一、功能背景:
1.一直在完善公司内部的数据驱动平台系统,最近给我一个值班表的功能,大体功能需求如图(展示每月值班表,需要实现编辑、打印、模板及生成PDF)
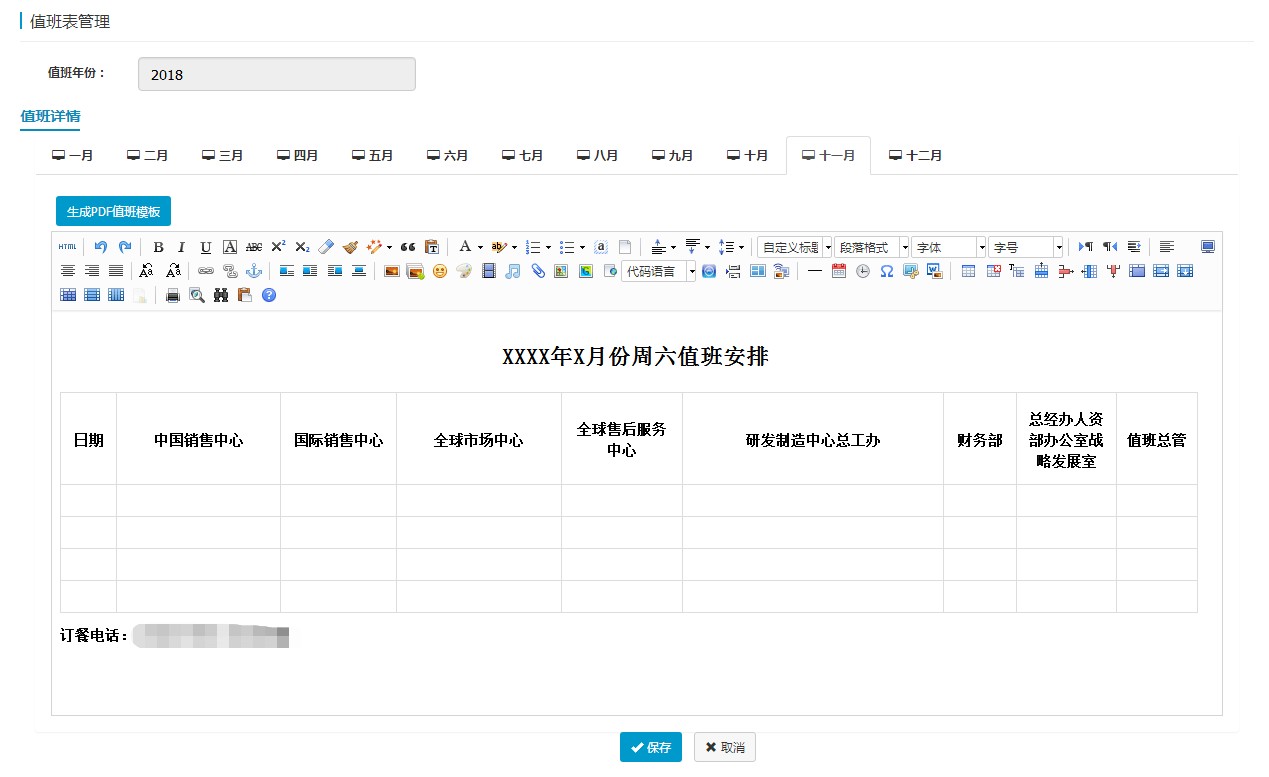
二、功能介绍
1.前三个编辑、打印、模板功能使用UEditor编辑器都能轻松实现
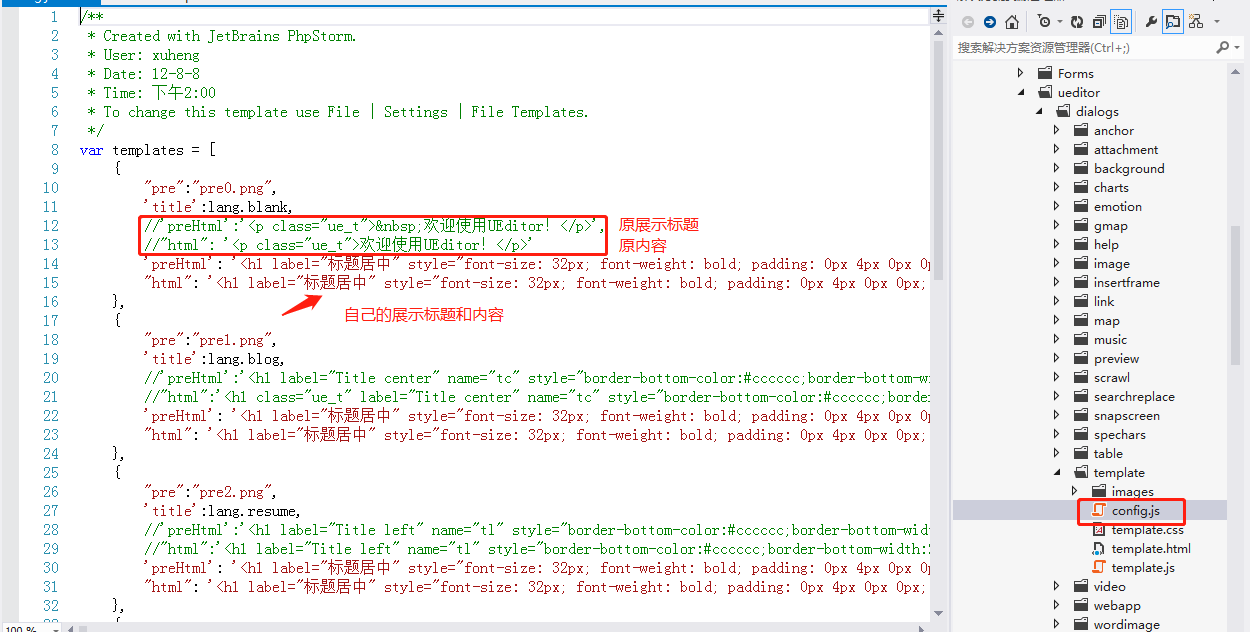
ueditor模板修改:①.找到目录下 ueditor/dialogs/template/config.js 文件,将原模板的标题及内容替换成自己的就OK
②.若替换后不显示,清一下浏览器缓存就OK了
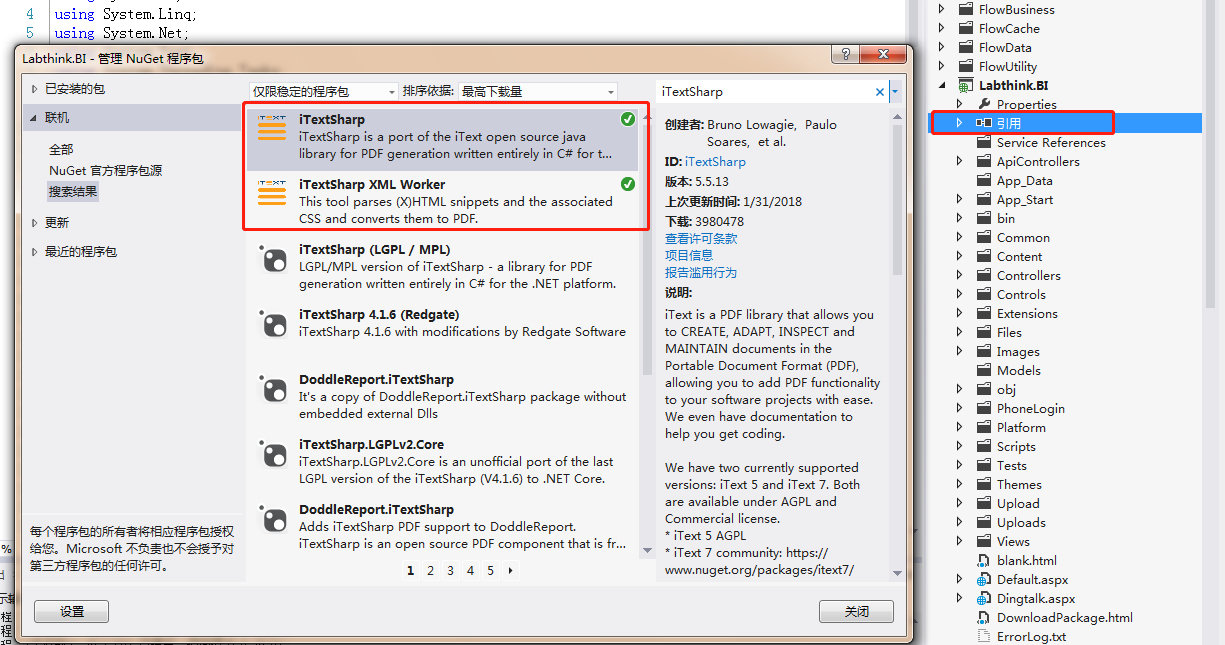
2.比较头疼的便是将tab标签下的网页上展示的内容生成PDF模板的功能,自己查了一下午还是觉得iTextSharp比较容易操作。
第一步:我们先将iTextSharp所需要引用的NuGet程序包添加安装到项目中(添加引用——管理NuGet程序包——联机搜索iTextSharp——安装)
第二步:创建PDFHelper帮助类(标红的为使用iTextSharp需要引用的)
1 using System; 2 using System.Collections.Generic; 3 using System.IO; 4 using System.Linq; 5 using System.Net; 6 using System.Text; 7 using System.Threading.Tasks; 8 using System.Web; 9 using iTextSharp.text; 10 using iTextSharp.text.pdf; 11 using iTextSharp.tool.xml; 12 13 namespace Labthink.BI.Helpers 14 { 15 /// <summary> 16 /// Html字符串转PDF输出帮助类 17 /// </summary> 18 public class HtmlToPdfHelper 19 { 20 #region HtmlToPDF 21 22 /// <summary> 23 /// 判断是否有乱码 24 /// </summary> 25 /// <param name="txt"></param> 26 /// <returns></returns> 27 private static bool IsMessyCode(string txt) 28 { 29 var bytes = Encoding.UTF8.GetBytes(txt); 30 for (var i = 0; i < bytes.Length; i++) 31 { 32 if (i < bytes.Length - 3) 33 if (bytes[i] == 239 && bytes[i + 1] == 191 && bytes[i + 2] == 189) 34 { 35 return true; 36 } 37 } 38 return false; 39 } 40 41 /// <summary> 42 /// 将Html字符串 输出到PDF档里 43 /// </summary> 44 /// <param name="htmlText"></param> 45 /// <returns></returns> 46 public static byte[] ConvertHtmlTextToPdf(string htmlText) 47 { 48 return ConvertHtmlTextToPdf(htmlText, "", 0, 0, 0, 0); 49 } 50 51 /// <summary> 52 /// 将Html字符串 输出到PDF档里,并添加水印 53 /// </summary> 54 /// <param name="htmlText">网页代码</param> 55 /// <param name="picPath">水印路径</param> 56 /// <param name="left">距离左边距离</param> 57 /// <param name="top">距顶部距离</param> 58 /// <param name="width">水印宽度</param> 59 /// <param name="height">水印高度</param> 60 /// <returns></returns> 61 public static byte[] ConvertHtmlTextToPdf(string htmlText, string picPath, int left, int top, int width, int height) 62 { 63 if (string.IsNullOrEmpty(htmlText)) 64 { 65 return null; 66 } 67 //避免当htmlText无任何html tag标签的纯文字时,转PDF时会挂掉,所以一律加上<p>标签 68 htmlText = "<p>" + htmlText + "</p>"; 69 MemoryStream outputStream = new MemoryStream();//要把PDF写到哪个串流 70 byte[] data = Encoding.UTF8.GetBytes(htmlText);//字串转成byte[] 71 MemoryStream msInput = new MemoryStream(data); 72 //Rectangle rect = new Rectangle(11 * 72, 8.5f * 72);自定义纸张大小 73 Document doc = new Document(PageSize._11X17, 20, 0, 20, 0);//要写PDF的文件,建构子没填的话预设直式A4 74 PdfWriter writer = PdfWriter.GetInstance(doc, outputStream); 75 //指定文件预设开档时的缩放为100% 76 PdfDestination pdfDest = new PdfDestination(PdfDestination.XYZ, 0, doc.PageSize.Height, 1f); 77 //开启Document文件 78 doc.Open(); 79 80 //写入水印图片 81 if (!string.IsNullOrEmpty(picPath)) 82 { 83 Image img = Image.GetInstance(picPath); 84 //设置图片的位置 85 img.SetAbsolutePosition(width + left, (doc.PageSize.Height - height) - top); 86 //设置图片的大小 87 img.ScaleAbsolute(width, height); 88 doc.Add(img); 89 } 90 try 91 { 92 //使用XMLWorkerHelper把Html parse到PDF档里 93 XMLWorkerHelper.GetInstance().ParseXHtml(writer, doc, msInput, null, Encoding.UTF8); 94 //将pdfDest设定的资料写到PDF档 95 PdfAction action = PdfAction.GotoLocalPage(1, pdfDest, writer); 96 writer.SetOpenAction(action); 97 } 98 catch (Exception) 99 { 100 return null; 101 } 102 doc.Close(); 103 msInput.Close(); 104 outputStream.Close(); 105 //回传PDF档案 106 return outputStream.ToArray(); 107 } 108 109 #endregion 110 该注释掉的方法为获取某文件下的HTML代码来生成PDF,因为我是直接取的数据库中存的HTML代码,所以改成了下面的方法。 111 /// <summary> 112 /// 获取网站内容,包含了 HTML+CSS+JS 113 /// </summary> 114 /// <returns>String返回网页信息</returns> 115 //public static string GetWebContent(string inpath) 116 //{ 117 // try 118 // { 119 // WebClient myWebClient = new WebClient(); 120 // //获取或设置用于向Internet资源的请求进行身份验证的网络凭据 121 // myWebClient.Credentials = CredentialCache.DefaultCredentials; 122 // //从指定网站下载数据 123 // Byte[] pageData = myWebClient.DownloadData(inpath); 124 // //如果获取网站页面采用的是GB2312,则使用这句 125 // string pageHtml = Encoding.UTF8.GetString(pageData); 126 // bool isBool = IsMessyCode(pageHtml);//判断使用哪种编码 读取网页信息 127 // if (!isBool) 128 // { 129 // string pageHtml1 = Encoding.UTF8.GetString(pageData); 130 // pageHtml = pageHtml1; 131 // } 132 // else 133 // { 134 // string pageHtml2 = Encoding.Default.GetString(pageData); 135 // pageHtml = pageHtml2; 136 // } 137 // return pageHtml; 138 // } 139 // catch (WebException webEx) 140 // { 141 // return webEx.Message; 142 // } 143 //} 144 public static string GetWebContent(string monthContent) 145 { 146 try 147 { 148 WebClient myWebClient = new WebClient(); 149 //获取或设置用于向Internet资源的请求进行身份验证的网络凭据 150 myWebClient.Credentials = CredentialCache.DefaultCredentials; 151 //从指定网站下载数据 152 //Byte[] pageData = myWebClient.DownloadData(inpath); 153 //如果获取网站页面采用的是GB2312,则使用这句 154 string pageHtml = monthContent; 155 //bool isBool = IsMessyCode(pageHtml);//判断使用哪种编码 读取网页信息 156 //if (!isBool) 157 //{ 158 // string pageHtml1 = Encoding.UTF8.GetString(pageData); 159 // pageHtml = pageHtml1; 160 //} 161 //else 162 //{ 163 // string pageHtml2 = Encoding.Default.GetString(pageData); 164 // pageHtml = pageHtml2; 165 //} 166 return pageHtml; 167 } 168 catch (WebException webEx) 169 { 170 return webEx.Message; 171 } 172 } 173 174 /// <summary> 175 /// 将pdf文件流输出至浏览器下载 176 /// </summary> 177 /// <param name="pdfFile">PDF文件流</param> 178 public static void PdfDownload(byte[] pdfFile,string title) 179 { 180 byte[] buffer = pdfFile; 181 Stream iStream = new MemoryStream(buffer); 182 try 183 { 184 int length; 185 long dataToRead; 186 //string filename = DateTime.Now.ToString("yyyyMMddHHmmss") + ".pdf";//保存的文件名称 187 string filename = title + ".pdf"; 188 dataToRead = iStream.Length; 189 HttpContext.Current.Response.Clear(); 190 HttpContext.Current.Response.ClearHeaders(); 191 HttpContext.Current.Response.ClearContent(); 192 HttpContext.Current.Response.ContentType = "application/pdf"; //文件类型 193 HttpContext.Current.Response.AddHeader("Content-Length", dataToRead.ToString());//添加文件长度,进而显示进度 194 HttpContext.Current.Response.AddHeader("Content-Disposition", "attachment; filename=" + HttpUtility.UrlEncode(filename, Encoding.UTF8)); 195 while (dataToRead > 0) 196 { 197 if (HttpContext.Current.Response.IsClientConnected) 198 { 199 length = buffer.Length; 200 HttpContext.Current.Response.OutputStream.Write(buffer, 0, length); 201 HttpContext.Current.Response.Flush(); 202 buffer = new Byte[length]; 203 dataToRead = dataToRead - length; 204 } 205 else 206 { 207 dataToRead = -1; 208 } 209 } 210 } 211 catch (Exception ex) 212 { 213 HttpContext.Current.Response.Write("文件下载时出现错误!"); 214 } 215 finally 216 { 217 if (iStream != null) 218 { 219 iStream.Close(); 220 } 221 //结束响应,否则将导致网页内容被输出到文件,进而文件无法打开 222 HttpContext.Current.Response.Flush(); 223 HttpContext.Current.Response.End(); 224 } 225 } 226 } 227 }
第三步:控制器中需要添加的代码
/// <summary>
/// 获取MVC视图Html
/// </summary>
/// <param name="context">控制器上下文</param>
/// <param name="viewName">视图名称</param>
/// <param name="param"></param>
/// <returns></returns>
public static string GetViewHtml(ControllerContext context, string viewName)
{
if (string.IsNullOrEmpty(viewName))
viewName = context.RouteData.GetRequiredString("action");
using (var sw = new StringWriter())
{
ViewEngineResult viewResult = ViewEngines.Engines.FindPartialView(context, viewName);
var viewContext = new ViewContext(context, viewResult.View, context.Controller.ViewData, context.Controller.TempData, sw);
try
{
viewResult.View.Render(viewContext, sw);
}
catch (Exception ex)
{
throw;
}
return sw.GetStringBuilder().ToString();
}
}
[NoAuthorization]
public ActionResult IndexPdf(string Year, string month)
{
//获取值班内容
string monthContent = helper.GetRotaMonth(Year, month);
//值班标题
string title = "";
//从网址下载Html字符串(方法一)
//string inpath = System.Web.HttpContext.Current.Server.MapPath("~/Upload/Rota/September.html");
//string htmlText = HtmlToPdfHelper.GetWebContent(inpath)//如果读取文件中的HTML代码调用此方法
string htmlText = HtmlToPdfHelper.GetWebContent(monthContent);//这是调用的我获取的数据库中的内容
//获取MVC视图Html字符串(方法二)
//string htmlText = GetViewHtml(ControllerContext, "EditIndex");
//如果直接调用视图中的HTML调调用此方法,不建议用此方法,因为视图中有数据会是动态生成的,这时会获取不到报错
//水印图片路径
//string picPath = Server.MapPath("~/PDFTemplate/TemplateImg/authentication-iocn.png");
//string picPath = Server.MapPath("~/Upload/Rota/authentication-iocn.png");
//html转pdf并加上水印
//byte[] pdfFile = HtmlToPdfHelper.ConvertHtmlTextToPdf(htmlText, "", 100, 200, 100, 100);
byte[] pdfFile = HtmlToPdfHelper.ConvertHtmlTextToPdf(htmlText);
//输出至客户端
HtmlToPdfHelper.PdfDownload(pdfFile, title);//此处调用步骤6方法
return View();
}
这就是使用iTextSharp生成PDF的方法,但是生成的PDF格式和正常做的会稍有不同。