作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
首先在本地创建一个/usr/local/bigdatacase/dataset
1.对CSV文件进行预处理生成无标题文本文件,将爬虫大作业产生的csv文件上传到HDFS
首先,我们需要在本地中创建一个/usr/local/bigdatacase/dataset文件夹,具体的步骤为:
① cd /usr/local
② sudo mkdir bigdatacase
③ cd bigdatacase/
④ sudo mkdir dataset
⑤ cd dataset/
其次,我们把lbaiduxinxi1.csv文件放到下载这个文件夹中,并使用命令把baiduxinxi1.csv文件拷贝到我们刚刚所创建的文件夹中,具体步骤如下:
① sudo cp /home/chen/下载/lagoupy.csv /usr/local/bigdatacase/dataset/ #把baiduxinxi1csv文件拷到刚刚所创建的文件夹中
② head -5 lbaiduxinxi1.csv #查看这个文件的前五行
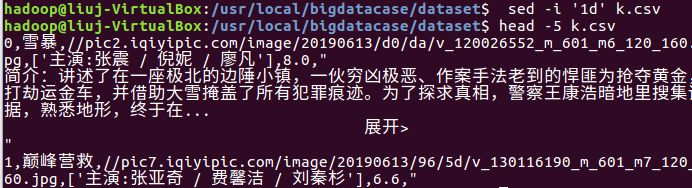
对CSV文件进行预处理生成无标题文本文件,步骤如下:
① sudo sed -i '1d' baiduxinxi1.csv #删除第一行记录
② head -5 baiduxinxi1.csv #查看前五行记录
接着,启动hadoop,步骤如下:
① start-all.sh #启动hadoop
② jps #查看hadoop是否启动成功
如下图所示:

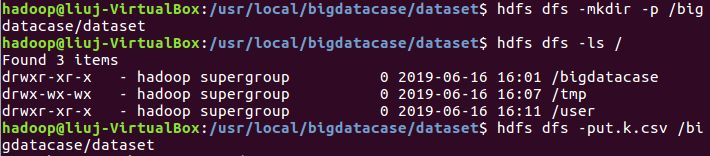
最后,我们把本地的文件上传至HDFS中,步骤如下:
① hdfs dfs -mkdir -p /bigdatacase/dataset #在hdfs上新建/bigdatacase/dataset
② hdfs dfs -ls /
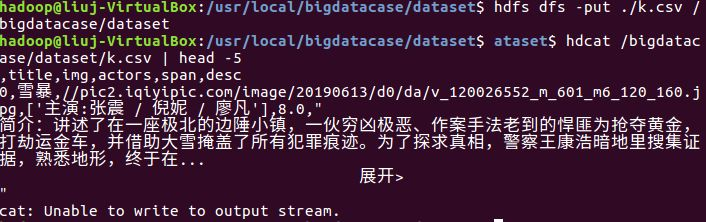
③ hdfs dfs -put ./baiduxinxi1.csv /bigdatacase/dataset #把本地文件lagoupy.csv上传至hdfs中
④ hdfs dfs -ls /bigdatacase/dataset #查看
⑤ hdfs dfs -cat /bigdatacase/dataset/baiduxinxi1.csv | head -5 #查看hdfs中baiduxinxi1.csv的前五行
如下图所示:

把hdfs中的文本文件最终导入到数据仓库Hive中
首先,启动hive,步骤如下:
① service mysql start #启动mysql数据库
② cd /usr/local/hive
③ ./bin/hive #启动hive
如下图所示:
其次,把hdfs中的文本文件最终导入到数据仓库Hive中,并在Hive中查看并分析数据,具体步骤如下:
① create database dbpy; -- 创建数据库

进行数据分析
查看数据库第一的电影电视剧

查看前五条评论

查看第一条最新的五条评论
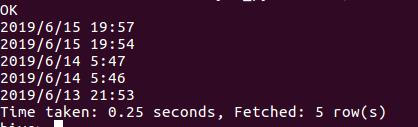
查看数据的分析

查看给电影电视剧的评分的城市前8
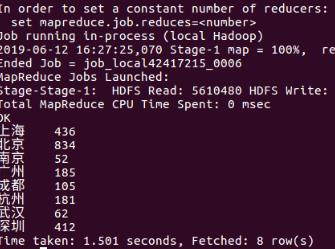
查看点击量高的城市
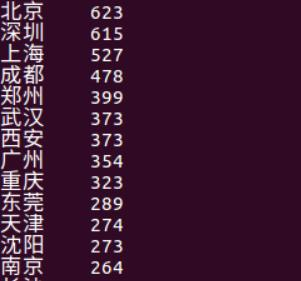
查看评分高的电影前五的产地

查看评分高的五部电影
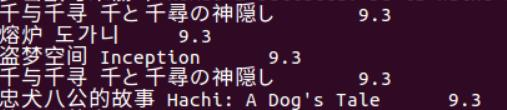
对最高分的电影的最新的评论

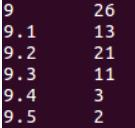
评分在9以上的电影数量