数据分析重要步骤:
1.数据获取
可以进行人工收集获取部分重要数据
可以在各个数据库中导出数据
使用Python的爬虫等技术
2.数据整理
从数据库、文件中提取数据,生成DataFrame对象
采用pandas库读取文件
3.数据处理
数据准备:
对DataFrame对象(多个)进行组装、合并等操作
pandas操作
数据转化:
类型转化、分类(面元等)、异常值检测、过滤等
pandas库的操作
数据聚合:
分组(分类)、函数处理、合并成新的对象
pandas库的操作
4.数据可视化
将pandas的数据结构转化为图表的形式
matplotlib库
5.预测模型的创建和评估
数据挖掘的各种算法:
关联规则挖掘、回归分析、聚类、分类、时序挖掘、序列模式挖掘等
6.部署(得出结果)
从模型和评估中获得知识
知识的表示形式:规则、决策树、知识基、网络权值
原网址:https://blog.csdn.net/qq_35187510/article/details/80078143
爬取网页数据步骤:
简介:
(1)网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者):
是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据。
(2)爬虫可以做什么?
你可以用爬虫爬图片,爬取视频等等你想要爬取的数据,只要你能通过浏览器访问的数据都可以通过爬虫获取。当你在浏览器中输入地址后,经过DNS服务器找到服务器主机,向服务器发送一个请求,服务器经过解析后发送给用户浏览器结果,包括html,js,css等文件内容,浏览器解析出来最后呈现给用户在浏览器上看到的结果
所以用户看到的浏览器的结果就是由HTML代码构成的,我们爬虫就是为了获取这些内容,通过分析和过滤html代码,从中获取我们想要资源。
页面获取
1.根据URL获取网页
- URL处理模块(库)
import urllib.request as req - 创建一个表示远程url的类文件对象
req.urlopen(' ') - 如同本地文件一样读取内容
import urllib.request as req # 根据URL获取网页: #http://www.hbnu.edu.cn/湖北师范大学 url = 'http://www.hbnu.edu.cn/' webpage = req.urlopen(url) # 按照类文件的方式打开网页 # 读取网页的所有数据,并转换为uft-8编码 data = webpage.read().decode('utf-8') print(data)
2.网页数据存入文件
#将网页爬取内容写入文件 import urllib.request url = "http://www.hbnu.edu.cn/" responces = urllib.request.urlopen(url) html = responces.read() html = html.decode('utf-8') fileOb = open('C://Users//ALICE//Documents//a.txt','w',encoding='utf-8') fileOb.write(html) fileOb.close()
此时我们从网页中获取的数据已保存在我们指定的文件里,如下图所示:
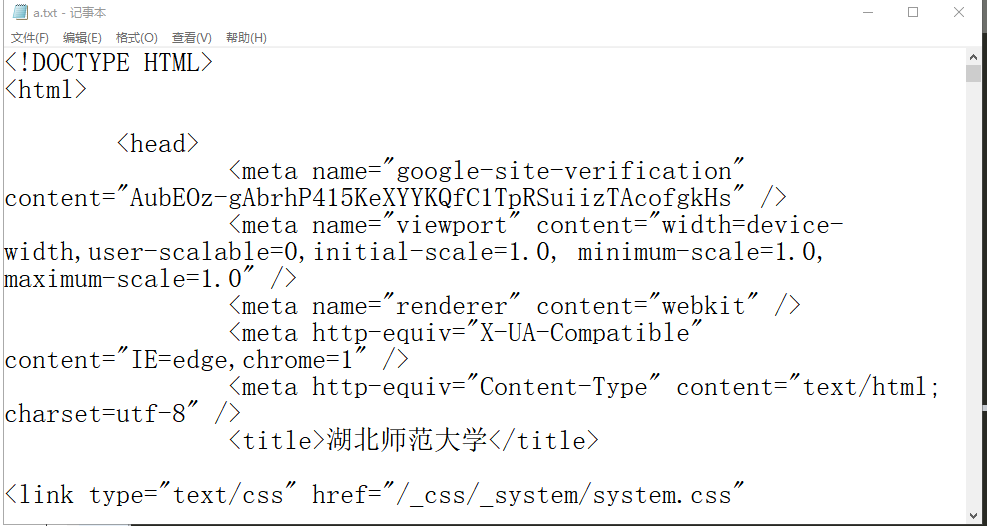
网页获取
从图中可以看出,网页的所有数据都存到了本地,但是我们需要的数据大部分都是文字或者数字信息,而代码对我们来说并没有用处。那么我们接下来要做的是清除没用的数据。
之后需要数据清洗,接下来的请听下回分解。