引言
前面分享的推文 自动化测试必会—数据驱动DDT 介绍过 unittest 框架中操作 JSON 和 YAML 文件实现数据驱动。那么在 pytest 中,又该如何实现呢?
Pytest 操作 JSON/YAML 文件实现数据驱动
首先按照使用 pytest 进行数据驱动的基本思路创建一个读取 JSON 文件和 YAML 文件的方法:
def test_read_data_from_json_yaml(data_file): return_value = [] data_file_path = os.path.abspath(data_file) print(data_file_path) _is_yaml_file = data_file_path.endswith((".yml", ".yaml")) with codecs.open(data_file_path, 'r', 'utf-8') as f: #从YAML或JSON文件中加载数据 if _is_yaml_file: data = yaml.safe_load(f) else: data = json.load(f) for i, elem in enumerate(data): if isinstance(data, dict): key, value = elem, data[elem] if isinstance(value, dict): case_data = [] for v in value.values(): case_data.append(v) return_value.append(tuple(case_data)) else: return_value.append((value,)) return return_value
test_read_data_from_json_yaml 这个函数方法,实现了自动读取 JSON 文件和 YAML 文件,并且把 JSON 文件和 YAML 文件中的数据提取出来,并按照 pytest.mark.parametrize 可接收的方式返回。
有了这个函数方法,JSON 或者 YAML 文件的数据通过此方法就可以转换成 pytest.mark.parametrize 认可的格式直接传入了。
下面实践一下,在 APITest 项目根目录下创建如下文件目录:
|--APITest |--tests_pytest_ddt |--test_baidu_ddt.py |--test_baidu_ddt.json |--test_baidu_ddt.yaml |--test_baidu_ddt.xlsx |--__init__.py |--conftest.py
其中,test_baidu_ddt.json 文件的内容如下:
{ "case1": { "search_string": "testing", "expect_string": "Testing" }, "case2": { "search_string": "hello_world.com", "expect_string": "Testing" } }
test_baidu_ddt.yaml 文件的内容如下:
"case1": "search_string": "testing" "expect_string": "Testing" "case2": "search_string": "hello_world.com" "expect_string": "Testing"
test_baidu_ddt.py 文件的代码如下:
import codecs import json import os import time import pytest import yaml def test_read_data_from_json_yaml(data_file): return_value = [] data_file_path = os.path.abspath(data_file) print(data_file_path) _is_yaml_file = data_file_path.endswith((".yml", ".yaml")) with codecs.open(data_file_path, 'r', 'utf-8') as f: #从YAML或JSON文件中加载数据 if _is_yaml_file: data = yaml.safe_load(f) else: data = json.load(f) for i, elem in enumerate(data): if isinstance(data, dict): key, value = elem, data[elem] if isinstance(value, dict): case_data = [] for v in value.values(): case_data.append(v) return_value.append(tuple(case_data)) else: return_value.append((value,)) return return_value @pytest.mark.baidu class TestBaidu: @pytest.mark.parametrize('search_string, expect_string', test_read_data_from_json_yaml('tests_pytest_ddt/test_baidu_ddt.yaml')) def test_baidu_search(self, login, search_string, expect_string): driver, s, base_url = login driver.get(base_url + "/") driver.find_element_by_id("kw").send_keys(search_string) driver.find_element_by_id("su").click() time.sleep(2) search_results = driver.find_element_by_xpath('//*[@id="1"]/h3/a').get_attribute('innerHTML') print(search_results) assert (expect_string in search_results) is True if __name__ == "__main__": pytest.main(['-s', '-v'])
此文件中的代码与 Pytest 测试框架——数据驱动 中讲解的代码几乎相同,唯一的改变在于增加了一个新方法 test_read_data_from_json_yaml,另外 @pytest.mark.parametrize 的参数,从直接提供参数变成了从文件提供参数。
(test_read_data_from_json_yaml('tests_pytest_ddt/test_baidu_ddt.yaml'))
在命令行中通过如下方式运行:
D:Python_TestAPITest>pytest tests_pytest_ddt -s -v
运行结束后查看结果如下: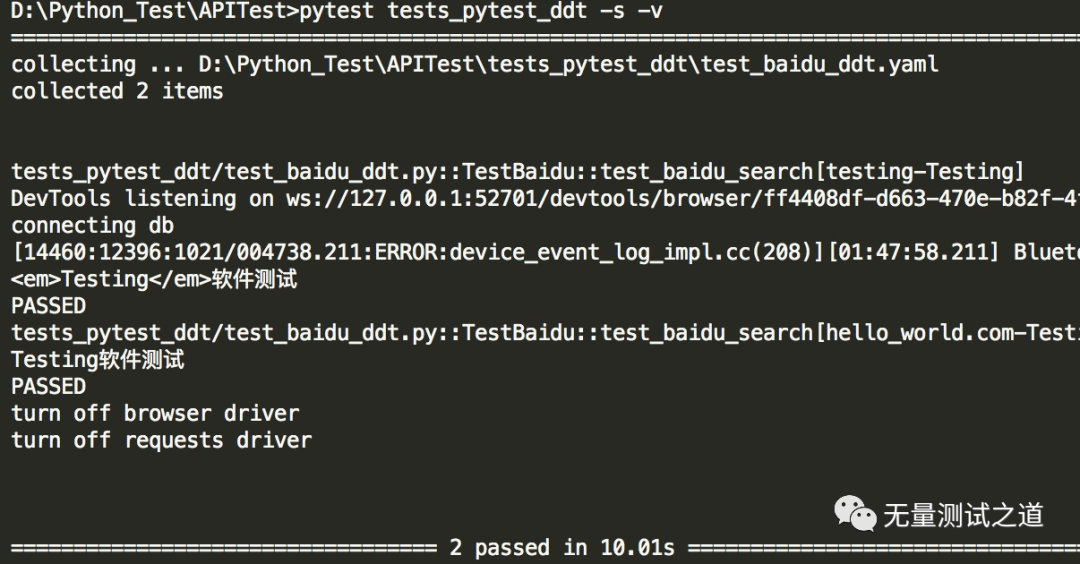 

可以看到,两个测试用例都执行了,并且 YAML 文件中的数据被正确读取。
那么如果我们现在要执行 JSON 文件中的数据该如何操作呢?把上述代码中传入的 yaml 文件后缀换成 json 文件后缀,再次执行即可。
Pytest 操作 Excel 文件实现数据驱动
在实际应用中,也有很多公司使用 Excel 来做数据驱动。在 python 中,读写 Excel 的 library 很多,常见的有 xlrd、xlwt,以及openpyxl。由于 xlrd 和 xlwt 只能分别用作读和写,实现同样的读写操作,它的代码行数较多,故逐渐变得不再流行。所以下面将重点介绍 openpyxl 的使用。
openpyxl 安装
pip install openpyxl
openpyxl 使用
from openpyxl import load_workbook, Workbook if __name__ == "__main__": # 创建一个workbook file_name = r'c: est.xlsx' wb = Workbook() # 创建一个sheet,名为Testing,把它插入到最前的位置 wb.create_sheet('Testing',0) # 创建一个sheet,名为TEST,把它插入index为1的位置 wb.create_sheet('TEST',1) # 保存表格 wb.save(file_name) # 读和写 # 初始化表格 wb2 = load_workbook(file_name) # 读,获取所有的sheet名称 print(wb2.sheetnames) # 获取sheet名为Testing的表格 s = wb2['Testing'] # 将A1行的值设置为Testing s['A1'] = 'Testing' # 将第2行,第一列的值设置为1 s.cell(row=2, column=1).value = 1 # 打印第2行第一列单元格的值 --方法1 print(s.cell(row=2,column=1).value) # 打印第2行第一列单元格的值 --方法2 print(s['A2'].value) # 保存表格 wb.save(file_name)
如上述代码块所示,简单介绍了 openpyxl 的用法,涉及创建表格、创建 sheet 名、读取单元格的值、设置单元格的值等部分。你可以看出使用 openpyxl 操作 excel 是相对比较简单的。
openpyxl 结合 pytest 实现数据驱动
文件 test_baidu_ddt.xlsx 的内容如下(sheet 名 Testing):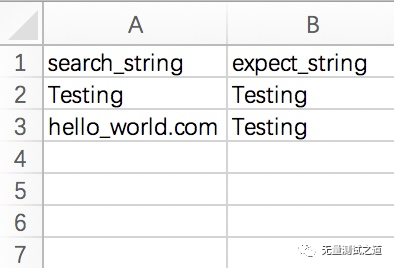
来写个读 Excel 的方法,代码如下:
def test_read_data_from_excel(excel_file, sheet_name): return_value = [] # 判断文件是否存在 if not os.path.exists(excel_file): raise ValueError("File not exists") # 打开指定的sheet wb = load_workbook(excel_file) # 按照pytest接受的格式输出数据 for s in wb.sheetnames: if s == sheet_name: sheet = wb[sheet_name] for row in sheet.rows: return_value.append([col.value for col in row]) # 第一行数据是标题,故skip掉 return return_value[1:]
更新 test_baidu_ddt.py 文件,把 test_read_data_from_excel 的方法加进去,更新后的代码如下:
import codecs import json import os import time import pytest import yaml from openpyxl import load_workbook def test_read_data_from_json_yaml(data_file): return_value = [] data_file_path = os.path.abspath(data_file) print(data_file_path) _is_yaml_file = data_file_path.endswith((".yml", ".yaml")) with codecs.open(data_file_path, 'r', 'utf-8') as f: # 从YAML或JSON文件中加载数据 if _is_yaml_file: data = yaml.safe_load(f) else: data = json.load(f) for i, elem in enumerate(data): if isinstance(data, dict): key, value = elem, data[elem] if isinstance(value, dict): case_data = [] for v in value.values(): case_data.append(v) return_value.append(tuple(case_data)) else: return_value.append((value,)) return return_value def test_read_data_from_excel(excel_file, sheet_name): return_value = [] if not os.path.exists(excel_file): raise ValueError("File not exists") wb = load_workbook(excel_file) for s in wb.sheetnames: if s == sheet_name: sheet = wb[sheet_name] for row in sheet.rows: return_value.append([col.value for col in row]) print(return_value) return return_value[1:] @pytest.mark.baidu class TestBaidu: # 注意,此处调用我换成了读Excel的方法 @pytest.mark.parametrize('search_string, expect_string', test_read_data_from_excel(r'DPython_TestAPITest ests_pytest_ddt est_baidu_ddt.xlsx', 'Testing')) def test_baidu_search(self, login, search_string, expect_string): driver, s, base_url = login driver.get(base_url + "/") driver.find_element_by_id("kw").send_keys(search_string) driver.find_element_by_id("su").click() time.sleep(2) search_results = driver.find_element_by_xpath('//*[@id="1"]/h3/a').get_attribute('innerHTML') print(search_results) assert (expect_string in search_results) is True if __name__ == "__main__": pytest.main(['-s', '-v','tests_pytest_ddt'])
在命令行中通过如下方式再次运行即可:
D:Python_TestAPITest>pytest tests_pytest_ddt -s -v
运行后查看结果,会发现测试被正确执行,测试数据是从 Excel 指定的 sheet 名中获取的。
Pandas 实现数据驱动
openpyxl 操作 Excel 非常简洁,但是相对于 Pandas 来说,还不够简洁,而且 openpyxl 运算效率不如 Pandas,特别是当表格行项目过多时,openpyxl 运算较慢。
Pandas 是一个强大的分析结构化数据的工具集,它的使用基础是 Numpy(提供高性能的矩阵运算);Pandas 用于数据挖掘和数据分析,同时也提供数据清洗功能。使用 Pandas 操作 Excel 数据,就会变得十分简单。
Pandas 安装
# pandas默认依赖xlrd库,故先安装xlrd pip install xlrd # 安装Pandas pip install Pandas
Pandas 语法
import Pandas as pd # 首先初始化,engine默认是xlrd s = pd.ExcelFile(path_or_buffer, engine=None) # 接着parse s.parse(sheet_name=0,header=0,names=None,index_col=None,usecols=None, squeeze=False,converters=None,true_values=None,false_values=None, skiprows=None,nrows=None,na_values=None,parse_dates=False, date_parser=None,thousands=None,comment=None,skipfooter=0, convert_float=True,mangle_dupe_cols=True,**kwds,)
Pandas 读取 Excel 文件非常简单,首先使用 Pandas 初始化 ExcelFile。其两个参数path_or_buffer 是我们要读取的文件路径。
Excel 文件名称建议使用英文路径及英文命名方式,不要使用中文。
import pandas as pd path_or_buffer = r'D:Python_TestAPITest ests_pytest_ddt est_baidu_ddt.xlsx'
engine 是供 Pandas 使用的 engine,可选项为“xlrd”、“openpyxl”、“odf”、“pyxlsb”,如果不提供,默认使用 xlrd。
parse 函数的参数
初始化后,可以使用 s.parse() 函数。parse 函数有非常多的参数,在此只列出常用的几个。
sheet_name: Excel 的 sheet 名
sheet_name 可以是整型数字、列表名,或者上述两者组合。
# 通过整型数字读取。读取第一个sheet。Pandas sheet名下标以0开始 s = pd.ExcelFile(path_or_buffer, sheet_name = 0) # 通过列表名读取 data = s.parse(sheet_name = 'Testing') # 通过index读取。读取第一个sheet data = s.parse(sheet_name = 0) #组合读取。读取第4个sheet,名为Testing的sheet以及第7个sheet data = s.parse(sheet_name = [3, 'Testing', 'Sheet6'])
header:使用哪一行作为列名
header 默认值为 0,即第一行,也可以设置为 [0, x]。
(例如 [0,1] 意味着将前两行作为多重索引)
data = s.parse(sheet_name = 'Testing', header = 0)
需要注意:Pandas 默认使用第一行为 header,所以在 Excel 里,第一行必须是 title,如果第一行是数据,将会导致第一行数据被遗漏。如果不想要 header,可以参数传递 header=None。
usecols:待读取的列
usecols 接收整型,从 0 开始,例如 [0, 1, 2],也可以使用列名例如 “A:D, F”,表示读取 A 到 D 列,以及 F 列。
data = s.parse(sheet_name = 'Testing', usecols='A:D')
skiprows:读取时,跳过特定行
skiprows=n,跳过前 n 行;skiprows = [a, b, c],跳过第 a+1、b+1、c+1 行(索引从0开始)
data = s.parse(sheet_name = 'iTesting', skiprows = [1,2,3])
nrows:需要读取的行数
仅仅列出要读取的行数
data = s.parse(sheet_name = 'Testing', nrows = 3)
Pandas 结合 Pytest 实现数据驱动
了解了 Pandas 语法后,来看下如何使用 Pandas 读取 Excel 数据:
def test_read_data_from_pandas(excel_file, sheet_name): if not os.path.exists(excel_file): raise ValueError("File not exists") # 初始化 s = pd.ExcelFile(excel_file) # 解析Excel Sheet df = s.parse(sheet_name) # 以list格式返回数据 return df.values.tolist()
可以看到,使用 pandas 读取 Excel 数据更加简洁方便。
最后,来更新下 test_baidu_ddt.py 文件,更新后的代码如下:
import codecs import json import os import time import pytest import yaml from openpyxl import load_workbook import pandas as pd # 读取Yaml文件和Json文件 def test_read_data_from_json_yaml(data_file): return_value = [] data_file_path = os.path.abspath(data_file) print(data_file_path) _is_yaml_file = data_file_path.endswith((".yml", ".yaml")) with codecs.open(data_file_path, 'r', 'utf-8') as f: #从YAML或JSON文件中加载数据 if _is_yaml_file: data = yaml.safe_load(f) else: data = json.load(f) for i, elem in enumerate(data): if isinstance(data, dict): key, value = elem, data[elem] if isinstance(value, dict): case_data = [] for v in value.values(): case_data.append(v) return_value.append(tuple(case_data)) else: return_value.append((value,)) return return_value # 读取Excel 文件 -- openpyxl def test_read_data_from_excel(excel_file, sheet_name): return_value = [] if not os.path.exists(excel_file): raise ValueError("File not exists") wb = load_workbook(excel_file) for s in wb.sheetnames: if s == sheet_name: sheet = wb[sheet_name] for row in sheet.rows: return_value.append([col.value for col in row]) print(return_value) return return_value[1:] # 读取Excel文件 -- Pandas def test_read_data_from_pandas(excel_file, sheet_name): if not os.path.exists(excel_file): raise ValueError("File not exists") s = pd.ExcelFile(excel_file) df = s.parse(sheet_name) return df.values.tolist() @pytest.mark.baidu class TestBaidu: @pytest.mark.parametrize('search_string, expect_string', test_read_data_from_pandas(r'D:Python_TestAPITest ests_pytest_ddt est_baidu_ddt.xlsx', 'Testing')) def test_baidu_search(self, login, search_string, expect_string): driver, s, base_url = login driver.get(base_url + "/") driver.find_element_by_id("kw").send_keys(search_string) driver.find_element_by_id("su").click() time.sleep(2) search_results = driver.find_element_by_xpath('//*[@id="1"]/h3/a').get_attribute('innerHTML') print(search_results) assert (expect_string in search_results) is True if __name__ == "__main__": pytest.main(['-s', '-v', 'tests_pytest_ddt'])
在命令行中通过如下方式再次运行即可:
D:Python_TestAPITest>pytest tests_pytest_ddt -s -v
运行后查看结果,可以发现测试被正确执行,测试数据是通过 Pandas 从 Excel 指定的 sheet 名中获取的。
事实上,Pandas 不仅仅能读取 Excel 文件,还可以读取 HTML 文件、TXT 文件、JSON 文件、数据库文件 (.sql) 等。在数据分析领域,Pandas 使用非常广泛,更多具体的 Pandas 使用,请自行查阅。
欢迎关注【无量测试之道】公众号,回复【领取资源】
Python编程学习资源干货、
Python+Appium框架APP的UI自动化、
Python+Selenium框架Web的UI自动化、
Python+Unittest框架API自动化、
资源和代码 免费送啦~
文章下方有公众号二维码,可直接微信扫一扫关注即可。
备注:我的个人公众号已正式开通,致力于测试技术的分享,包含:大数据测试、功能测试,测试开发,API接口自动化、测试运维、UI自动化测试等,微信搜索公众号:“无量测试之道”,或扫描下方二维码:
添加关注,让我们一起共同成长!