一、获取网页链接
找到自己想要爬取的文章把它们加入urls字典中
1 def get_url():
2 urls=[]#获取多条网页链接将它们存入urls中
3 urls.append('http://daily.zhihu.com/story/9717314')
4 urls.append('http://daily.zhihu.com/story/9717526')
5 urls.append('http://daily.zhihu.com/story/9717328')
6 return urls
二、存储操作
把获取的内容存进csv文件夹
1 def html_save(s):
2 with open('save.csv','a')as f:#以a的方式表示把内容追加到已有内容的后面
3 f.write(s+'
')
三、网页解析
对得到的网页链接进行内容的爬取并存储
1 def parse_html(url):
2 headers = {
3 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
4 }#在网页面获取访问头
5 docx=requests.get(url,headers=headers)#用requests获取网页,调用访问头进入访问否则可能会不被允许。
6 soup=BeautifulSoup(docx.text,'html.parser')#用beutifulsoup进行解析
7 c_txt=soup.find('div',{'class':'content'})#在网页界面找到需要查找的信息名称进行find
8 for i in c_txt:
9 if i.string!=None:#当查找的信息不为空
10 s=i.string.replace('
','')#把查找到的内容
替换为空格
11 if s!='':#把不为空的部分进行存储操作
12 print(s)
13 html_save(s)
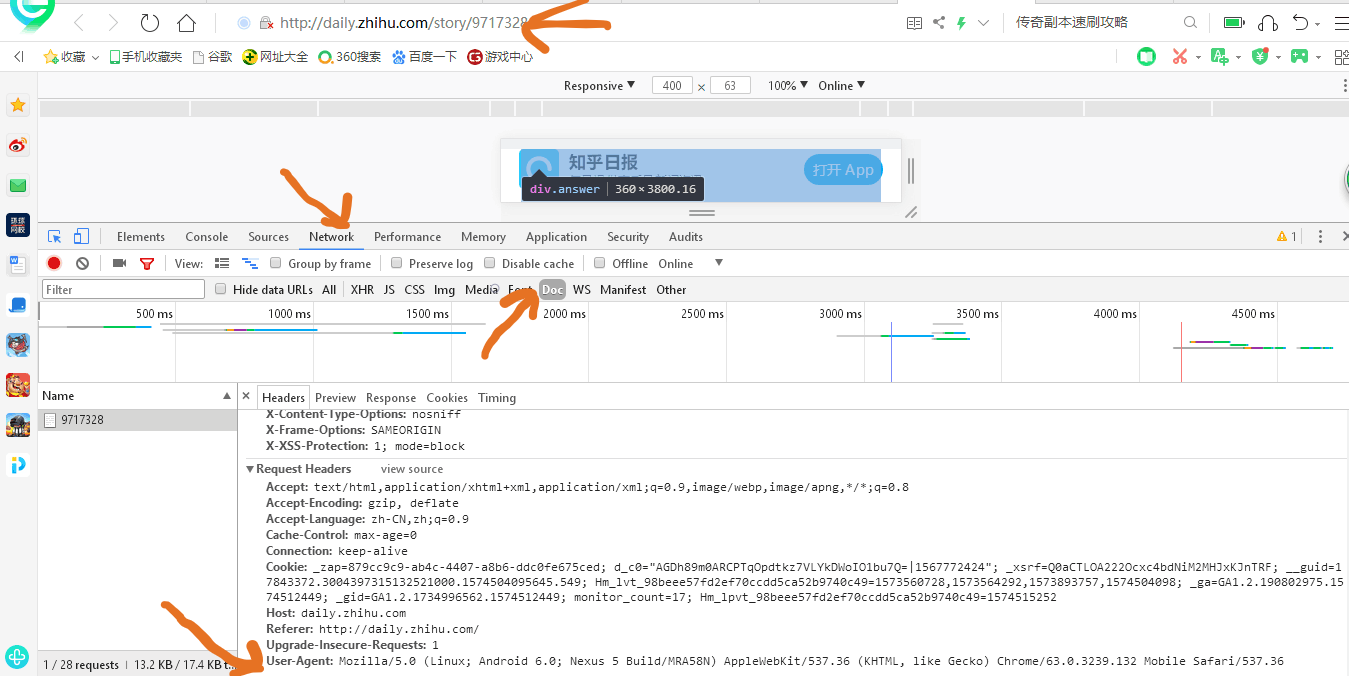
获取头请求:
最后一行就是我们的请求头
四、对多条网页链接进行爬取
把get_url里面存储的网页链接取出来进行判断如果不为空就进行解析操作,否则跳出。
1 def parse_htmls(n):#进行多网页爬取存储
2 for url in get_url():#把网页进行判断解析
3 if url!=None:#不为空就进行解析输出
4 parse_html(url)
5 print('parse sucsses!')
6 else:#为空则结束本次循环进入下一循环
7 print('None html')
8 continue
五、源代码
1 import requests
2 from bs4 import BeautifulSoup
3
4 def get_url():
5 urls=[]#获取多条网页链接将它们存入urls中
6 urls.append('http://daily.zhihu.com/story/9717314')
7 urls.append('http://daily.zhihu.com/story/9717526')
8 urls.append('http://daily.zhihu.com/story/9717328')
9 return urls
10
11 def html_save(s):
12 with open('save.csv','a')as f:#以a的方式表示把内容追加到已有内容的后面
13 f.write(s+'
')
14
15 def parse_html(url):
16 headers = {
17 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
18 }#在网页面获取访问头文件
19 docx=requests.get(url,headers=headers)#用requests获取网页,头文件进入访问否则可能会不被允许。
20 soup=BeautifulSoup(docx.text,'html.parser')#用beutifulsoup进行解析
21 c_txt=soup.find('div',{'class':'content'})#在网页界面找到需要查找的信息名称进行find
22 for i in c_txt:
23 if i.string!=None:#当查找的信息不为空
24 s=i.string.replace('
','')#把查找到的内容
替换为空格
25 if s!='':#把不为空的部分进行存储操作
26 print(s)
27 html_save(s)
28
29 def parse_htmls(n):#进行多网页爬取存储
30 for url in get_url():#把网页进行判断解析
31 if url!=None:#不为空就进行解析输出
32 parse_html(url)
33 print('parse sucsses!')
34 else:#为空则结束本次循环进入下一循环
35 print('None html')
36 continue
37
38 parse_htmls(3)#解析三条网页信息
六、运行结果
爬取结果:
爬取成功输出parse sucsses!提示

存储结果:
爬取内容存入csv文件夹如下

欢迎大家提出建议!