终于有可以有时间写点数据结构的学习总结了,前段时间一直在紧张的忙一些项目,都没有空出时间来学习数据结构,现在终于可以稍微喘口气了,还是数据结构有意思,这两天看了点栈的东西,写下来总结一下,有错误的地方希望看到的朋友指出来,感激不尽。
根据学习,栈就是一种线性数据结构,栈的运算只能在表的一段进行,所以这种数据结构具有“后进先出”的特点。
接下来是栈的c语言实现。其中栈由一个top节点和bottom节点组成,这两个节点分别指向栈的顶部和底部。其中栈的组成结点是由结构体实现,结构体由数据库和指向下一个结点的指针域构成,下面是结点的c语言实现:
1 /* 2 定义实现栈的结点 3 */ 4 typedef struct Node{ 5 int data; 6 struct Node * pNext; 7 }NODE,* PNODE;
有了实现栈的结点,那么接下来就是该如何实现栈(具体的解释看代码):
1 /* 2 定义栈的结构,此处采用链表实现静态栈,所以仅仅需要给出栈的头部指针和底部指针即可 3 */ 4 typedef struct Strack{ 5 PNODE pTop; 6 PNODE pBottom; 7 }STRACK,* PSTRACK;
栈的基本操作:栈的初始化,压栈、栈的遍历、出栈等操作
1 /* 2 对栈初始化的函数 3 对栈初始化仅仅是令栈中的top和bottom指针指向一个确定的地址,并且此地址指向的是栈的头结点(头结点的引入可以 4 大大方便对栈的操作)。 5 */ 6 void init_strack(PSTRACK pS){ 7 pS->pTop=(PNODE)malloc(sizeof(NODE)); //定义一个新结点,这个结点就是栈的头结点,并且让pTop指向这个结点 8 if(pS->pTop==NULL){ 9 printf("内存分配失败"); 10 exit(-1); 11 } 12 else{ 13 pS->pBottom=pS->pTop; //令bottom和top都指向头结点,则初始化栈完成,栈中没有任何有效结点 14 pS->pTop->pNext=NULL; 15 } 16 17 } 18 19 /* 20 压栈函数 21 因为栈具有“先进后出、后进先出”的特性,所以,在将元素压入栈时,也只能将栈压入栈的顶部 22 由此,压栈函数就是令栈的top指针指向新结点,新结点的指针域指向未压入栈时的最顶部的元素。 23 */ 24 int push(PSTRACK pS,int val){ 25 PNODE pNew=(PNODE)malloc(sizeof(NODE)); //定义一个新结点 26 if(pNew->pNext==NULL){ 27 printf("内存分配失败"); 28 exit(-1); 29 } 30 pNew->data= val; 31 pNew->pNext=pS->pTop; //指针赋值的顺序不可以乱,为保证top所指向的地址不丢失,所以首先让新结点的指针域指向pS->pTop所指向的结点 32 pS->pTop=pNew; //令top指针指向新的结点 33 return 0; //0表示当前push成功 34 } 35 36 /* 37 栈的遍历函数 38 因为只是遍历输出,所以不能破坏栈原有的结构,所以我们只有定义一个新的结点p,让其指向栈顶元素, 39 然后遍历下移一个输出其指向的元素的值 ,循环条件就是p=ps->pBottom 40 */ 41 void traverse(PSTRACK ps){ 42 PNODE p=ps->pTop; //让新定义的结构体指针指向栈顶元素 43 while(p!=ps->pBottom){ 44 printf("%d ", p->data); 45 p=p->pNext; //让当前指针指向当前节点的下一个结点 46 } 47 printf(" "); 48 return; 49 } 50 51 52 /* 53 判断当前栈是否为空的函数 54 若为空,返回true 55 否则,返回false 56 */ 57 bool isEmpty(PSTRACK ps){ 58 if(ps->pTop==ps->pBottom){ 59 return true; 60 } 61 else{ 62 return false; 63 } 64 } 65 66 /* 67 弹栈函数:弹栈简单的说就是将第一个数值弹出,然后将ps->pTop指向原第一个结点的下一个结点(即弹栈后的第一个结点), 68 然后在将被弹出的元素在内存中释放掉。 69 */ 70 bool pop(PSTRACK ps,int *pVal){ 71 if(isEmpty(ps)){ //判断当前栈是否为空,若为空,则返回false 72 return false; 73 } 74 else{ 75 PNODE p=ps->pTop; //定义一个结点,这个结点在每次弹栈时都是指向栈顶,这样可以保证不会造成被弹出元素的丢失 76 ps->pTop=p->pNext; //让top结点指向栈顶元素 77 *pVal=p->data; 78 free(p); //将被弹出元素释放 79 p=NULL; 80 return true; 81 } 82 }
上述就实现了对栈的基本操作,当然具体的应用还要看具体的算法要求。
上述是在大学时学习的,下面的是工作两年后再次学习时的理解,可能会有不同的见解,都写出来吧。
1、栈的定义:一种可以实现“先进后出”的数据存储结构,数据的插入和删除只能在数据的一端进行。
内存分为静态内存和动态内存。
静态内存在栈中分配;动态内存在堆中分配。
栈:由操作系统自动分配释放,存放函数的参数值,局部变量的值等。
堆:一般由程序猿分配释放,若程序猿不释放,程序结束时由OS回收(类似于c语言中的malloc函数分配的空间)。
2、栈的分类:
(1)静态栈:以数组作为数据的存储。
(2)动态栈:以链表作为数据的存储方式。
3、栈的相关操作(该处采用链表的动态栈):
一点说明:
因为用链表实现栈,其实其本质就是一个链表,只不过对该链表的插入(push)和删除(pop)操作都在该链表的一端进行(该段被称为栈顶,且人为限制就只在该栈顶进行操作),所以该链表就会具有了“先进后出”的特性,则被称为栈结构。
所以,严格来说,栈仅仅需要一个栈顶,该栈顶指向该链表的被称为栈顶端的节点(所以,该栈顶也是一个该Node类型的指针)。
(1)栈中每个节点的结构:

(2)栈的结构:
因为通过栈顶可以找到该栈的所有元素,所以,该栈对应的链表应该是一个自上而下指向的链表。
该栈仅需要一个stop指针,指向栈顶元素。


(3)栈的初始化操作:

(4)栈的push操作:
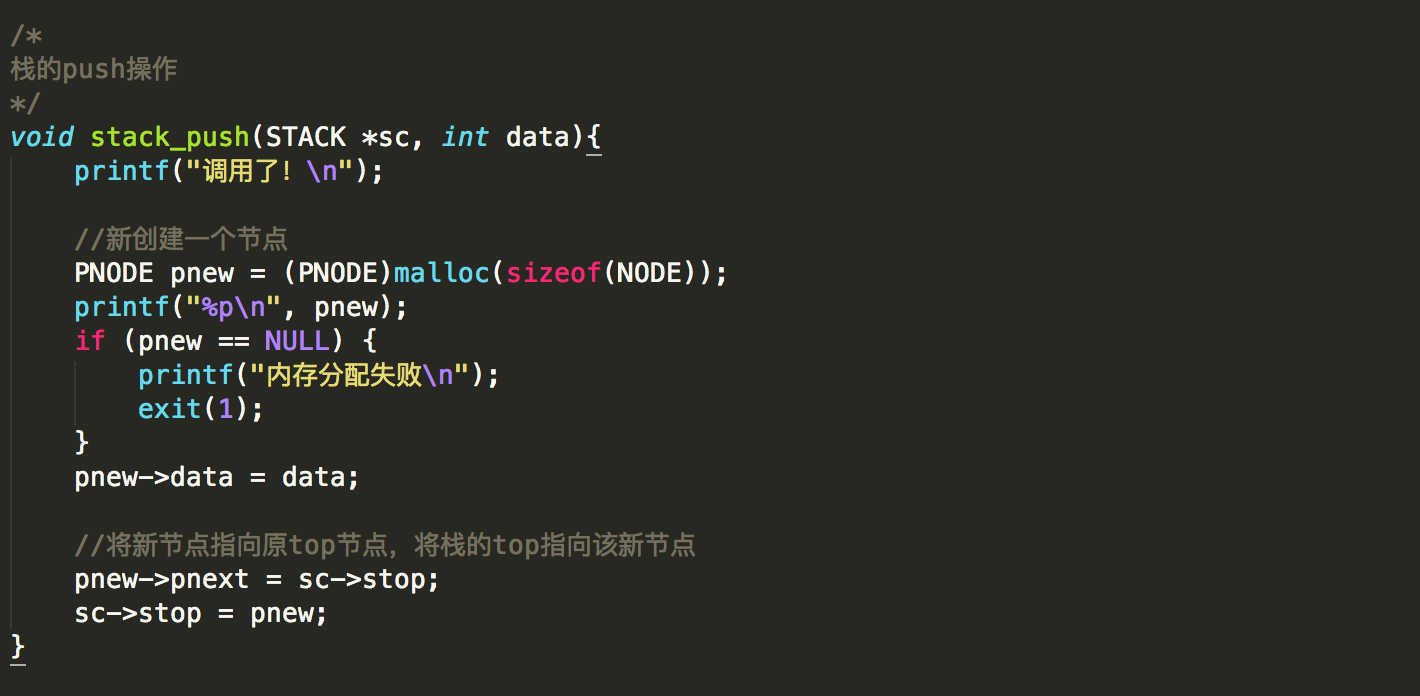
(5)栈的pop操作:
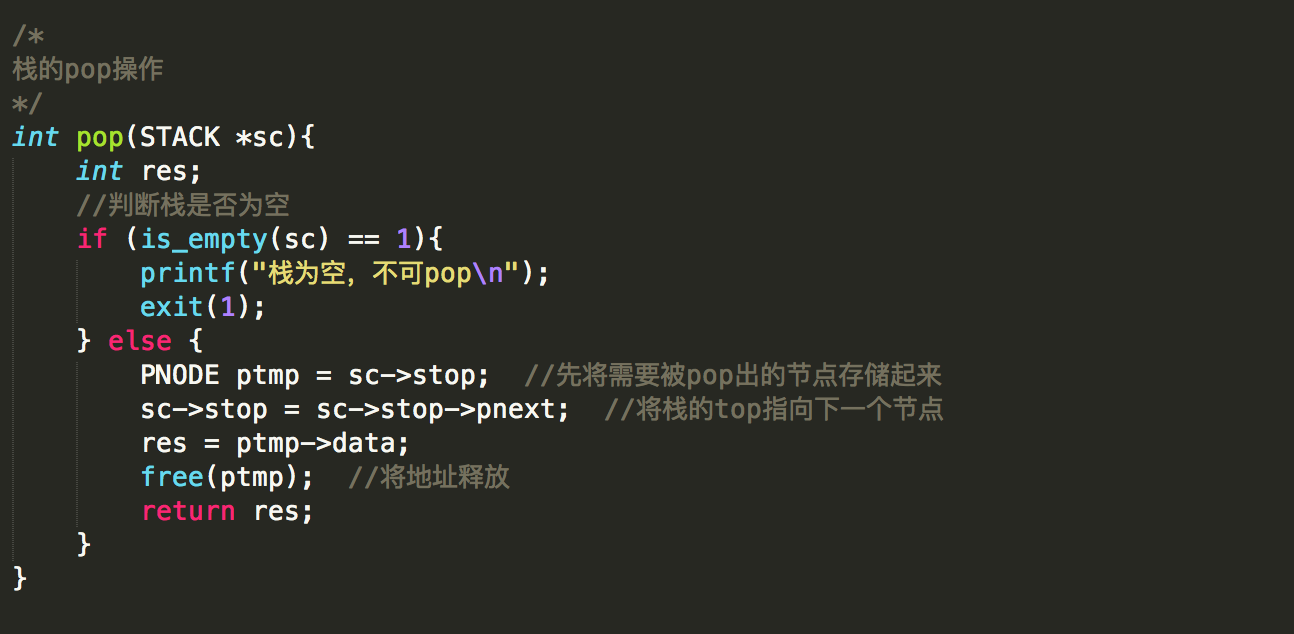
(6)栈是否为空及栈的遍历操作:
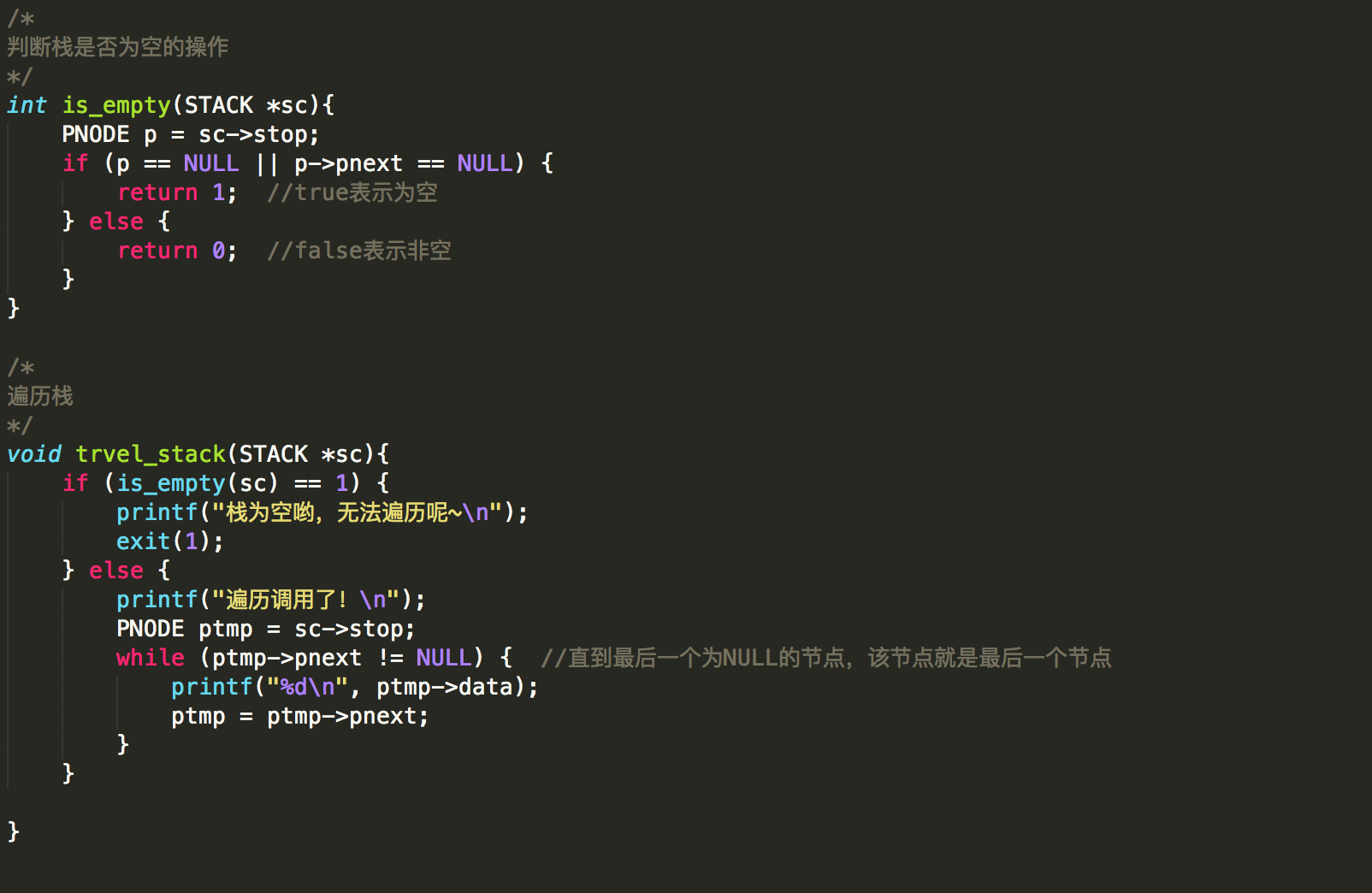
其实在栈中可以增加一个PNODE类型的指针sbuttom,让该指针用于指向栈低节点,在判断非空时,只要判断sc->stop == sc->sbuttom时,就表示top和buttom重合了,指向了最底部的节点。其实,该buttom节点可以通过最后一个节点的next指针域是否为NULL来判断(next指针域为NULL时,就表示该节点没有下一个节点了,是栈低节点)。
代码:
1 #include <stdio.h> 2 #include <sys/malloc.h> 3 #include <stdlib.h> 4 5 /* 6 栈结构及其操作: 7 当前采用链表进行栈中数据的存储。 8 */ 9 10 11 /* 12 定义栈中每一个节点的结构 13 */ 14 typedef struct Node{ 15 int data; //数据域 16 struct Node * pnext; //指针域,指向栈中下一个节点 17 }NODE, * PNODE; //定义两个别名,方便操作 18 19 /* 20 定义栈的结构: 21 因为用链表实现栈,其实其本质也是一个链表,只不过该链表的插入(push)和删除(pop)操作只能在链表的一端(该端被称作栈顶)进行操作,所以该链表具有“先进后出”的特性,被称作栈(个人理解)。 22 所以,严格来说,栈仅仅需要一个指向栈顶(链表的一端)struct Node *类型的指针就可以知道该栈中的所有数据。 23 */ 24 typedef struct Stack{ 25 struct Node * stop; //栈的栈顶(指向栈中最顶部的那个元素) 26 } STACK; 27 28 //栈的初始化操作 29 struct Stack init_stack(); 30 31 //push操作 32 void stack_push(STACK *sc, int data); 33 34 //pop操作 35 int pop(STACK *sc); 36 37 //遍历操作 38 void trvel_stack(STACK *sc); 39 40 //判断是否为空操作 41 int is_empty(STACK *sc); 42 43 int main(int argc, char const *argv[]) 44 { 45 STACK sc; 46 sc = init_stack(); 47 48 //push几个数据 49 stack_push(&sc, 1); 50 stack_push(&sc, 3); 51 stack_push(&sc, 7); 52 stack_push(&sc, 2); 53 stack_push(&sc, 10); 54 55 //遍历 56 trvel_stack(&sc); 57 58 //pop一个数据出来 59 pop(&sc); 60 61 trvel_stack(&sc); 62 63 return 0; 64 } 65 66 /* 67 栈的初始化操作 68 */ 69 struct Stack init_stack(){ 70 //先定义一个栈 71 STACK sc; 72 73 //初始化栈中的第一个节点(栈低节点),该节点并没有什么实际意义,不存放数据 74 PNODE pbottom = (PNODE)malloc(sizeof(NODE)); 75 if (pbottom == NULL) { 76 printf("内存分配失败 "); 77 exit(1); 78 } 79 pbottom->pnext = NULL; 80 81 //将栈顶指向该元素 82 sc.stop = pbottom; 83 84 return sc; 85 } 86 87 /* 88 栈的push操作 89 */ 90 void stack_push(STACK *sc, int data){ 91 printf("调用了! "); 92 93 //新创建一个节点 94 PNODE pnew = (PNODE)malloc(sizeof(NODE)); 95 printf("%p ", pnew); 96 if (pnew == NULL) { 97 printf("内存分配失败 "); 98 exit(1); 99 } 100 pnew->data = data; 101 102 //将新节点指向原top节点,将栈的top指向该新节点 103 pnew->pnext = sc->stop; 104 sc->stop = pnew; 105 } 106 107 /* 108 栈的pop操作 109 */ 110 int pop(STACK *sc){ 111 int res; 112 //判断栈是否为空 113 if (is_empty(sc) == 1){ 114 printf("栈为空,不可pop "); 115 exit(1); 116 } else { 117 PNODE ptmp = sc->stop; //先将需要被pop出的节点存储起来 118 sc->stop = sc->stop->pnext; //将栈的top指向下一个节点 119 res = ptmp->data; 120 free(ptmp); //将地址释放 121 return res; 122 } 123 } 124 125 /* 126 判断栈是否为空的操作 127 */ 128 int is_empty(STACK *sc){ 129 PNODE p = sc->stop; 130 if (p == NULL || p->pnext == NULL) { 131 return 1; //true表示为空 132 } else { 133 return 0; //false表示非空 134 } 135 } 136 137 /* 138 遍历栈 139 */ 140 void trvel_stack(STACK *sc){ 141 if (is_empty(sc) == 1) { 142 printf("栈为空哟,无法遍历呢~ "); 143 exit(1); 144 } else { 145 printf("遍历调用了! "); 146 PNODE ptmp = sc->stop; 147 while (ptmp->pnext != NULL) { //直到最后一个为NULL的节点,该节点就是最后一个节点 148 printf("%d ", ptmp->data); 149 ptmp = ptmp->pnext; 150 } 151 } 152 153 }