《使用Hibernate开发租房系统》内部测试笔试题
一、选择题(共25题,每题2.5分,选择一项或多项,漏选错选不得分)
1.在Hibernate中,以下关于主键生成器说法错误的是(C )。
A.increment可以用于类型为long、short或byte的主键
B.identity用于如SQL Server、DB2、MySQL等支持标识列的数据库
C.sequence用于如Oracle、SQL Server等支持序列的数据库
D.native由Hibernate根据底层数据库自行判断采用何种主键生成策略,是由使用的数据库生成主键的值

2.在Hibernate中,关于脏检查和刷新缓存说法正确的是( AB)。
A.当事务提交时,会发生脏检查
B.Session的flush( )方法是刷新缓存的方法
C.在执行Session的commit( )方法之前不会调用Session的flush( )方法
D.编写代码时,调用commit( )方法之前要调用flush( )方法
3.使用HQL查询所有部门信息,以下正确的是(AD )。
A.from Dept
B.select * from cn.jbit.demo.entity.Dept
C.select Dept from cn.jbit.demo.entity.Dept d
D.select d from Dept d
4.关于Query接口的list( )和iterate( )方法,说法正确的是(AD )。
A.执行list( )方法,查询所有符合条件的记录
B.执行iterate( )方法,查询所有符合条件的记录
C.执行list( )方法,查询出所有符合条件的主键值
D.执行iterate ( )方法,查询出所有符合条件的主键值
5.在HQL中,关于Query接口绑定参数的方法,说法正确的是(ABCD )。
A.setParameter( )方法用于绑定任意类型的参数
B.setParameter( )有重载的方法
C.setProperties( )有重载的方法
D.setProperties( )方法用于绑定命名参数
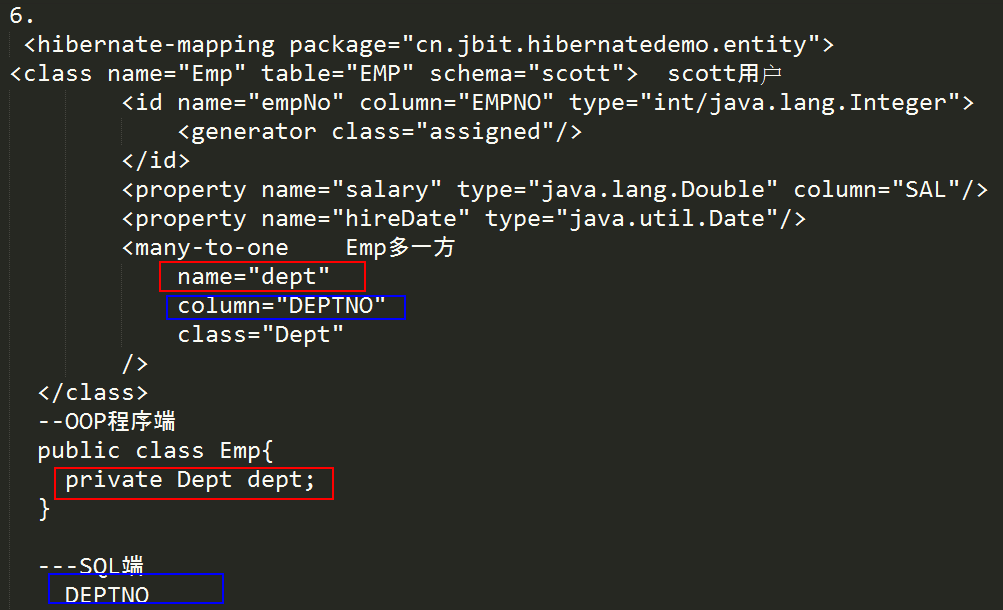
6.在Hibernate中,关于以下映射配置,说法错误的是(D )。
<hibernate-mapping>
<class name="cn.jbit.hibernatedemo.entity.Emp" table="EMP" schema="scott">
<id name="empNo" column="EMPNO" type="java.lang.Integer">
<generator class="assigned"/>
</id>
<property name="salary" type="java.lang.Double" column="SAL"/>
<property name="hireDate" type="java.util.Date"/>
<many-to-one
name="dept"
column="DEPTNO"
class="cn.jbit.hibernatedemo.entity.Dept"
/>
</class>
</hibernate-mapping>
A.此配置信息描述了cn.jbit.hibernatedemo.entity.Emp类和EMP表的映射
B.描述的是scott用户的EMP表
C.<many-to-one>标签中的name属性值dept是cn.jbit.hibernatedemo.entity.Emp类的属性名
D.<many-to-one>标签中的column属性值DEPTNO是dept表的主键名
7.在Hibernate映射文件中,关于inverse属性说法正确的是(ACD )。
A.inverse属性有两个值:true、false
B.<many-to-one>标签有inverse属性
C.<set>标签有inverse属性
D.inverse属性用于指定维护关联关系的那一方
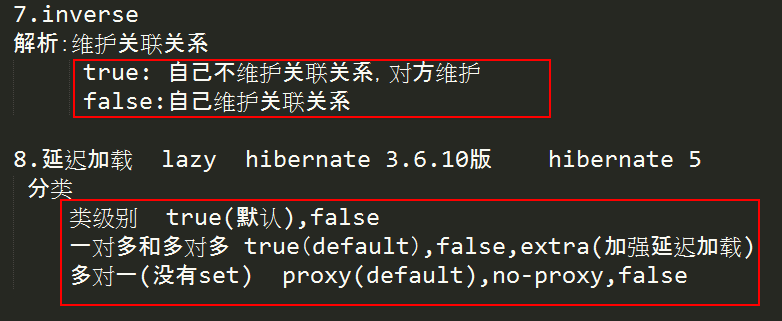
8.在Hibernate映射文件中,关于延迟加载配置说法错误的是(BD )
A.<class>标签中lazy属性可选值:true、false
B.<set>标签中lazy属性可选值:true、proxy和no-proxy
C.< set>标签中lazy属性可选值:true、extra和false
D.<many-to-one>标签中lazy属性可选值:proxy、true和false
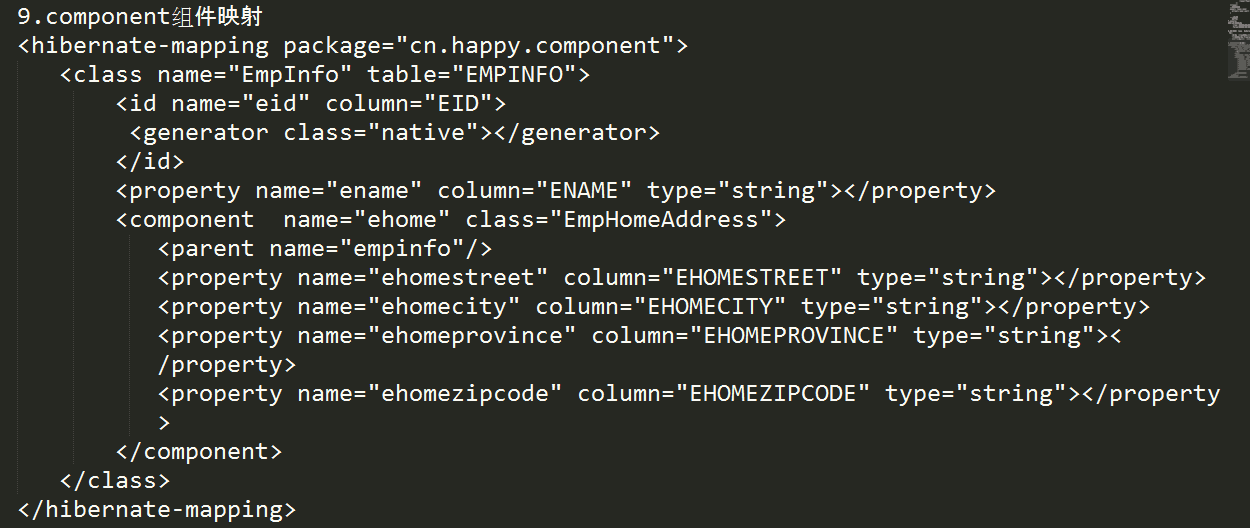
9.在Hibernate映射文件中,关于<component>标签说法正确的是(ABC )。
A.<component>标签用来映射组件类
B.<component>标签通过<parent>指定组件类所属的整体类
C.<component>标签通过<property>指定组件类的属性
D.<component>标签有id、name、class属性
10.MyBatis指定配置文件的根元素使用的是(B )。
A.<sqlMapConfig>
B.<configuration>
C.<setting>
D.<environments>
11.在MyBatis中,ExecutorType的值包括(ABD )。
A.ExecutorType.SIMPLE
B.ExecutorType.BATCH
C.ExecutorType.EXECUTE
D.ExecutorType.REUSE
解释:
一个意外 ExecutorType
public final enum org.apache.ibatis.session.ExecutorType {
// Field descriptor #8 Lorg/apache/ibatis/session/ExecutorType;
public static final enum org.apache.ibatis.session.ExecutorType SIMPLE;
// Field descriptor #8 Lorg/apache/ibatis/session/ExecutorType;
public static final enum org.apache.ibatis.session.ExecutorType REUSE;
// Field descriptor #8 Lorg/apache/ibatis/session/ExecutorType;
public static final enum org.apache.ibatis.session.ExecutorType BATCH;
12.关于Hibernate缓存说法错误的是(CD )。
A.Hibernate缓存一般分为三类:一级缓存、二级缓存和查询缓存
B.Session的evict( )方法用于从缓存中清除指定的持久化对象
C.Session的clear( )方法用于刷新缓存
D.Session的flush( )方法用于从缓存中清除所有持久化对象
13.关于HQL的连接查询,说法错误的是(D )。
A.inner join 或 join用于内连接
B.inner join fetch或 join fetch用于迫切内连接
C.left outer join fetch 或 left join fetch用于迫切左外连接
D.right outer join fetch 或 right join fetch用于迫切右外连接

14.关于Hibernate批量处理数据说法正确的是(CD )。
A.使用HQL进行批量操作,Hibernate不支持批量插入
B.使用JDBC API进行批量操作,SQL语句中涉及的数据会被加载到Session缓存,占用内存空间
C.使用Session进行批量操作,数据会被加载到Session缓存,需注意刷新并清空缓存
D.使用Session进行批量操作,适用于需要通过代码处理的复杂的业务逻辑场景
解释:批量处理数据
方式一:
使用HQL语句
原理: executeUpdate
01.批量插入数据
@Test
public void testInsert(){
Session session = HibernateUtil.getSession();
Transaction tx=session.beginTransaction();
String hql="insert into Dept(deptName) select d.deptName||d.deptNo from Dept d where d.deptNo>0";
session.createQuery(hql).executeUpdate();
tx.commit();
}
方式二:JDBCAPI
//使用JDBC API进行批量修改
public void testUpdateUseJDBC(){
Session session = HibernateUtil.getSession();
Transaction tx=session.beginTransaction();
Work work=new Work() {
@Override
public void execute(Connection connection) throws SQLException {
String sql="update DEPTY2160New set deptName=? where deptNo>?";
PreparedStatement ps = connection.prepareStatement(sql);
ps.setString(1, "财务部2");
ps.setInt(2, 1);
ps.executeUpdate();
}
};
session.doWork(work);
tx.commit();
}
方式三: 使用Session进行批量操作
public void testAdd(){
Session session = HibernateUtil.getSession();
Transaction tx=session.beginTransaction();
Emp emp=null;
for (int i = 0; i < 10000; i++) {
emp=new Emp(i, "emp"+i);
session.save(emp);
if (i%30==0) {
session.flush();
session.clear();
}
}
tx.commit();
}
little tip:
(1)使用HQL进行批量操作 数据库层面 executeUpdate()
(2)使用JDBC API进行批量操作 数据库层面
(3)使用Session进行批量操作 会进缓存
little tip2:
C.使用Session进行批量操作,数据会被加载到Session缓存,需注意刷新并清空缓存
D.使用Session进行批量操作,适用于需要通过代码处理的复杂的业务逻辑场景
15.关于HQL的聚合函数使用,说法正确的是(ABCD )。
A.select count(*) from Dept d用于统计部门个数
B.select sum(e.salary) from Emp e用于汇总员工工资总额
C.select max(e.hiredate) from Emp e用于找到最新入职的员工的入职时间
D.select min(e.hiredate) from Emp e用于找到最早入职的员工的入职时间
解释:HQL面向的是对象和属性,不是表和字段
16.关于HQL子查询中,说法错误的是(C )。
A.size( )或size用于获取集合中元素的数目
B.elements( )获取集合中的所有元用于素
C.any关键字用于子查询语句返回所有记录
D.in关键字与“=any”意思相同
17.关于原生SQL查询和命名查询,说法正确的是(ABC )。
A.执行原生SQL,需使用SQLQuery对象
B.SQLQuery是一个接口,继承了Query接口
C.Hibernate支持在映射文件中定义字符串形式的查询语句,这样的语句是命名查询语句
D.命名查询语句只能是HQL语句,不能是SQL语句
解释:原生SQL查询和命名查询
Query query=session.createQuery(hql)
SQLQuery query=session.createSQLQuery(sql)
1.原生SQL查询
@Test
//原生SQL执行
public void testClassicSQL(){
SQLQuery query = session.createSQLQuery("select * from deptY2160new").addEntity(Dept.class);
List<Dept> list = query.list();
for (Dept dept : list) {
System.out.println(dept.getDeptName());
}
tx.commit();
}
2.命名查询
<!-- -原生SQL NullPointException -->
<sql-query name="selectEmpByDetpNoClassicSQL">
<return alias="e" class="Emp" ></return>
select {e.*} from EmpY2160new e where deptNo=:deptNo
</sql-query>
测试类
public void testNamedClassicSQL(){
Query query = session.getNamedQuery("selectEmpByDetpNoClassicSQL");
List<Emp> list = query.setParameter("deptNo", 1).list();
/* for (Emp emp : list) {
System.out.println(emp.getEmpName());
}*/
tx.commit();
}
18.在 Hibernate中,关于映射Oracle中的BLOB和CLOB类型的方法,说法正确的是(BCD )。
A.CLOB类型只能映射为java.lang.String
B.BLOB类型可以映射为java.sql.Blob
C.BLOB类型可以映射为byte[]
D.CLOB类型可以映射为java.lang.String或java.sql.Clob
19.在Hibernate中,关于Criteria运算方法说法错误的是(CD )。
A.Restrictions.ge( )方法等同于HQL运算符 >=
B.Restrictions.like("empName","s",MatchMode.START)方法用于查找姓名以s开头的员工
C.Restrictions.disjunction( )方法用于指定多个逻辑与
D.Restrictions.in( )方法只能用于数组
20.在Hibernate中,关于注解说法正确的是(ABD )。
A.@Id用于声明持久化类的唯一标识,对应于数据表中的主键
B.@Cloumn用于将属性映射到列
C.@Transient用于忽略该属性,需要持久化到数据库
D.@GeneratedValue用于定义主键值的生成策略
解释:Hibernate常见注解
@Id
@Column
@Table
@Entity
@GeneratedValue
@ManyToOne
@JoinColumn
/**
* 部门类
* @author Happy 2016年9月22日19:40:56
*
*/
@Entity 标识一个类是 持久化类
@Table(name="DeptY2160")
public class Dept {
@Id 持久化类的标识
Hibernate_Session
@GeneratedValue(strategy=GenerationType.SEQUENCE,generator="seq_gen")
定义自己的序列生成器
@SequenceGenerator(name="seq_gen",sequenceName="SEQ_Num",allocationSize=1,initialValue=1)
private Integer deptNo;
private String deptName;
@OneToMany(mappedBy="dept",cascade={CascadeType.ALL})
/* @Fetch(FetchMode.JOIN)
@LazyCollection(LazyCollectionOption.FALSE)*/
private Set<Emp> emps=new HashSet<Emp>();
public Set<Emp> getEmps() {
return emps;
}
public void setEmps(Set<Emp> emps) {
this.emps = emps;
}
public Dept(Integer deptNo, String deptName) {
this.deptNo = deptNo;
this.deptName = deptName;
}
public Dept() {
}
public Integer getDeptNo() {
return deptNo;
}
public void setDeptNo(Integer deptNo) {
this.deptNo = deptNo;
}
public String getDeptName() {
return deptName;
}
public void setDeptName(String deptName) {
this.deptName = deptName;
}
}

21.下列关于同义词的说法,选项正确的是(C )。
A.只能为表创建同义词,不能为视图创建同义词
B.同义词只能用于引用其他用户创建的表
C.公有同义词和私有同义词对同一个表可以同名
D.使用Drop Synonym语句删除同义词的同时,同义词引用的表也无效
解释:
主键生成策略
@GeneratedValue用于定义主键值的生成策略 ,相当于native
22.评估CREATE TABLE 语句:
CREATE TABLE products
(
product_id NUMBER(6) CONSTRAINT prod_id_pk PRIMARY KEY,
product_name VARCHAR2(15)
)
下列关于prod_id_pk选项正确的是(B )。
A.可以被创建,但需要唯一索引用手工创建
B.可以被创建并且会自动创建唯一索引
C.可以被创建并且会自动创建非唯一索引
D.可以被创建但不可以使用,因为没有指定索引
23.下列创建序列的SQL语句:
CREATE SEQUENCE seq1
START WITH 100
INCREMENT BY 10
MINVALUE 1
MAXVALUE 200
CYCLE
NOCACHE;
序列seq1的生成的值已经到最大值200,再执行下列语句:
SELECT seq1.nextval FROM dual;
下列显式正确值的选项是(A )。
A.1
B.10
C.100
D.报错
24.A_oe和A_hr是数据库中的2个用户,A_oe下有一个表Orders,执行下列语句如下:
CREATE ROLE r1; --System下
GRNAT SELECT,INSERT ON A_oe.orders to r1; --A_oe模式下
GRANT r1 to A_hr; --System模式下
GRANT SELECT ON A_oe.orders To A_hr; --A_oe模式下
REVOKE SELECT ON A_oe.orders FROM A_hr;
执行上面语句后结果正确的是(A )。
A.A_hr能够查询A_oe.orders表
B.A_hr不能够查询A_oe.orders表
C.REVOKE语句将撤销A_hr的SELECT权限同时也从r1角色撤销SELECT权限
D.REVOKE语句将报错,因为SELECT权限已经被r1角色授予
25.对于视图,下列语句正确的是(CD )。
A.有列别名的视图不能被修改
B.一个复杂的视图定义中使用子查询不能包含聚合(分组)函数和连接
C.如果一个视图定义中包含DISTINCT关键字,则不能够通过视图进行删除
D.创建视图语法中OR REPLACE 选项被使用,目的是在没有删除视图的情况下修改已存在的视图定义。
二、简答题(共5题,每题7.5分)
1.请简述Hibernate与jdbc的联系。
2.请简述MyBatis和Hibernate的区别。
3.请详细描述在Hibernate中Java对象的三种状态是如何转换的。
4.请简述Hibernate是如何实现分页的?如果不使用Hibernate提供的方法实现分页功能,则采用什么方式分页?
5.根据员工表编写规范的存储过程。完成以下任务:
1).给指定员工涨工资,其中员工编号和涨的工资金额由输入参数决定
2).涨工资后,显示所有员工薪水情况
3).在存储过程中考虑到以下异常:
A.指定的员工不存在的情况
B.涨的工资金额小于等于0的情况
4).编写调用程序,要求测试各种情况