,smoothness不一定要放在output上,放到任何一层都可以。
5.Better Representation
该部分的学习放到无监督学习中!!
课件pdf参考: https://blog.csdn.net/soulmeetliang/article/details/73251790
以上就是本次学习的内容,欢迎交流与讨论