转载请注明出处:https://www.cnblogs.com/White-xzx/
原文地址:https://arxiv.org/abs/1812.02425
Github: https://github.com/AaronHeee/MEAL
如有不准确或错误的地方,欢迎交流~
本文来自 AAAI 2019, Oral的一篇文章,主要的思想是通过知识蒸馏的方法将不同的已训练的teachers模型,压缩为一个简单的student网络,来学习多种模型的知识而不用产生额外的测试开销。作者使用的是基于对抗的学习策略,设计了一个block-wise training loss引导和优化预先定义的student网络,进行teachers模型知识的蒸馏,并同时提高辨别器网络(discriminator)对学生和老师提取出的特征的区分能力。
【Abstract】
性能优异的模型通常集成多个基准网络,然而模型的大小和前馈时间限制了这些模型在实际中的应用,尤其是当拥有较大测试集时。本文提出了基于对抗学习策略的模型压缩方法MEAL,该方法包含三个重要的优势:
①学生网络和辨别器一起学习知识能够达到比原始模型更好的优化效果;
②通过简单的学生网络实现更快的前馈速度,同时不降低性能;
③学生可以学习任意结构网络模型的知识。
【Introduction】
该集成方法主要是集合多个网络,将他们在test阶段的预测通过加权平均或选择进行融合。训练时,将经过数据增强的输入经过不同网络结构网络得到的输出,进行集成预测;测试时,只使用一个简单网络;集成的各个网络拥有预训练模型,所以在集成过程中直接加载了预训练模型,使用的监督标签必须和预训练过程使用的标签是一致的。
传统集成方法的不足:①知识或信息冗余;②集成模型非常大且慢;
作者通过不同神经网络的不同输出作为监督来引导目标网络的训练,参考网络作为老师,目标网络作为学生。学生网络训练过程中使用老师网络产生的soft label进行监督训练,作者认为label的信息必须更为翔实,而不是简单地给一张图片提供一个相同的类别,以下是soft label的一个例子:

老师网络给出的soft label提供了不同类别的具体概率分布,使label能提供图片中具有视觉联系场景的信息覆盖。
同时,为了进一步提高学生网络的鲁棒性,作者还引入了对抗学习的策略来使学生网络产生与老师相同的输出。
【Related Work】
【Overview】
与孪生网络相似的网络结构,包括两个分支,分别为老师和学生,两个分支的网络结构可以相同也可以不同,但是为了能够利用两个网络的中间输出,所以两个网络分支必须有相同数目的block。MEAL网络结构如下:
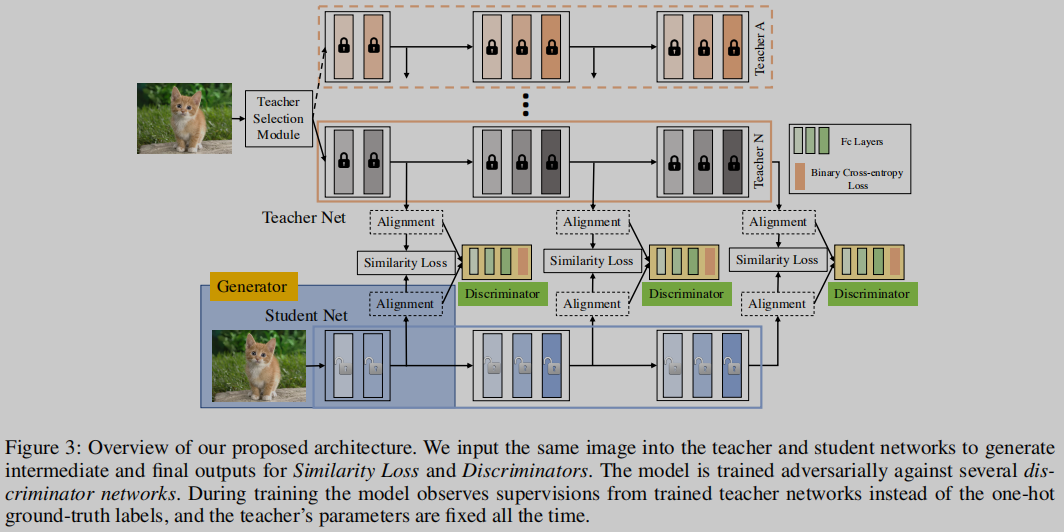
MEAL包括学生网络、老师网络、校准层(alignment layers)、相似度损失层和判别器。学生网络和老师网络产生中间输出进行校正,校正层是一个自适应池化的过程,将相同或不同长度的特征向量作为输入并产生固定长度的新特征。学生网络与几个判别器进行对抗训练,使其产生与老师网络相似的输出。
【Adversarial Learning (AL) for Knowledge Distillation】
【Similarity Measurement】首先,我们在给定的数据集上使用交叉熵损失函数预训练老师网络,label是one-hot类型的图片集标注;学生网络在相同的数据集上进行训练,使用的label是老师网络产生的,即soft label。当学生网络进行训练时,老师网络的参数固定,即不进行学习,同时最小化学生网络输出和soft label的相似度距离。
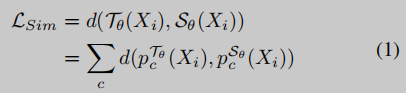
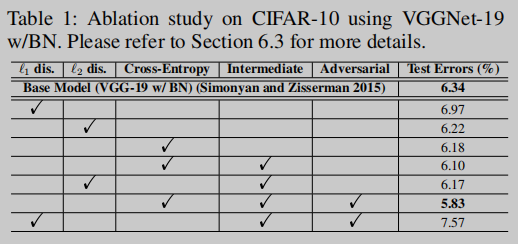
作者尝试了三种距离度量方式,L1、L2和KL-divergence,下文Table 1比较了三种方法的效果。
![]()
![]()
![]()
【Intermediate Alignment】自适应池化:目的是对齐学生网络和老师网络的中间输出,该层与普通的池化层类似,但能对不同的输入产生相同长度的输出;由于这个特殊性,我们能将不同老师网络的输出池化为与学生相同长度的输出。中间输出的损失函数:
![]()
自适应池化的过程:
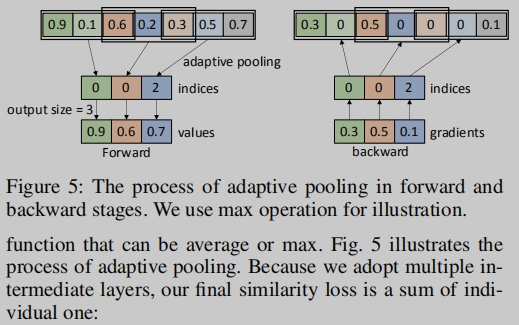
由于采用了多个中间输出层,所以最终的相似度损失为
![]()
【Stacked Discriminators】判别器主要判断输入的x是老师还是学生产生的,最大化以下公式的值,同时学生网络为了尽可能产生于老师相似的输出,所以追求最小化该公式的值
![]()
判别器结构:
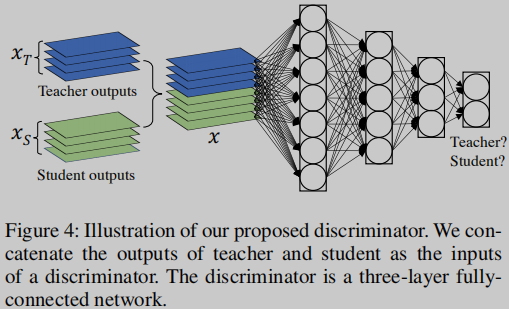
多阶段判别器(Multi-Stage Discriminators),使用多阶段判别器能够逐渐提炼学生的输出,如Figure 3所示。最终的对抗损失是多个判别器损失的和
![]()
【Joint Training of Similarity and Discriminators】最终的损失
![]()
【Multi-Model Ensemble via Adversarial Learning (MEAL)】
【Learning Procedure】为了理解学生网络的学习的内容,作者使用了两种形式:①学生老师使用相同的结构;②选择一种学生网络的结构,在每次迭代的时候随机选择一种网络结构作为老师。
学习过程分两个阶段:①预训练几个老师网络形成model zoo;②最小化公式(11)的值

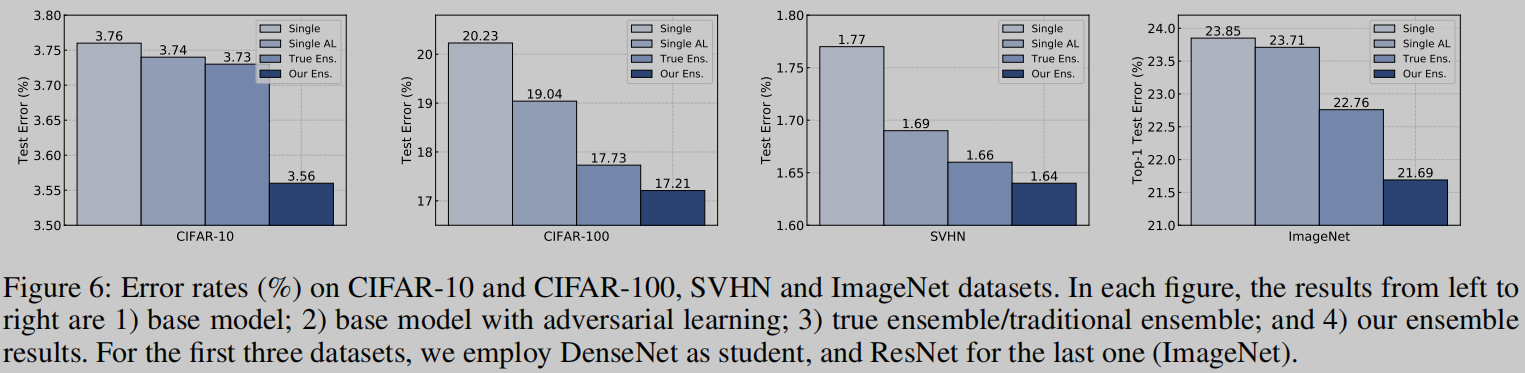
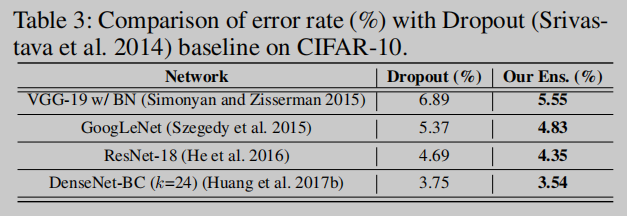
【Experiments and Analysis】