1、安装Elastic Search
ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎
1.1、下载Elastic Search
使用的es版本为1.3.2
wget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.3.2.zip
解压
unzip elasticsearch-1.3.2.zip
1.2、配置Elastic Search
es的配置文件在/config/elasticsearch.yml (ps:以下的目录路径都是/elasticsearch-1.3.2/下)
配置如下:
cluster.name: elasticsearch // 配置es的集群名称,默认是elasticsearch,es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群
node.name: "Squirrel" //es节点名称,做标识用,可随意定义
http.enabled: true //是否使用http协议对外提供服务,默认为true,开启
http.port: 9200 //设置对外服务的http端口,默认为9200
1.3、启动Elastic Search
直接启动
bin/elasticsearch
后台启动
nohup /bin/elasticsearch > /logs/elasticsearch.log 2>&1 &
访问http://localhost:9200/如下图:

安装成功!
分布式集群部署就是在不同机子上重复以上操作即可
1.4、安装Elastic Search插件
elasticsearch-head插件
安装命令:bin/plugin --install mobz/elasticsearch-head
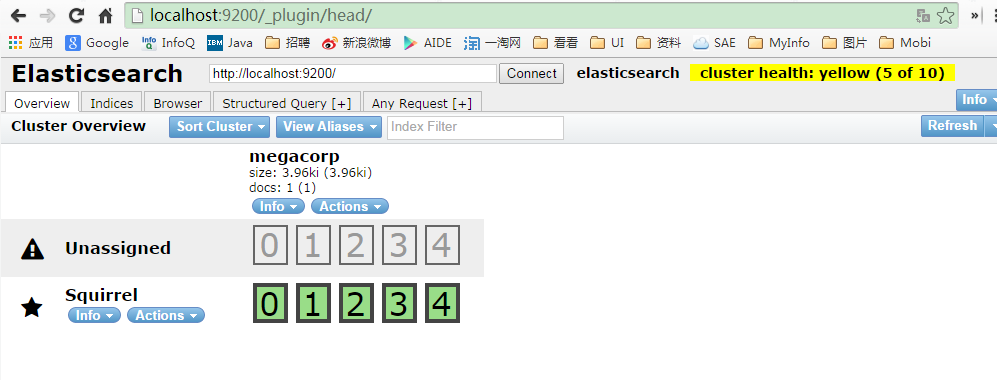
安装完成后,访问http://localhost:9200/_plugin/head/即可使用head插件,如下图
bigdesk插件
安装命令:bin/plugin --install lukas-vlcek/bigdesk
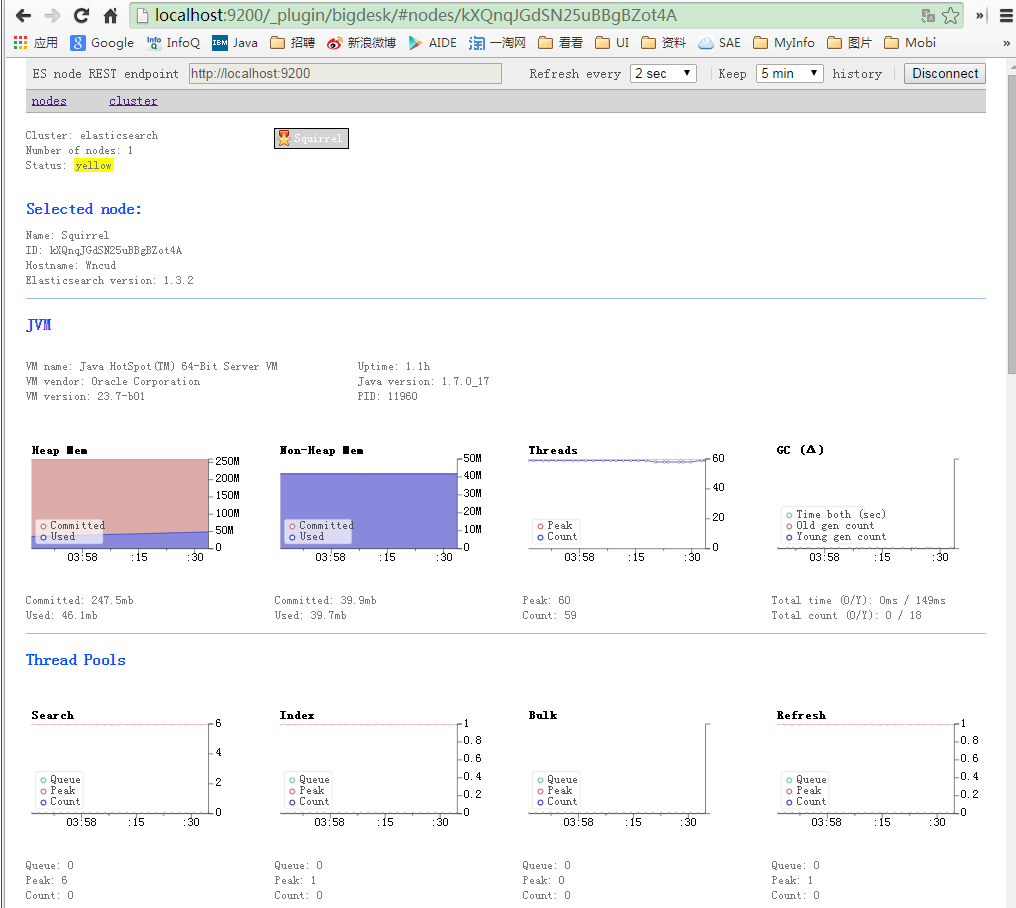
安装完成后,访问http://localhost:9200/_plugin/bigdesk/即可使用bigdesk插件,如下图
ElasticSearch Paramedic插件
安装命令:bin/plugin -install karmi/elasticsearch-paramedic
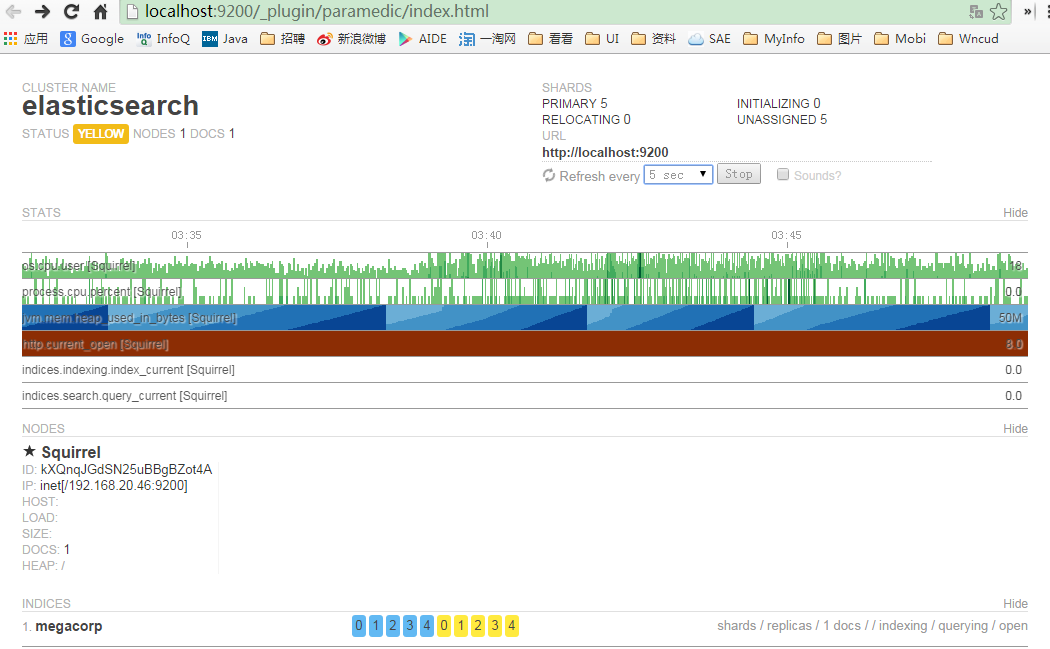
安装完成后,访问http://localhost:9200/_plugin/paramedic/即可使用Paramedic插件,如下图

1.5、Elastic Search配置
如果你的elasticsearch运行在专用服务器上,经验值是分配一半内存给elasticsearch。另一半用于系统缓存,这东西也很重要的。
你可以通过修改ES_HEAP_SIZE环境变量来改变这个设定。在启动elasticsearch之前把这个变量改到你的预期值。另一个选择设置elasticsearch的ES_JAVA_OPTS变量,这个变量时在启动脚本(elasticsearch.in.sh或elasticsearch.bat)里传递的。你必须找到-Xms和-Xmx参数,他们是分配给进程的最小和最大内存。建议设置成相同大小。ES_HEAP_SIZE其实就是干的这个作用。
设置该值的文件路径为:bin/elasticsearch.in.sh
#修改ES占用的内存大小,可根据服务器情况而定。
#例如服务器有24G内存,因此将一半给ES使用
if [ "x$ES_MIN_MEM" = "x" ]; then
ES_MIN_MEM=10g
fi
if [ "x$ES_MAX_MEM" = "x" ]; then
ES_MAX_MEM=10g
fi
#关于线程大小,主要是考虑到ES虽然会开很多线程,但承载的数据量较大,同时Xss并不是直接分配掉设定的内存,所以进行如下设置。
JAVA_OPTS="$JAVA_OPTS -Xss128m"
当jvm开始swapping时es的效率会降低,所以要保证它不swap,在/config/elasticsearch.yml配置文件中配置强制所有内存锁定,不要因为swap的来影响性能,设置为bootstrap.mlockall为true来锁住内存。通过上面配置ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过`ulimit -l unlimited`命令。
bootstrap.mlockall: true
/config/elasticsearch.yml 配置文件的其他配置说明如下:
# 由于ES基于广播方式发现集群内的服务器,所以配置起来相对简单 # 集群名称可以自动生成,当然也可以手动配置。如果你想要在同一网络中运行多个集群,就需要独一无二的集群名来区分他们 cluster.name: elasticsearch # 节点名称同理,可自动生成也可手动配置。 node.name: "Squirrel" # 配置该节点为主节点(默认开启) # node.master: true # 允许该节点存储数据(默认开启) # node.data: true # 一些高级的集群配置 # 1. 如果你想让节点从不选举为主节点,只用来存储数据,可作为负载器 # node.master: false # node.data: true # # 2. 如果想让节点成为主节点,且不存储任何数据,并保有空闲资源,可作为协调 # node.master: true # node.data: false # # 3. 如果想让节点既不称为主节点,又不成为数据节点,那么可将他作为搜索器,从节点中获取数据,生成搜索结果等。 # node.master: false # node.data: false # # 设置索引的分片数,默认为5 # index.number_of_shards: 5 # 设置索引的副本数,默认为1 # 配置文件中提到的最佳实践是,如果服务器够多,可以将分片书提高,将数据分布到大集群中去 # 同时,如果增加副本数量可以有效的提高搜索性能 # 由于我现在集群较小,所以仍使用默认配置 # 配置文件存储位置 path.conf: /usr/local/elasticsearch-1.3.2/config # 数据存储位置 path.data: /syslog/ESdata # 临时文件的路径 # path.work: /path/to/work # 日志文件的路径 # path.logs: /path/to/logs # 插件安装路径 # path.plugins: /path/to/plugins # 当JVM开始写入交换空间时(swapping)ElasticSearch性能会低下,你应该保证它不会写入交换空间 # 设置这个属性为true来锁定内存 bootstrap.mlockall: true # 下面的配置控制怎样以及何时启动一整个集群重启的初始化恢复过程 # (当使用shard gateway时,是为了尽可能的重用local data(本地数据)) # 一个集群中的N个节点启动后,才允许进行恢复处理 # gateway.recover_after_nodes: 1 # 设置初始化恢复过程的超时时间,超时时间从上一个配置中配置的N个节点启动后算起 # gateway.recover_after_time: 5m # 设置这个集群中期望有多少个节点。一旦这N个节点启动(并且recover_after_nodes也符合), # 立即开始恢复过程(不等待recover_after_time超时) # gateway.expected_nodes: 2 # 下面这些配置允许在初始化恢复,副本分配,再平衡,或者添加和删除节点时控制节点间的分片分配 # 设置一个节点的并行恢复数 # 1. 初始化恢复期间 cluster.routing.allocation.node_initial_primaries_recoveries: 4 # # 2. 添加/删除节点,再平衡等期间 cluster.routing.allocation.node_concurrent_recoveries: 4 # 设置恢复时的吞吐量(例如,100mb,默认为无限制。如果同上联还有其他业务在跑的话还是限制一下的好) # indices.recovery.max_size_per_sec: 400mb # Set to limit the number of open concurrent streams when # recovering a shard from a peer: # 设置当一个分片从对等点恢复时能够打开的并发流的上限 indices.recovery.concurrent_streams: 5 # 多播的就不翻了,就两条,自己看配置文件 # 当多播不可用或者集群跨网段的时候集群通信还是用单播吧 # 探查的超时时间,默认3秒,提高一点以应对网络不好的时候 discovery.zen.ping.timeout: 20s # 1. 禁用多播探查(默认可用) # discovery.zen.ping.multicast.enabled: false # # 2. 这是一个集群中的主节点的初始列表,当节点(主节点或者数据节点)启动时使用这个列表进行探测 # discovery.zen.ping.unicast.hosts: ["host1", "host2:port", "host3[portX-portY]"] discovery.zen.ping.unicast.hosts: ["192.168.69.9", "192.168.69.10"] # out of memory错误 避免过于频繁的查询时集群假死 # 1.设置es的缓存类型为Soft Reference,它的主要特点是据有较强的引用功能。只有当内存不够的时候,才进行回收这类内存,因此在内存足够的时候,它们通常不被回收。另外,这些引 用对象还能保证在Java抛出OutOfMemory 异常之前,被设置为null。它可以用于实现一些常用图片的缓存,实现Cache的功能,保证最大限度的使用内存而不引起OutOfMemory。在es的配置文件加上index.cache.field.type: soft即可。 # 2.设置es最大缓存数据条数和缓存失效时间,通过设置index.cache.field.max_size: 50000来把缓存field的最大值设置为50000,设置index.cache.field.expire: 10m把过期时间设置成10分钟。 index.cache.field.max_size: 50000 index.cache.field.expire: 10m index.cache.field.type: soft
2、安装Kibana
Kibana 是一个为 Logstash 和 ElasticSearch 提供的日志分析的 Web 接口。可使用它对日志进行高效的搜索、可视化、分析等各种操作。

2.1、下载Kibana
使用的版本为3.1.0
wget https://download.elasticsearch.org/kibana/kibana/kibana-3.1.0.zip
解压
unzip kibana-3.1.0.zip
2.2、配置Kibana
kibana的配置文件为kibana-3.1.0/config.js
修改如下值:
elasticsearch: "http://"+window.location.hostname+":9200" 修改为elasticsearch: "http://localhost:9200" 或elasticsearch: "http://192.168.69.xxx:9200"此属性值为kibana与es集成时,关联es的IP和端口
kibana是一个web服务,完全由js实现,所以配置完成之后,部署到任何一种web服务器上就可以使用了,以下是部署到Tomcat中的操作
将kibana拷贝到tomcat中
cp -r kibana-3.1.0/* tomcat/webapps/ROOT/
启动tomcat
tomcat/bin/catalina.sh start
访问http:localhost:8080/即可访问kibana界面了,如下图:
此时的es中没有数据,所以kibana也没有数据进行展示,接下来就可以安装Logstash,采集数据到es中,再通过kibana进行实时查询了

3、安装Logstash
Logstash 是一个应用程序日志、事件的传输、处理、管理和搜索的平台。你可以用它来统一对应用程序日志进行收集管理
3.1、下载Logstash
使用的Logstash版本为1.4.2
wget https://download.elasticsearch.org/logstash/logstash/logstash-1.4.2.tar.gz
解压Logstash
tar -zvxf logstash-1.4.2.tar.gz
3.2、启动Logstash
Logstash 可以抓取多种数据,以下是Logstash官网的展示(地址:http://www.logstash.net/docs/1.4.2/)


进入logstash-1.4.2目录执行命令启动Logstash
bin/logstash -e 'input {
stdin{}
}output {
elasticsearch { host => localhost }
}'以上命令为将命令行输入的数据写入elasticsearch去
输入命令后在当前命令行中输入“hello world!!”后,通过kibana页面就可以查看到刚才写入es中的数据了,如下图:
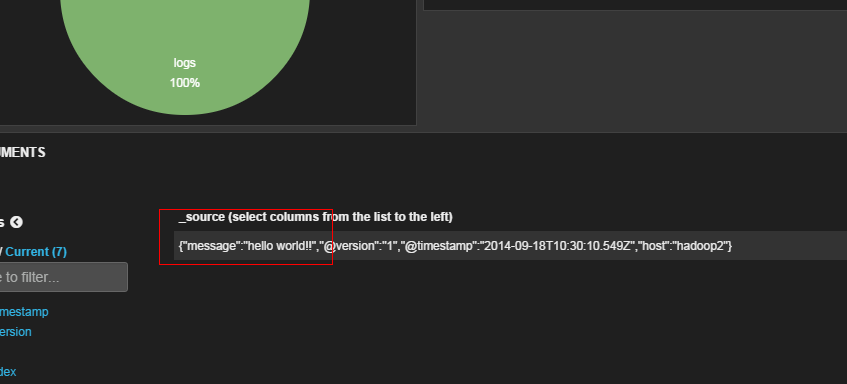

通过logstash收集日志文件数据到es中
bin/logstash -e 'input {
file {
path => "xxxx/tomcat/logs/data.log"
type => "log"start_position => "end"
}
}
output {
elasticsearch { host => localhost }
}'
以上是用logstash的File插件收集日志文件数据
分析网站访问日志应该是一个运维工程师最常见的工作了。而用 logstash 就可以来处理日志文件。
Logstash 使用一个名叫 FileWatch 的 Ruby Gem 库来监听文件变化。这个库支持 glob 展开文件路径,而且会记录一个叫 .sincedb 的数据库文件来跟踪被监听的日志文件的当前读取位置。所以,不要担心 logstash 会漏过你的数据。
logstash File插件配置说明:
一些比较有用的配置项,可以用来指定 FileWatch 库的行为:
path
收集的日志的文件路径
discover_interval
logstash 每隔多久去检查一次被监听的 path 下是否有新文件。默认值是 15 秒。exclude
不想被监听的文件可以排除出去,这里跟 path 一样支持 glob 展开。sincedb_path
如果你不想用默认的 $HOME/.sincedb,可以通过这个配置定义 sincedb 文件到其他位置。sincedb_write_interval
logstash 每隔多久写一次 sincedb 文件,默认是 15 秒。stat_interval
logstash 每隔多久检查一次被监听文件状态(是否有更新),默认是 1 秒。start_position
logstash 从什么位置开始读取文件数据,默认是结束位置,也就是说 logstash 进程会以类似 tail -F 的形式运行。如果你是要导入原有数据,把这个设定改成 “beginning”,logstash 进程就从头开始读取,有点类似 cat,但是读到最后一行不会终止,而是继续变成 tail -F。