pivot_table()
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, sort=True)
参数:
data:dataframe格式数据
values:需要汇总计算的列,可多选
index:行分组键,一般是用于分组的列名或其他分组键,作为结果DataFrame的行索引
columns:列分组键,一般是用于分组的列名或其他分组键,作为结果DataFrame的列索引
aggfunc:聚合函数或函数列表,默认为平均值,可输入字符串、列表、字典
fill_value:设定缺失替换值
margins:是否添加行列的总计
dropna:默认为True,如果列的所有值都是NaN,将不作为计算列,False时,被保留
margins_name:汇总行列的名称,默认为All
observed:是否显示观测值
举例
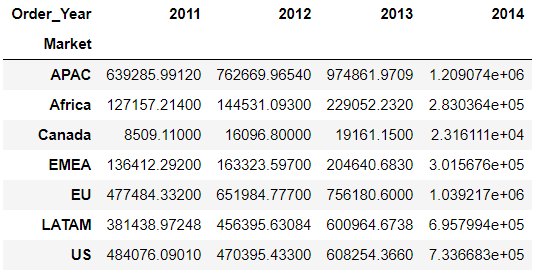
现有DataFrame二维数组sales_area如下,要求统计各地区每一年的销售额总额对比图表

# 使用数据透视表整理数据
sales_area = pd.pivot_table(sales_area,
index='Market',
columns='Order_Year',
values='Sales',
aggfunc='sum')
sales_area
# 使用Pandas直接绘制图表
plt.style.use('ggplot')
sales_area.plot(kind = 'bar',title='各地区分店2011年-2014年销售额综总合对比')

与groupby()对比
1、pivot_table()效率更高
2、pivot_table()将参数放置在方法内