Nice 本身是一款照片分享社区类型的应用,在分享照片和生活态度的同时可以在照片上贴上如品牌、地点、兴趣等tag。
Nice从2013.10月份上线App Store到目前每天2亿PV,服务端架构经过了4次比较大的调整(2014年年底数据)。本次分享将介绍四次架构调整的背景、实践和结果,并讨论如何在人员不足的情况下平衡业务与架构,什么样的架构和开发模式更适合创业团队“天下武功,唯快不破”的做事方式。
本文根据Nice技术合伙人程㭎在ArchSummit全球架构师峰会上的演讲整理而成,点击阅读原文链接,查看演讲视频。
我主要是给大家带来一个Nice服务器端从第一天到现在为止的整个架构的变迁的演进的图,我相信大家在这个演进的过程当中,如果大家有自己去Run一个Startup或者加入一个Startup的时候,你可以以我们的经验为借鉴,看一下我们从头开始是怎么做到一个现在这样的状态的。
我可以先给大家稍微的透露一下我们现在的整个服务器端的一些基本的数据的情况,现在大概是每天五亿的API的请求,不包括图片的CDN的缓存,一共是大概有六千万张照片,每天新增的照片量大概在55万,每周绝大部分的数据是增长6%左右。
Nice这一产品实际上是在2013年的10月份正式上线AppStore的,刚开始的时候只有iOS的版本,当然我们是从9月份的时候,正式的开始去做这个产品。那么在做这个产品的准备上线的时候,我们的第一台服务器是这样的。这台服务器的配置其实非常的低,它的内存只有2G,现在被扔在我们办公室的一个角落当中,连开发机都不愿意使它。因为配置实在太低了。
但就是那样一台服务器,在Nice的初期大概撑了两三个月左右的时间,我们才替换到别的上面。所以在非常初期的时候,其实既没有用户量,也没有用户关系,也没有UGC的数据,一台非常普通的戴尔的服务器,就支撑了Nice所有服务器端的功能。那么现在是什么样子的呢?
2014年的10月份,首先我们自己的服务器已经全部鸟枪换炮了,当然也不是特别高端的服务器,是性价比非常高的一款。而且放到了北京这边一家非常不错的IDC当中。熟悉运维的同学可能知道,这个东西叫PCIe的闪存卡,是一种比SSD还要快的内存的存储的硬件设备,大概6到7万块钱一块。因为现在不缺钱了,所以基本上在DB上面都用这种东西了。
第一次调整架构
那么第一次我们调整服务器架构是在什么时候?时间是在2013年的11月份的下旬。因为随着流量的增长,一台机器根本不可能支撑所有的业务。从现在来看是一个比较明智的决定,我们从自己托管的服务器迁移到了云上。我们从自己处理图片访问,到使用图片云存储,这两个事情做完了之后,基本上把我们的服务器端的人力解放出来,可以把绝大部分的人力投入到业务系统的开发当中,并且能减少非常多的运维的工作。
第一次演进的时候服务器架构调整是这样,我们在青云上面开了五台虚拟主机,第一台虚拟主机是做Nginx代理,同时提供Web业务的服务;还有另外两台虚拟主机,基本上囊括了除了DB、Slave以外的其他的所有的功能,包括做Web业务的处理,做DB的主库,做图片的存储,做Mis系统的后台,还有一台就做一些日常的统计的Job,最后再加上两台DB的Master。

其实非常非常的简单,就是从第一台单机拆成了五台机器,当时的数据量几十万PV每天,几千张照片一天。调整的原则是,在虚拟主机上的功能能合顺就合顺。因为当时好像还不是很有钱,所以还是比较省的。配置最高的虚拟主机是4核16G,但是基本上经过了这一次调整之后,我们的服务器端暂时算是比较的稳定了,这样我们就可以把大部分的人力投入到业务的开发当中。
这个还有一个前提条件,我们在初期的时候,包括到现在为止,工程师一直都是非常少的。就是这些事情,其实都是两个工程师做得。我们服务器端工程师在很长的一段时间之内只有两个。
第二次调整架构
那么这个第一次演进完了之后,我们做了一些功能上的开发和优化,流量又继续在涨,很快这个第一次演进的部署方案就搞不定了,大概的时间是在2014年的3月份就出问题了。
当时出的问题是主库的机器压力过大,这也非常的显而易见。因为主库上面部署了太多的东西,而主库又非常吃IO和CPU。于是当时在现有的这个云平台上面,做了一次架构的升级。第一是机器按照功能进行拆分,先把主库给拆出来;第二个就是做一些基本的冗载和备份的工作。经过第二次演进之后,我们的整个的服务器端的架构是这样的。

首先我们在前面没有只用Nginx做反向代理了,我们引入了一个叫Node Blance,其实是青云自己内部提供的一个HA proxy,核心是这个。接下来,会下发到两台机器proxy上,这就是Nginx去做proxy。
然后我们把图片存储的机器和Mis的机器放在了一台机器上。而把这上面最重的DB master给拆出来。同时我们引入了一个第三方的MySQL proxy,这是360开源的一个MySQL proxy,用它做整个DB这一块的一个代理。
FA的机器,就是前端的机器是两台。因为随着这个业务的发展,也需要引入一些新的东西,在这个时候,我们第一次真真正正的引入了缓存。我们缓存其实直接使用的是Redis。同时我们有一些异步的任务,我们引入了消息队列,我们的消息队列用的是Beanstalk,这两个模块分别部署在两台单独的VM的机器上。
经过这样一拆的话,首先第一是把主库的压力减轻了,因为主库我们可以配最高配置的机器;其次因为有了缓存,所以我们所有的大部分的压力比较大的访问请求或者比较频繁的访问请求,我们可以使用缓存去顶。第三因为引入了消息队列,我们的异步的任务,其实是可以通过消息队列去分发的。当时的状态,大概是上千万的请求,一天;上万张的照片,一天,主库拆到单独的机器,引入了三个新的模块,最后使用了MySQL的proxy做图片分离。
这是在2014年的3月份。很快,因为这个社交产品我们在整个2014年的发展还算比较顺利,所以所有的东西其实都一直在涨,直到这个时候,我们的整个的服务器端的工程师依然是两个。
第三次调整架构
在2014年7月份的时候,又出现了新的问题,这个问题就比较麻烦,就是在青云当时北京的机房,当时他们可能规划的也没有想的特别的清楚,所以对资源的配额上线做的比较小,所以我们整个的单虚拟机的可以分配的资源到了上限,8核32G,我想再分更多的内存和更多的CPU,是已经不支持了;第二个问题是单机房很快也要到达资源的上线了。
因为整个北京机房的整个的资源池当中已经开始报警了,没有太多的可用的空闲的资源。这种情况之下,我们就做了一个现在看起来是非常非常有问题的一个决定,我们决定做双机房。我们再想,既然青云北京机房,一个机房已经搞不定了,那我们再使用青云第二个机房,他们当时正好上了广东机房,也一直在Push我们去使用广东机房。
我们做出了一个草率的决定,用双机房。然后加上容灾和备份。双机房的部署就变得非常的复杂,这个图是我当时做双机房的迁移的时候画的一个架构图,现在看起来实在是乱的已经不能看了。
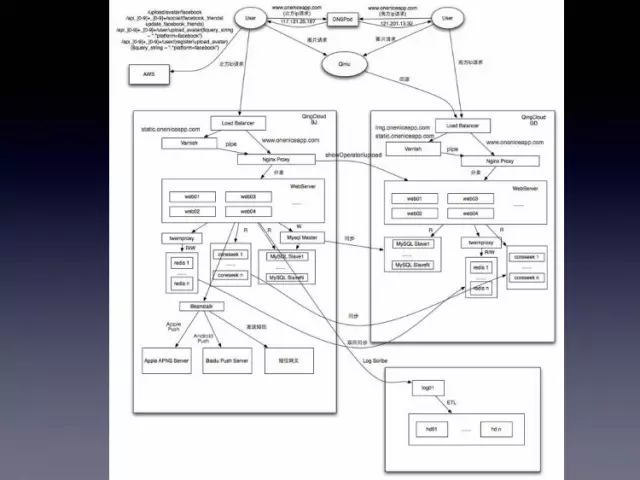

基本上是除了主库放在北京机房以外,其他的所有的东西在第二个机房,原样不动的去搭建一套一模一样的。然后通过DNS的分流,去把流量根据地域分到不同的机房,北京和广东的机房。当然因为那个时候我们发现国外的流量也逐渐起来了,接近10%的国外用户,所以我们在AWS那边也做了一套方案。
这个双机房的方案做上去了以后,又发生了一件很讨厌的事情,就是你天天都在处理线上问题,你没有一天能够清静。这个的时间是在2014年的7月份,这个时候我们有两名服务器端的工程师,加上一名运维工程师。
第四次调整架构
在部署双机房后,我们碰到了太多的问题,让我们大概两个月的时间之内,就没有一天能够在10点以前回家,因为一直有问题。所以我们在2014年的9月份的时候,做了第四次的演进。第四次演进的发现的问题,也就是之前我说的双机房的问题。第一个问题是MySQL的Nginx大小超过32G。这个问题基本上就无解了,除非你分库。因为你青云给你的资源的上限是内存32G,然后你发现MySQL的索引已经超过了32G,然后慢查询就爆增。

第二个问题也就是双机房最大的一个问题,互联是不稳定的,经常会出现数据不一致的情况。因为当时青云的双机房,其实走的是公网,公网的延迟是非常非常不稳定的,在正常的情况下,它也许是能够在三四十毫秒。但是经常会飙升到几千毫秒。
第三个原因,就是天天加班处理线上问题,不能回家陪老婆。于是大概是2014年在9月初吧,9月几号的时候,有一次,我和我们两个服务器端工程师和一个运维工程师,晚上处理完问题在那吃饭,大家一边吃饭,一边骂娘。
最后就说了一句『cao,我们还是自己干吧』。于是我们做出了,现在看起来还比较正确的一个决定,我们从青云迁移回来了,到我们自己的托管服务器,从双机房回归到单机房。
经过第四次的演进,我们的架构图就变得清晰了很多。首先我们在2014年9月份的时候,第一批大概是采购了33、34台物理机,然后做了这样的一些部署,所有的机器都是物理机,前端是两个HA proxy,然后用Keep alive去做护备。然后这两个proxy的下面会连着两个Nginx做方向代理,做请求的分。然后所有的静态资源和以及图片全部会由Varnish去做缓存。然后我们的图片机群用的其实是豆瓣开源出来的一套图片和小图片的存储系统,最下层是四台Beansdb的cluster,上层使用的是Beanseye去做Proxy。
由于我们还使用了七牛的镜像存储,所以基本上我们图片活跃的压力是一次,也就是所有的图片只活跃一次,所以通过这样的一套架构,解决了图片存储和备份的一个问题。静态资源就不用说了,直接往Varnish里面扔。然后两台Nginx下面是有八台的前端机,我们的前端是用TM,所以是八台的TM前端机器。然后前端机器下面是四个比较大的模块,第一个是我们的NoSQL模块,其实都不能叫它缓存了。
因为Redis现在在整个Nice当中的作用已经不止是缓存了,基本上不能挂了,挂了就挂了;第二个是MySQL,MySQL依然是采用主从的方式,一主七从。第三个是Coreseek,我们用Coreseek做Nice当中的检索和推荐。
第四个是消息队列。当然我们后来又大概买了,采购了十几台机器专门做数据平台和数据分析的工作,有两台Log的收集机器,再加上七八台的Hadoop的机群。
经过这一次的部署,我清楚的记得,这个决定大概是在2014年的九月初,九月四五号做得。这个东西的上线是在2014年的九月的第二周的周末。也就是说,从我们解决做这件事情,然后到采购机器,迁机房,然后拆包装,上架,装操作系统,调网络,服务迁移,一共用了一周半的时间。
那么这个事情做完了之后,非常的有意思,这个事情大概是在前一天的凌晨的四点钟最终迁移完成的。做完了以后,从第二天开始,就发现整个世界都清静了,再也没收到报警了。然后所有公司内部人的反馈都是,今天怎么比昨天快了好多。
当然这个架构现在在我们看来其实是有很多的问题的,包括就是如果再过一个月的时间,让我去做这次分享的话,我们会有第五次演进。
这个架构现在的问题,从我们自己的角度来看,第一个最大的问题就是它只有一个机房,它是单点的,这个机房如果出了任何的问题,整个服务是完全不可用。第二个问题是在于Redis的Cluster是没有灾备的机制的,我们现在的Redis是用了四台机器,每台机器开十个实利,每个实例10G的内存,然后前端是用23:24做代理。
如果说Redis我们现在采用的是一致性哈希,一致性哈希最大的问题就是挂了,挂了一台机器,像我们这种情况挂了一台机器1/4的流量就挂了,所以在Redis这块,我们未来也要有一些比较大的改动。
第三块就是双机房的问题,这一次做双机房,我们其实是有一定的经验了。首先,我们是一定要用专线的,否则最底层的这个基础设施如果不稳定的话,你在上层做的任何东西都是掰扯;其次在做双机房的时候,当底层的网络能够达到我们的要求的时候,最重要我们要引入一个消息队列。
这个消息队列最主要的作用就是在同步数据到第二个机房,或者是第三个、第四个机房/因为上层如果没有消息队列去保证这同步数据的一致性,那么你整个的数据一致性的这个问题,未来一定会很大。所以2014年9月份至今为止,我们的架构就是这样的。我们的稳定性现在是3个9,基本上之前就是我所能今天带给大家的全部的内容。