链表是比数组稍微复杂一点的数据结构,也是两个非常重要与基本的数据结构。如果说数组是纪律严明排列整齐的「正规军」那么链表就是灵活多变的「地下党」。
关注公众号 MageByte,有你想要的精彩内容。
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。链表的节点由数据和一个或多个指针域组成。如果不考虑插入、删除操作之前查找元素的过程,只考虑纯粹的插入与删除,那么链表在插入和删除操作上的算法复杂 O(1)。
链表大集结
电影中我们看过,一个特务只知道自己上级、下级的信息,地下党通过这种单线联络的的方式灵活隐秘的传递着消息。链表家族也有多种分类,最简单的单链表、循环链表、双向链表、双向循环链表。
底层数据结构与数组最大的区别,数组需要一块连续的内存空间来存储,而链表并不需要一块连续的内存空间,它通过「指针」将一组零散的内存块串联起来使用。这就是地下党灵活多变的本质原因,可随时切换自己的上下级。
单链表
我们把内存块称为链表的「节点」,为了把所有分散的节点串连起来,每个节点除了存储数据外,还需要记录节点的下一个节点的地址,叫做「后继指针 next」。
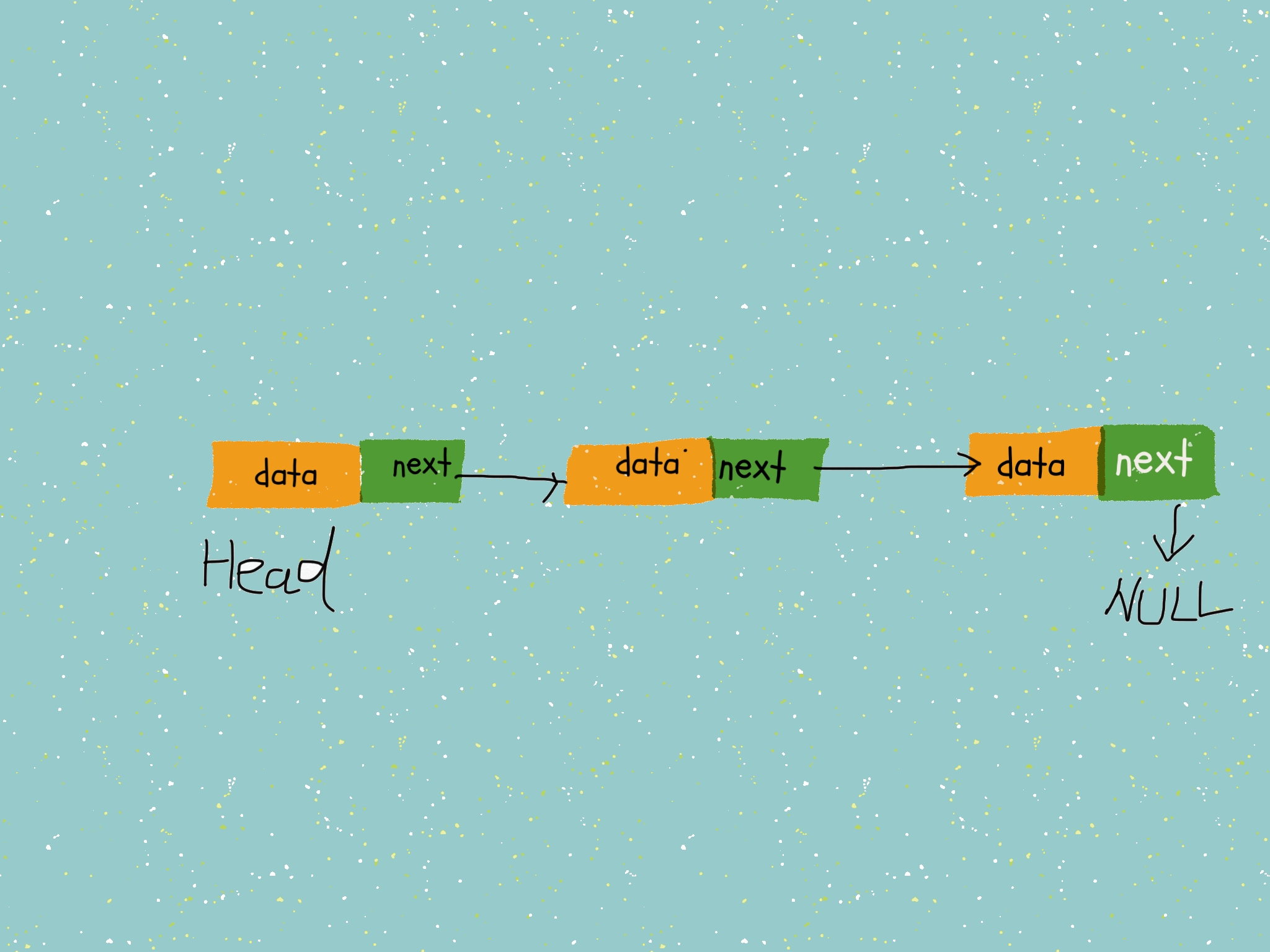
有两个节点需要注意,分别是第一个节点「头节点」和最后一个节点「尾节点」。头结点记录链表的基地址,这样就可以遍历得到整条链表数据,而尾节点的 「next」只想一个 空地址 NULL,代表这是最后一个节点。
链表的删除与插入操作,只需要考虑相邻节点的指针改变,所以时间复杂度是 O(1)。
有利就有弊,链表想要随机访问第 j 个元素,就没有数组高效。链表的数据并不是连续存储的,无法像数组一样根据首地址和下标通过寻址公式就可以计算出对应的 j 位置内存地址,需要根据指针一个一个节点的一次遍历,直到查找到对应的节点。
这个就像地下党组织,每个人只知道自己的后边是谁,想要把消息传到 k 特务,就需要从消息发布者开始通知他的下一级,直到 k 为止。所以随机访问的性能没有数组好,时间复杂度是 O(n)。
插入节点
尾部插入
与数组类似,插入节点也可以分头部插入、中部插入、尾部插入。尾部插入最简单,把最后一个节点的「next」指针指向新插入的节点即可。
头部插入
分为两个步骤。
第一步,把新节点的「next」指针指向原先的头节点。
第步,把新节点变为链表的头节点。
中间插入
同样分为两个步骤。
- 把插入位置的节点前置节点的「next」指针指向指定插入的新节点。
- 将新节点的「next」指针指向前置节点的「next」指针原先所指定的节点。
删除节点
单链表的删除也分为三种情况。
- 头部删除
- 中部删除
- 尾部删除
尾部删除最简单,把倒数第二个节点的「next」指针指向 null,同时把要删除的节点全都设置 null 让垃圾收集器回收即可。
头部删除,把原先链表的头节点的「next」节点设置成头结点,并且把原来的头结点设置 null 便于 gc 即可。
中间删除,把要删除的节点前置节点的「next」指针指向被删除节点的「next」指针即可。
对于删除与插入,只要我们画下图就很清晰了。
循环链表
循环链表是一种特殊的单链表。实际上,循环链表也很简单。它跟单链表唯一的区别就在尾结点。我们知道,单链表的尾结点指针指向空地址,表示这就是最后的结点了。而循环链表的尾结点指针是指向链表的头结点。从我画的循环链表图中,你应该可以看出来,它像一个环一样首尾相连,所以叫作“循环”链表。
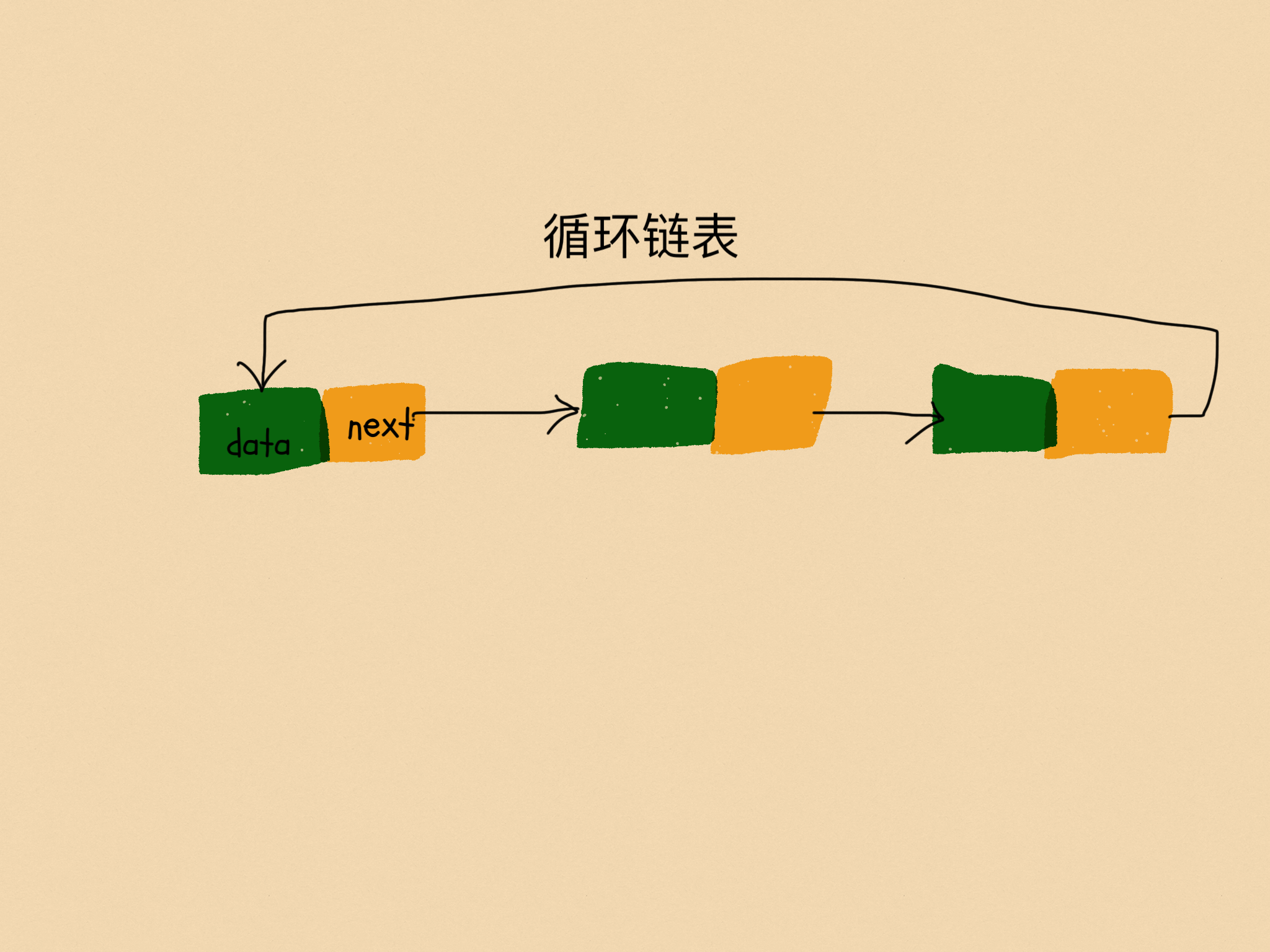
跟单链表差别不大,主要就是尾部节点遍历到头部节点方便。
双向链表
实际开发中最常见的链表-双向链表。Java 中的 LinkedList就是一个双向链表。
单链表只有一个方向,每个节点只有一个后继指针 「next」指向下一个节点。双向链表则是有两个指针,每个节点分别有一个「next」指针指向后面节点和一个「prev」指针指向前置节点。
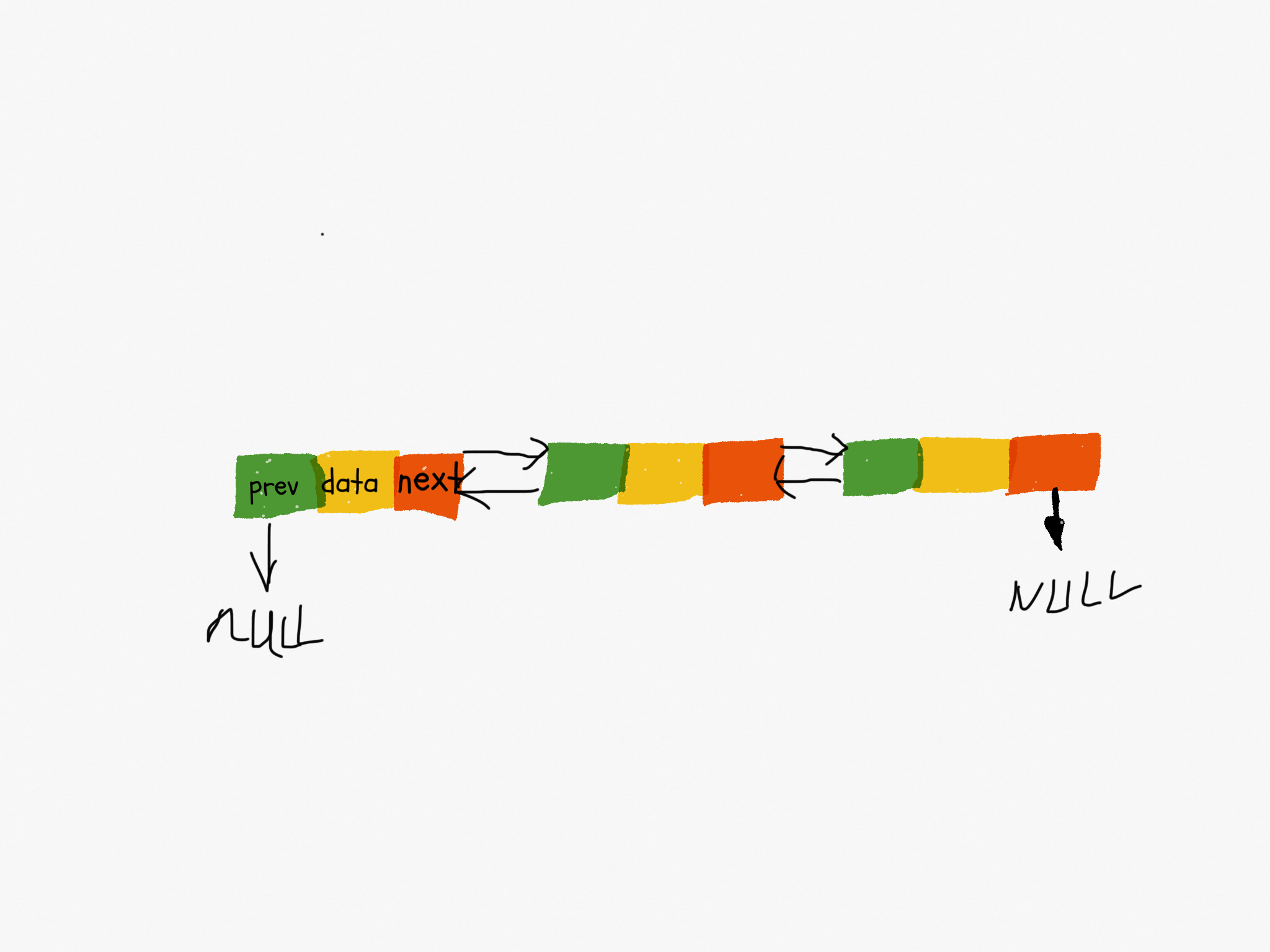
可以看出来,双向链表需要额外的两个空间存储后继节点和前驱节点地址。所以存储同样多的数据,双向链表比单项链表占用更多的空间,但是优势则是可以双向遍历。
双向链表可以支持在 O(1) 时间复杂度情况定位到前驱结点,正是这样的特点,也使双向链表在某些情况下的插入、删除等操作都要比单链表简单、高效。
之前我们说单项链表的删除、插入时间复杂度是 O(1)了,那为啥这里还说双向链表的删除、插入还能更高效呢?
从链表删除一个元素,其实有两种情况:
- 删除「值等于给定的内容」的节点。
- 删除给定指针指向的节点。
第一种情况,其实都一样,不管是单项还是双向都需要从头节点遍历比对找到要删除的节点。
对于第二种情况,我们已经找到了要删除的结点,但是删除某个结点 q 需要知道其前驱结点,而单链表并不支持直接获取前驱结点,所以,为了找到前驱结点,我们还是要从头结点开始遍历链表,直到 p->next=q,说明 p 是 q 的前驱结点。
但是对于双向链表来说,这种情况就比较有优势了。因为双向链表中的结点已经保存了前驱结点的指针,不需要像单链表那样遍历。所以,针对第二种情况,单链表删除操作需要 O(n) 的时间复杂度,而双向链表只需要在 O(1) 的时间复杂度内就搞定了!
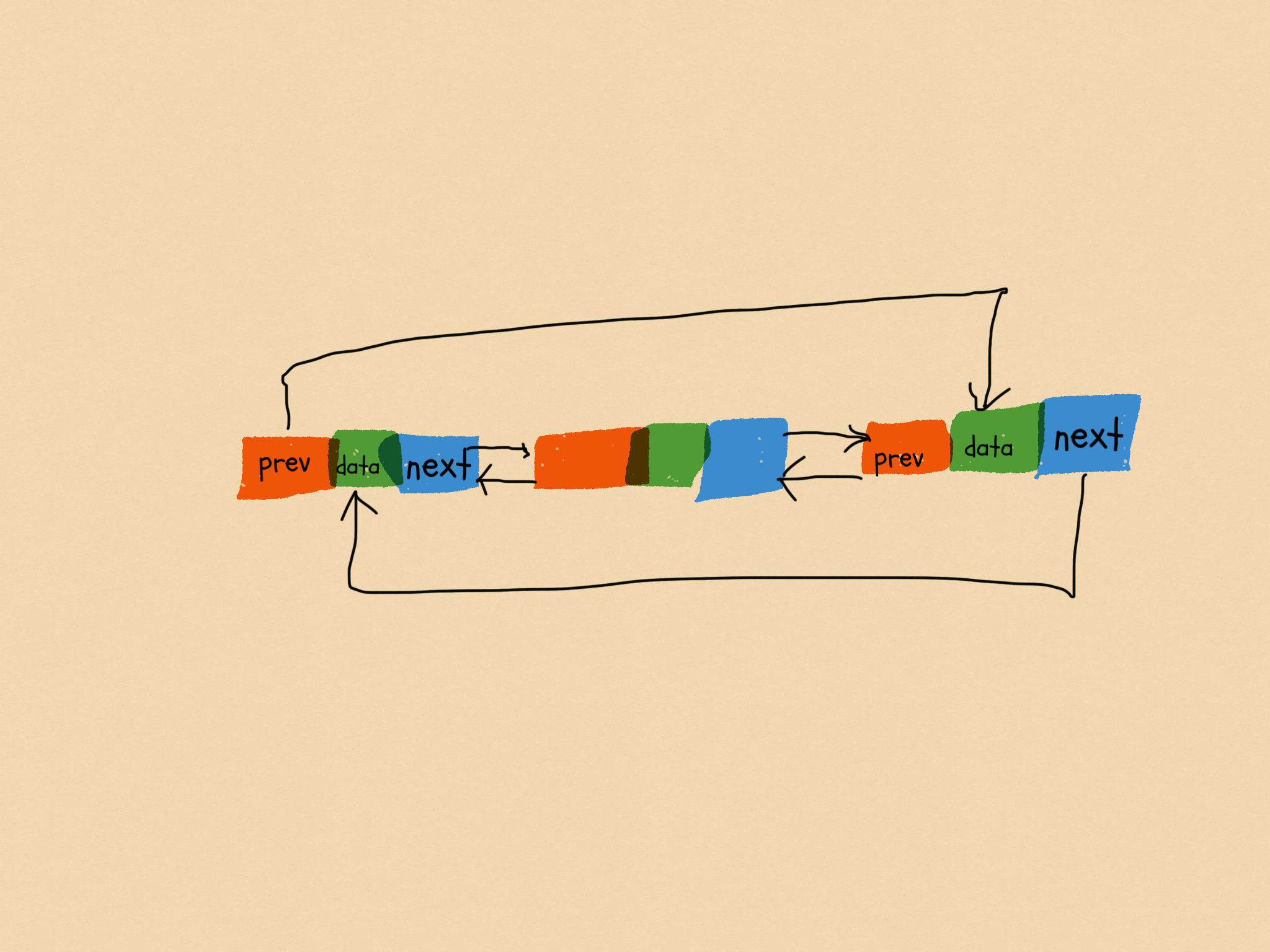
双向循环链表
数组与链表性能比较
数组和链表都属于线性的数据结构,用哪一个好呢?其实数据结构没有绝对的好坏,各有千秋。
| 查找 | 更新 | 删除 | 插入 | |
|---|---|---|---|---|
| 数组 | O(1) | O(1) | O(n) | O(n) |
| 链表 | O(n) | O(1) | O(1) | O(1) |
数组简单易用,在实现上使用的是连续的内存空间,可以借助 CPU 的缓存机制,预读数组中的数据,所以访问效率更高。而链表在内存中并不是连续存储,所以对 CPU 缓存不友好,没办法有效预读。
对链表进行频繁的插入、删除操作,还会导致频繁的内存申请和释放,容易造成内存碎片,如果是 Java 语言,就有可能会导致频繁的 GC(Garbage Collection,垃圾回收)。
本文讲解了链表的理论原理与知识,下一篇将代码实操撸一遍。
课后作业
如何基于链表实现一个 LRU 缓存淘汰算法?公众号后台回复 LRU,可以获取答案。
欢迎加群与我们讨论分享,我们第一时间反馈。

推荐阅读
4.线性表之数组