|
1
2
3
4
5
6
7
8
9
10
11
|
。。。。。。。。。。。。。。 LoadModule proxy_module modules/mod_proxy.so LoadModule proxy_balancer_module modules/mod_proxy_balancer.so LoadModule proxy_http_module modules/mod_proxy_http.so 。。。。。。。。。。。。。。。。。。。。 <Proxy balancer://mycluster> BalancerMember "http://slave1:8008/App" loadfactor=4 BalancerMember "http://slave2:8008/App" loadfactor=3 BalancerMember "http://slave3:8008/App" loadfactor=3 .................... ///slave load ratio 4:3:3. |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
function db_connect($hosts, $user, $pass){ shuffle($hosts); //shuffle()是PHP函数,作用是将数组中每个元素的顺序随机打乱。 foreach($hosts as $host){ debug("Trying to connect to $host..."); $dbh = @mysql_connect($host, $user, $pass, 1); if ($dbh){ debug("Connected to $host!"); return $dbh; } debug("Failed to connect to $host!"); } debug("Failed to connect to all hosts in list - giving up!"); return 0; } |
“Master”-"Slave"模式的缺点是它并没有对于“写'操作提供扩展能力,而且存在单点故障,即一旦Master故障,整个网站将丧失“更新” 的能力。解决的办法采用“Master"-"Master"模式,即两台服务器互为”Master“-"Slave",这样不仅”读/写“能力扩展了一 倍,而且有效避免了”单点故障“,结合已有的“Master"-"Slave",整个数据库的架构就变成了下面的”双树“结构,
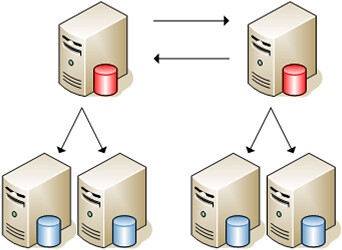 。
。“双树”架构并没有支撑太久的时间,大概6个月后,随着用户的激增,系统再一次达到了极限,不仅”写”操作成为了瓶颈,而且“异步复制"也由于 ”Slave“服务器过于繁忙而出现了严重的滞后而造成读数据的不一致。那么,能不能在现有架构加以解决,比如说增加新的”Master“服务器和考虑采 用”同步复制“呢?答案是否定的,在Master超过两台的设置中,只能采用”闭环链“的方式进行复制,在大数据量的生产环境中,很容易造成在任意时刻没 有一个Master或Slave节点是具有全部最新数据的(有点类似于”人一次也不能踏进同一条河“?),这样很难保障数据的一致性,而且一旦其中一个Master出现故障,将中断整个复制链;而对于”同步复制“,当然这是消除”复制滞后“的最好办法,不过在当时MySQL的同步复制还远没有成熟到可以运用在投产环境中。
Flickr网站的架构,需要一次大的变化来解决长期持续扩展的问题。
Shard - 大型网站数据库扩展的终极武器?
2005年7月,另一位大牛(MySQL 2005、2006年度 "Application of the Year Award"获得者)Dathan Pattishall加入了Flickr团队。一个星期之内,Dathan解决了Flickr数据库40%的问题,更重要的是,他为Flickr引进了 Shard架构,从而使Flickr网站具备了真正“线性”Scale-Out的增长能力,并一直沿用至今,取得了巨大的成功。
Shard主要是为了解决传统数据库Master/Slave模式下单一Master数据库的“写”瓶颈而出现的,简单的说Shard就是将一个大表分 割成多个小表,每个小表存储在不同机器的数据库上,从而将负载分散到多个机器并行处理而极大的提高整个系统的“写”扩展能力。相比传统方式,由于每个数据 库都相对较小,不仅读写操作更快,甚至可以将整个小数据库缓存到内存中,而且每个小数据库的备份,恢复也变得相对容易,同时由于分散了风险,单个小数据库 的故障不会影响其他的数据库,使整个系统的可靠性也得到了显著的提高。
对于大多数网站来说,以用户为单位进行Shard分割是最合适不过的,常见的分割方法有按地域(比如邮编),按Key值(比如Hash用户ID),这些 方法可以简单的通过应用配置文件或算法来实现,一般不需要另外的数据库,缺点是一旦业务增加,需要再次分割Shard时要修改现有的应用算法和重新计算所 有的Shard KEY值;而最为灵活的做法是以“目录”服务为基础的分割,即在Shard之前加一个中央数据库(Global Lookup Cluster),应用要先根据用户主键值查询中央数据库,获得用户数据所在的Shard,随后的操作再转向Shard所在数据库,例如下图:
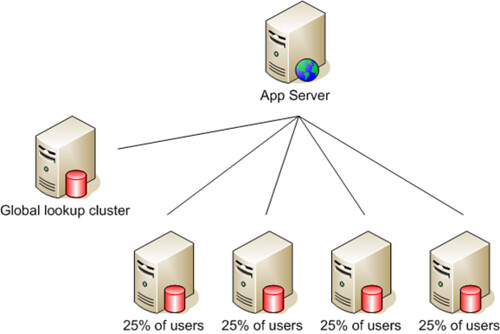
而应用的主要修改在于要添加一个Lookup访问层,例如将以下的代码:
|
1
2
3
|
string connectionString = @"Driver={MySQL};SERVER=dbserver;DATABASE=CustomerDB;"; OdbcConnection conn = new OdbcConnection(connectionString); conn.Open(); |
|
1
2
3
|
string connectionString = GetDatabaseFor(customerId); OdbcConnection conn = new OdbcConnection(connectionString); conn.Open(); |
对应我们前面所提到过的Flickr架构
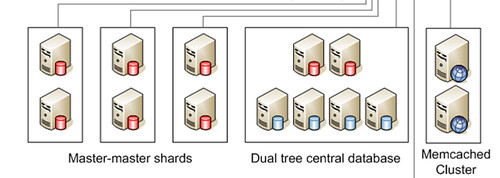
Dual Tree Central Database就是中央数据库,存放用户表,记录的信息是用户主键以及此用户对以的数据库Shard区;而Master-Master Shards就是一个个的Shard用户数据库,存储实际的用户数据和照片的元数据(Meta Data)。
Flickr Shard的设计我们在Flickr 网站架构研究(1)中已经总结过了,在此不再赘述。我们在此谈一下Shard架构的主要问题和Flickr的解决办法:1)Shard只适用于不需要 join操作的表,因为跨Shard join操作的开销太大,解决的办法是将一个用户的所有数据全部存放在同一个Shard里,对于一些传统方式下需要 跨Shard查询的数据,只能采取冗余的方法,比如Shard1的用户A对Shard2的用户B的照片进行了评论,那么这条评论将同时存放在Shard1 和Shard2中。这样就存在一个数据一致性的问题,常规的做法是用数据库事务(Transaction)、”两阶段提交“(2 phase commit)来解决,但做过两阶段提交(2PC)应用的都知道,2PC的效率相对较差,而且实际上也不能100%保证数据的完整性和一致性;另外,一旦 由于其中一个Shard故障而提交失败回滚,用户只能放弃或再试一遍,用户体验较差。Flickr对于数据一致性的解决方案是Queue(Flickr用 PHP开发了一个强大的Queue系统,将所有可以异步的任务都用Queue来实现,每天处理高达1千万以上的任务。),事实上当用户A对用户B的照片进 行评论时,他并不关心这条评论什么时候出现在用户B的界面上,即将这条评论添加到用户B的交易是可以异步的,允许一定的迟延,通过Queue处理,既保证 了数据的一致性,又缩短了用户端的相应时间,提高了系统性能。2)Shard的另一个主要问题Rebalancing,既当现有Shard的负载达到一定 的阀值,如何将现有数据再次分割,Flickr目前的方式依然是手工的,既人工来确定哪些用户需要迁移,然后运行一个后台程序进行数据迁移,迁移的过程用 户账户将被锁住。(据说Google做到了完全自动的Rebalancing,本着”萨大“坑里不再挖坑的原则,如果有机会的话,留到下一个系列再研究 吧)
Memcached的应用和争论
大家应该已经注意到,Flickr为中央数据库配置了Memcached作为数据库缓存,接下来的问题是,为什么用Memcached?为什么 Shard不需要Memcached?Memcached和Master,Slave的关系怎样?笔者将试图回答这些问题供大家参考,网上的相关争论很 多,有些问题尚未有定论。
Memecached是一个高性能的,分布式的,开源的内存对象缓存系统,顾名思义,它的主要目的是将经常读取的对象放入内存以提高整个系统,尤其是数 据库的扩展能力。Memcached的主要结构是两个Hash Table,Server端的HashTable以key-value pair的方式存放对象值,而Client端的HashTable的则决定某一对象存放在哪一个Memcached Server.举个例子说,后台有3个Memecached Server,A、B、C,Client1需要将一个对象名为”userid123456“,值为“鲁丁"的存入,经过Client1的Hash计 算,"userid123456"的值应该放入Memcached ServerB, 而这之后,Client2需要读取"userid123456"的值,经过同样的Hash计算,得出"userid123456"的值如果存在的话应该在 Memcached ServerB,并从中取出。最妙的是Server之间彼此是完全独立的,完全不知道对方的存在,没有一个类似与Master或Admin Server的存在,增加和减少Server只需在Client端"注册"并重新Hash就可以了。
Memcached作为数据库缓存的作用主要在于减轻甚至消除高负载数据库情况下频繁读取所带来的Disk I/O瓶颈,相对于数据库自身的缓存来说,具有以下优点:1)Memecached的缓存是分布式的,而数据库的缓存只限于本机;2)Memcached 缓存的是对象,可以是经过复杂运算和查询的最终结果,并且不限于数据,可以是任何小于1MB的对象,比如html文件等;而数据库缓存是以"row"为单 位的,一旦"row"中的任何数据更新,整个“row"将进行可能是对应用来说不必要的更新;3)Memcached的存取是轻量的,而数据库的则相对较 重,在低负载的情况下,一对一的比较,Memcached的性能未必能超过数据库,而在高负载的情况下则优势明显。
Memcached并不适用于更新频繁的数据,因为频繁更新的数据导致大量的Memcached更新和较低的缓冲命中率,这可能也是为什么Shard没 有集成它的原因;Memcached更多的是扩展了数据库的”读“操作,这一点上它和Slave的作用有重叠,以至于有人争论说应该 让"Relication"回到它最初的目的”Online Backup"数据库上,而通过Memcached来提供数据库的“读”扩展。(当然也有人说,考虑到Memcached的对应用带来的复杂性,还是慎 用。)
然而,在体系架构中增加Memecached并不是没有代价的,现有的应用要做适当的修改来同步Memcached和数据库中的数据,同时Memcached不提供任何冗余和“failover”功能,这些复杂的控制都需要应用来实现。基本的应用逻辑如下:
对于读操作:
|
1
2
3
4
5
|
$data = memcached_fetch( $id ); return $data if $data$data = db_fetch( $id ); memcached_store( $id, $data ); return $data; |
|
1
2
|
db_store( $id, $data ); memcached_store( $id, $data ); |
复制滞后和同步问题的解决
我们知道复制滞后的主要原因是数据库负载过大而造成异步复制的延迟,Shard架构有效的分散了系统负载,从而大大减轻了这一现象,但是并不能从根本上消除,解决这一问题还是要靠良好的应用设计。
当用户访问并更新Shard数据时,Flickr采用了将用户“粘”到某一机器的做法,
$id = intval(substr($user_id, -10));
$id % $count_of_hosts_in_shard
即同一用户每次登录的所有操作其实都是在Shard中的一个Master上运行的,这样即使复制到Slave,也就是另一台Master的时候有延时,也不会对用户有影响,除非是用户刚刚更新,尚未复制而这台Master就出现故障了,不过这种几率应该很小吧。
对于Central Database的复制滞后和同步问题,Flickr采用了一种复杂的“Write Through Cache"的机制来处理:
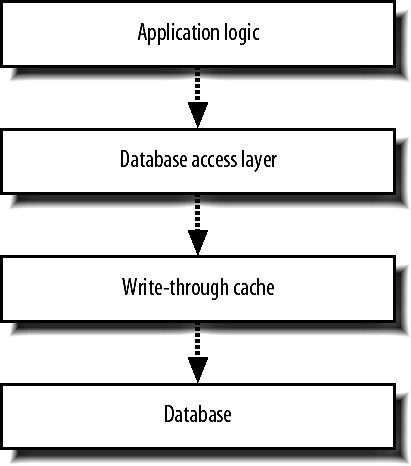
"Write Through Cache"就是将所有的数据库”写“操作都先写入”Cache",然后由Cache统一去更新数据库的各个Node,“Write Through Cache"维护每一个Node的更新状态,当有读请求时,即将请求转向状态为”已同步“的Node,这样即避免了复制滞后和Memcached的同步问 题,但缺点是其实现极为复杂,“Write Throug Cache"层的代码需要考虑和实现所有”journal","Transaction“,“failover”,和“recovery"这些数据库已经 实现的功能,另外还要考虑自身的"failover"问题。我没有找到有关具体实现的说明,只能猜测这一部分的处理可能也是直接利用或是实现了类似于 Flickr的Queue系统吧。