引言
你是否有过这种感受,在做自动化测试过程中,不论是API 自动化测试还是UI 自动化测试,我们写测试脚本有很大一部分时间都是在准备数据(setUp)、清理数据(tearDown)。因为数据是做自动化测试的至关重要的一个环节。如此看来数据驱动真的十分重要。接下来分享的内容是:Unittest测试框架中常用的数据驱动框架:DDT 。
数据驱动
1、数据驱动是什么?
数据驱动,指在自动化测试中处理测试数据的方式。
通常测试数据与功能函数分离,存储在功能函数的外部位置。在自动化测试运行时,数据驱动框架会读取数据源中的数据,把数据作为参数传递到功能函数中,并会根据数据的条数多次运行同一个功能函数。
数据驱动的数据源可以是函数外的数据集合、CSV 文件、Excel 表格、TXT 文件,以及数据库等。
2、数据驱动的优点?
(1)、减少重复代码
通过以下实例来看下数据驱动是如何减少重复代码的。
def test_001(user, pwd, num): # 实际函数逻辑 pass # 如果没有数据驱动,你的代码可能会是这样的: test_001('one', 'test_one', 1) test_001('two', 'test_two', 2) test_001('three', 'test_three', 3)
如果不使用数据驱动时,并且同一个功能函数存在多个测试数据,你只能多次调用这个功能函数;另外一旦某一个测试数据有更改/删除,你需要在函数调用里去更改相应的测试数据,非常不方便。
如果使用测试驱动时,你的代码可能会是这样的:
# origin_data指向一个文件,这个文件里存储有你所有的测试数据。 origin_data = './tests/data/testdata.csv' # dataDrivenDecorator是你实现数据驱动的装饰器 @dataDrivenDecorator(origin_data) def test_001(user, pwd, num): # 实际函数逻辑 pass
这种情况下, 你无须进行多次调用,而且当你的测试数据发生改变时, 你仅需要更改数据源文件的数据就可以了。
(2)、数据所属的测试用例失败,不会影响到其他测试数据对应的测试用例
通过以下实例来看下是怎么不会影响到其他测试数据对应的测试用例的。
如果不使用数据驱动之前,假设有以下一个函数:
test_data = [0, 1, 0, 1] def test_001(data): for x in data: assert x > 0 test_001(test_data)
执行结果,如下图所示: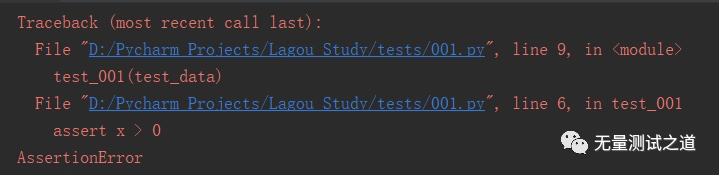
由执行结果可以看出,因为test_data 的第一个值是0, 它不大于0。所以断言失败,所有 test_data测试数据集中0后面的测试数据都没有执行。
如果有了数据驱动,则数据驱动会把这一个测试按照测试数据分解成多个测试,所以第一个测试数据失败也不会影响到后面的测试结果。
3、Python 中使用广泛的数据驱动框架有哪些?
-
DDT(Data-Driven Tests),通常结合Unittest 使用
-
parameterized,是Pytest 实现数据驱动的常用框架
DDT 包含哪些装饰器
1 个类装饰器
ddt 这个类装饰器必须装饰在TestCase 的子类上,TestCase 是Unittest 框架中的一个基类,它实现了Test Runner 驱动测试运行所需的接口(interface)。
2 个方法装饰器
分别是:data 和 file_data。
data 装饰器,直接提供测试数据;
file_data 装饰器则从 JSON 或 YAML 文件加载测试数据。
DDT 的使用步骤如下:
-
使用@ddt 装饰你的测试类;
-
使用@data 或者@file_data 装饰你需要数据驱动的测试方法;
-
如一组测试数据有多个参数,则需unpack,使用@unpack 装饰你的测试方法。
Python 安装DDT :
安装命令:pip install ddt或python -m pip install ddt
DDT 的使用
(1)、ddt 直接提供数据
from ddt import ddt, data, file_data, unpack from selenium import webdriver import unittest import time # ddt一定是装饰在TestCase的子类上 @ddt class Baidu(unittest.TestCase): def setUp(self): self.driver = webdriver.Chrome() self.driver.implicitly_wait(30) self.base_url = "http://www.baidu.com/" # data表示测试数据是直接提供的。 # unpack表示,对于每一组数据,如果它的值是list或者tuple,那么就分拆成独立的参数。 @data(['Testing', 'Testing'], ['hello_world.com','Testing']) @unpack def test_baidu_search(self, search_string, expect_string): driver = self.driver driver.get(self.base_url + "/") driver.find_element_by_id("kw").send_keys(search_string) driver.find_element_by_id("su").click() time.sleep(2) search_results = driver.find_element_by_xpath('//*[@id="1"]/h3/a').get_attribute('innerHTML') print(search_results) self.assertEqual(expect_string in search_results, True) def tearDown(self): self.driver.quit() if __name__ == "__main__": unittest.main(verbosity=2)
在这个例子中,我直接使用了@data 装饰器。在这个装饰器中,我给出了测试的2 组数据,分别是 ['Testing', 'Testing'] 和 ['hello_world.com', 'Testing'];然后我使用 @unpack 装饰器把每一组数据的数据unpack 成一个个的参数传给我的函数 test_baidu_search。
当你运行上面代码,从结果中会发现虽然我们只有一个测试用例test_baidu_search。但在生成的测试报告里,显示“Run 2 tests in XX”,也就是test_baidu_search 运行了 2 次,这就是DDT 在起作用。
这是多组参数,每组多个数据的情况,如果每组仅有一个数据呢?你仅需要更改如下:
# 如仅有一个参数,那么直接在data里写参数就好。 # 仅有一个参数的情况下,无须再用@unpack装饰测试方法。 @data('data1', 'data2')
(2)、ddt 使用函数提供数据
ddt 直接提供数据,除去上述的直接把数据写在@data() 的参数中外,还有一个情况,即数据先从函数获取,然后再写入@data() 的参数中。
from ddt import ddt, data, file_data, unpack from selenium import webdriver import unittest import time def get_test_data(): # 这里写你获取测试数据的业务逻辑。 # 获取到后,把数据返回即可。 # 注意,如果多组数据,需要返回类似([数据1-参数1, 数据1-参数2],[数据2-参数1, 数据2-参数2])这样的格式,方便ddt.data()解析 # 解析后返回的数据格式如下: results = (['Testing', 'Testing'], ['hello_world.com', 'Testing']) return results # ddt一定是装饰在TestCase的子类上 @ddt class Baidu(unittest.TestCase): def setUp(self): self.driver = webdriver.Chrome() self.driver.implicitly_wait(30) self.base_url = "http://www.baidu.com/" # data表示data是直接提供的。注意data里的参数我写了函数get_test_data()的返回值,并且以*为前缀,代表返回的是可变参数。 # unpack表示,对于每一组数据,如果它的值是list或者tuple,那么就分拆成独立的参数。 @data(*get_test_data()) @unpack def test_baidu_search(self, search_string, expect_string): driver = self.driver driver.get(self.base_url + "/") driver.find_element_by_id("kw").send_keys(search_string) driver.find_element_by_id("su").click() time.sleep(2) search_results = driver.find_element_by_xpath('//*[@id="1"]/h3/a').get_attribute('innerHTML') print(search_results) self.assertEqual(expect_string in search_results, True) def tearDown(self): self.driver.quit() if __name__ == "__main__": unittest.main(verbosity=2)
在上述示例中,我创建了一个函数get_test_data() 用于获取我的测试数据。这个函数可以带参数,也可以不带参数,具体需要根据你的业务逻辑来。
注意:get_test_data() 的返回值,一定需要遵守ddt.data() 可接受的数据格式。
即:一组数据,每个数据为单个的值;多组数据,每组数据为一个列表或者一个字典。
(3)、ddt 使用文件提供数据:JSON 和 YAML
除了使用 @ddt 直接提供数据,DDT 还支持通过文件加载数据。
不过默认只支持两种格式 YAML 和 JSON,只有以“.yml” 或者“.yaml” 结尾的会被认作 YAML 文件,其他格式都将被认为是 JSON 文件。
如果把上述用例改成使用 JSON 文件,则我们的用例看起来是这样的:
首先,我们创建一个跟 test_baidu.py 同名的文件 test_baidu.json,内容如下:
{ "case1": {
"search_string": "testing",
"expect_string": "Testing"
},
"case2": {
"search_string": "testing",
"expect_string": "Testing"
}
}
然后更新 test_baidu.py,更新后的代码如下所示:
from ddt import ddt, data, file_data, unpack from selenium import webdriver import unittest import time @ddt class Baidu(unittest.TestCase): def setUp(self): self.driver = webdriver.Chrome() self.driver.implicitly_wait(30) self.base_url = "http://www.baidu.com/" # 此处测试数据从文件读取,使用@file_data装饰器 # 文件路径是相对于Baidu这个测试类的相对路径 # 使用外部文件方式Load数据无须使用unpack @file_data('test_baidu.json') def test_baidu_search(self, search_string, expect_string): driver = self.driver driver.get(self.base_url + "/") driver.find_element_by_id("kw").send_keys(search_string) driver.find_element_by_id("su").click() time.sleep(2) search_results = driver.find_element_by_xpath('//*[@id="1"]/h3/a').get_attribute('innerHTML') print(search_results) self.assertEqual(expect_string in search_results, True) def tearDown(self): self.driver.quit() if __name__ == "__main__": unittest.main(verbosity=2)
可以看到,使用 @file_data 这个装饰器,与使用 @data 的装饰器有一点不同:
-
@file_data 这个装饰器里,文件的路径是相对于这个测试类本身来说的。在本例中为 Baidu 这个测试类所处的文件的相对位置;
-
使用 @file_data 无须使用 unpack,即使同一组数据的参数有多个。
如果把上述示例使用YAML 文件,则需要注意以下几点:
-
如果想在 python 中使用 yaml 文件,则需要安装 PyYAML。
-
安装命令:pip install pyyaml 或python -m pip install pyyaml
安装好后,我们在test_baidu.json 的同级目录下,创建一个文件test_baidu.yaml 文件,内容如下:
"case1":
"search_string": "testing"
"expect_string": "Testing"
"case2":
"search_string": "testing"
"expect_string": "Testing"
然后,我们更改 test_baidu.py,更改后的内容如下:
from ddt import ddt, data, file_data, unpack from selenium import webdriver import unittest import time # 使用yaml文件前先尝试导入,导入失败则将skip使用yaml数据驱动的测试用例 try: import yaml except ImportError: have_yaml_support = False else: have_yaml_support = True needs_yaml = unittest.skipUnless( have_yaml_support, "Need YAML to run this test" ) @ddt class Baidu(unittest.TestCase): def setUp(self): self.driver = webdriver.Chrome() self.driver.implicitly_wait(30) self.base_url = "http://www.baidu.com/" # 使用yaml文件必须使用@needs_yaml装饰 @needs_yaml @file_data('test_baidu.yaml') def test_baidu_search(self, search_string, expect_string): driver = self.driver driver.get(self.base_url + "/") driver.find_element_by_id("kw").send_keys(search_string) driver.find_element_by_id("su").click() time.sleep(2) search_results = driver.find_element_by_xpath('//*[@id="1"]/h3/a').get_attribute('innerHTML') print(search_results) self.assertEqual(expect_string in search_results, True) def tearDown(self): self.driver.quit() if __name__ == "__main__": unittest.main(verbosity=2)
你可以看到,与使用 JSON 文件不同, 使用 YAML 文件必须要先安装 PyYaml。然后为了防止 yaml 导入失败,我定义了 needs_yaml 这个装饰器,用来给我的程序加个安全判断。
如果导入失败,则所有以 needs_yaml 装饰的测试用例将不会执行。
(4)、ddt 使用文件提供数据:其他格式数据文件
因为 ddt 默认只支持 JSON 和 YAML 格式的数据。但是我想使用其他数据格式怎么办?
常用的方式有如下两种:
-
先读取其他格式的文件(例如 Excel 格式),然后创建 ddt 支持的 JSON 或者 YAML 文件,最后把获取到的数据写入这个文件,再使用 @file_data() 即可;
-
创建一个函数,在函数中读取其他格式的文件并获取数据,将数据直接返回为 @ddt.data() 支持的格式调用即可。
欢迎关注【无量测试之道】公众号,回复【领取资源】,
Python编程学习资源干货、
Python+Appium框架APP的UI自动化、
Python+Selenium框架Web的UI自动化、
Python+Unittest框架API自动化、
资源和代码 免费送啦~
文章下方有公众号二维码,可直接微信扫一扫关注即可。
备注:我的个人公众号已正式开通,致力于测试技术的分享,包含:大数据测试、功能测试,测试开发,API接口自动化、测试运维、UI自动化测试等,微信搜索公众号:“无量测试之道”,或扫描下方二维码:
添加关注,让我们一起共同成长!