最近要开始读论文了,其实自己读论文的能力挺不怎么样的,并且读过就忘记,这实在是让人很不爽的事情。自己分析记不住的原因可以有以下几点:
- 读论文时理解就不深刻,有时候就是一知半解的
- 读完之后没有总结,即没有自己概括这篇论文的过程,所以文中一知半解的过程还是忽略了,并且以后再回顾的时候,这篇论文对自己来说就像新的论文一样,还是一样懵。
所以,我决定对读的每一篇论文都做一个总结,并发表在博客上。如果有人能强忍着“这人写了些什么玩意”的想法看完了我的文章,还请不吝赐教,指出我的错误。
作为开始总结的第一篇论文,我选取的论文并不新,是一篇发表在2014年ACL(Meeting of the Association for Computational Linguistics)的短文。作者是Omer Levy和 Yoav Goldberg,Bar-llan University(以色列的巴伊兰大学)。
下面开始步入正文。
文章在Abstract部分就交代了,他们的工作就是generalize(泛化)了Mikolov提出的skip-gram model + negative sampling。skip-gram模型利用的context(上下文)就是其前面几个词和后面几个词,而本文利用的context却可以是任意的。虽然文章提的是任意的上下文,但是其实文章主要说的还是基于依存的context。
introduction正常我应该只看最后一段的,但是今天兴致不错,于是都看了。但是还是有挺多工作没看懂。文章最开始以例子“pizza”和“hamburger”说明了词表示(word representation)的重要性,引出了对于获得词表示的一种常用的模式-distributional hypothesis(分布式假设),这个假设是words in similar contexts have similar meanings(有相似的上下文的词拥有相似的意思)。之后大家就一句这个假设提出了挺多方法,于是也出现了我们熟悉的用神经网络语言模型训练的方法,并且这种方法还展现了很好的性能。其中当然不能不提的就是Mikolov在2013年提出的word2vec,并且作者的改进主要建立在其中的skip-gram模型中。刚刚也提到了,在本文之前的模型的context一般是线性的,即目标词的前几个词和后几个词,而本文是syntactic contexts(句法上下文)。文章提到不同的上下文能产生非常显著不同的词向量,出现不同的词相似。文章提到,在skip-gram中上下文的bag-of-words nature(应该是自然的没有改变的周围的词的意思)产生的是broad topical similarities(局部相似性),而基于依存的上下文产生了更加功能性的相似性(根据后面的实验描述,这个意思应该是说类似表达的词的词义更加相近,比如各种国家的表达应该是相近的)。
之后就进入到描述模型的阶段了。首先讲了skip-gram和negative-sampling(负采样),这和word2vec一样。里面解释了负采样为什么是那种形式,貌似我在word2vec的论文中没看到过这段。。负采样的意思大概就是使能一起出现的词对的概率尽可能大,随机采的负例和目标词一起出现的概率尽可能小。
终于到了文章的关键部分了。在解析完(使用的解析工具由Goldberg and Nivre, 2012和2013提出的解析技术)句子之后,能得到的内容如下:对于每一个目标词(w)与其modifiers (m_1), (m_2),...,(m_k),和head (h),我们考虑的上下文为((m_1, lbl_1)), ..., ((m_k, lbl_k)), ((h, lbl_h^{-1}))。参见具体的例子即可明白作者的意思,如图所示:
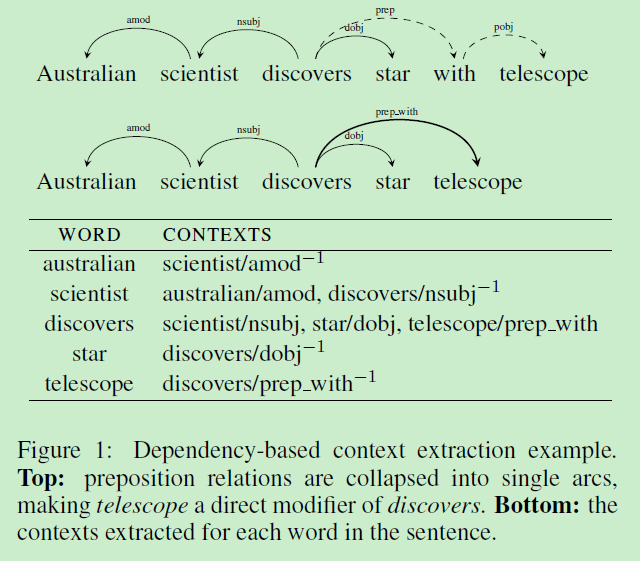
其中要注意的一点是,在介词那里,介词被省略,弧线直接连到了介词所连的词,并且关系变为了{prep,介词本身}。
最后就是实验部分了,实验主要设置了BoW5,BoW2和DEPS(即本文提出的模型)三个的比较。比较主要分为定性和定量。
- 在定性比较中,主要是人工的观察5个最相似的词(通过cosine similarity相似)。得出的结论是,BoW反映的是domain(领域方面),而DEPS反映的是目标词的semantic type(语义类型)。
- 在定量方面,文章在WordSim353 dataset和Chiarello et al. dataset上做了实验,结果都比另外两个对比实验好。但是在另外的任务,比如目标是在相似的集合上排序相关的术语时,结果反转了(这个实验在论文中没有被展示)。
最后的结论什么的没有仔细看。这篇文章发布了源码,在作者的个人主页上,GitHub上也可以搜到,名字是word2vecf。
最后的最后,如果大家有兴趣当然自己看看论文和源码研究一下了,也欢迎和我交流讨论。