原文:https://ai.googleblog.com/2018/03/mobile-real-time-video-segmentation.html
视频分割(Video segmentation)是一种广泛使用的技术,它使电影导演和视频内容创作者能够将场景的前景与背景分开,并将它们视为两个不同的视觉层。通过修改或替换背景,创作者可以传达特定的情绪,将自己转移到有趣的位置或增强信息的影响力。然而,这个操作传统上是作为一个耗时的手动过程来执行的(例如,艺术家对每一帧进行转描)或者需要一个带有绿屏的工作室环境来实时去除背景(一种称为色度键控的技术))。为了使用户能够在取景器中实时创建这种效果,我们设计了一种适用于手机的新技术。
今天,我们很高兴通过将这项技术集成到故事中,为YouTube 应用程序带来精确、实时、设备上的移动视频分割。目前处于有限测试阶段的 Stories 是 YouTube 的新型轻量级视频格式,专为 YouTube 创作者设计。我们的新分割技术允许创作者更换和修改背景,无需专门设备即可轻松提高视频的制作价值。

为了实现这一点,我们利用机器学习来解决使用卷积神经网络的语义分割任务。特别是,我们设计了一个适用于手机的网络架构和训练程序,重点关注以下要求和约束:
移动解决方案应该是轻量级的,并且运行速度至少比现有最先进的照片分割模型快 10-30 倍。对于实时推理,这样的模型需要以每秒 30 帧的速度提供结果。
视频模型应该利用时间冗余(相邻帧看起来相似)并表现出时间一致性(相邻结果应该相似)
高质量的分割结果需要高质量的注释。
- 移动解决方案应该是轻量级的,并且运行速度至少比现有最先进的照片分割模型快 10-30 倍。对于实时推理,这样的模型需要以每秒 30 帧的速度提供结果。
- 视频模型应该利用时间冗余(相邻帧看起来相似)并表现出时间一致性(相邻结果应该相似)
- 高质量的分割结果需要高质量的注释。
为了为我们的机器学习管道提供高质量的数据,我们注释了数以万计的图像,这些图像捕获了广泛的前景姿势和背景设置。注释由前景元素(如头发、眼镜、脖子、皮肤、嘴唇等)的像素精确位置和通用背景标签组成,交叉验证结果达到人类注释器质量的98 % .

网络输入
我们的具体分割任务是为视频的每个输入帧(三个通道, RGB)计算一个将前景与背景分开的二进制掩码。实现跨帧计算的掩码的时间一致性是关键。当前利用LSTM或GRU来实现这一点的方法对于手机上的实时应用来说计算量太大。相反,我们首先将前一帧的计算掩码作为先验传递,将其作为第四个通道连接到当前 RGB 输入帧以实现时间一致性,如下所示:
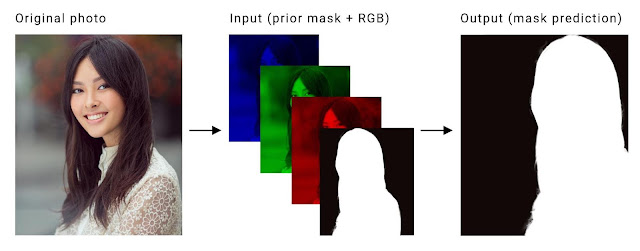
原始帧(左)在其三个颜色通道中分离,并与前一个蒙版(中)连接。这被用作我们神经网络的输入,以预测当前帧的掩码(右)。
训练过程
在视频分割中,我们需要实现帧到帧的时间连续性,同时还要考虑时间不连续性,例如人突然出现在摄像机的视野中。为了训练我们的模型以稳健地处理这些用例,我们以多种方式转换每张照片的带注释的ground truth,并将其用作前一帧掩码:
Empty previous mask - 训练网络正确处理场景中的第一帧和新对象。这模拟了某人出现在相机画面中的情况。
Affine transformed ground truth mask - 对前一帧的Mask的微小变化做训练
Transformed image - 对图片进行“thin plate spline smoothing”, 模拟快速的相机运动和旋转。
网络架构
- 使用修改后的输入/输出,我们通过添加以下改进来构建标准沙漏分段网络架构(hourglass segmentation network architecture)
- 我们使用大步长为 4 及以上的大卷积核来检测高分辨率 RGB 输入帧上的对象特征。具有少量通道的层的卷积(就像 RGB 输入的情况一样)相对便宜,因此在这里使用大内核对计算成本几乎没有影响。
- 为了提高速度,我们使用大步幅结合跳跃连接(如U-Net)积极下采样,以在上采样期间恢复低级特征。对于我们的分割模型,与不使用跳过连接相比,这种技术可以显着提高 5% 的 IOU。
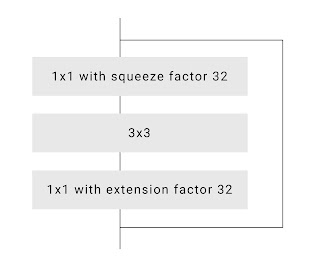
- 为了进一步提高速度,我们优化了默认的ResNet瓶颈。在文献中,作者倾向于将网络中间的通道压缩四倍(例如,通过使用 64 个不同的卷积核将 256 个通道减少到 64 个)。然而,我们注意到一个人可以更积极地挤压 16 或 32 倍而不会显着降低质量。
- 为了改进和提高边缘的准确性,我们在我们的网络之上添加了几个DenseNet层,以类似于神经抠图的全分辨率。该技术将整体模型质量提高了 0.5% IOU,但分割的感知质量显着提高。