论文提出的GID框架能够自动选择可辨别目标用于知识蒸馏,而且综合了feature-based、relation-based和response-based知识,全方位蒸馏,适用于不同的检测框架中。从实验结果来看,效果十分不错,值得一看
来源:晓飞的算法工程笔记 公众号
论文: General Instance Distillation for Object Detection

Introduction
在目标检测应用场景中,模型的轻量化和准确率是同样重要的,往往需要在速度和准确率之间权衡。知识蒸馏(Knowledge Distillation)是解决上述问题的一个有效方法,将大模型学习到的特征提取规则(知识)转移到小模型中,提升小模型的准确率,再将小模型用于实际场景中,达到模型压缩的目的。
目前的知识蒸馏方法大都针对分类任务,目标检测由于正负样本极度不平衡,直接将现有的方法应用到检测中一般都收益甚微。而目前提出的针对目标检测任务的知识蒸馏方法大都对知识进行了特定的约束,比如控制蒸馏的正负样本比例或只蒸馏GT相关的区域。此外,这些方法大都不能同时应用于多种目标检测框架中。为此,论文希望找到通用的知识蒸馏方法,不仅能应用于各种检测框架,还能转移尽可能多的知识,同时不用关心正负样本。
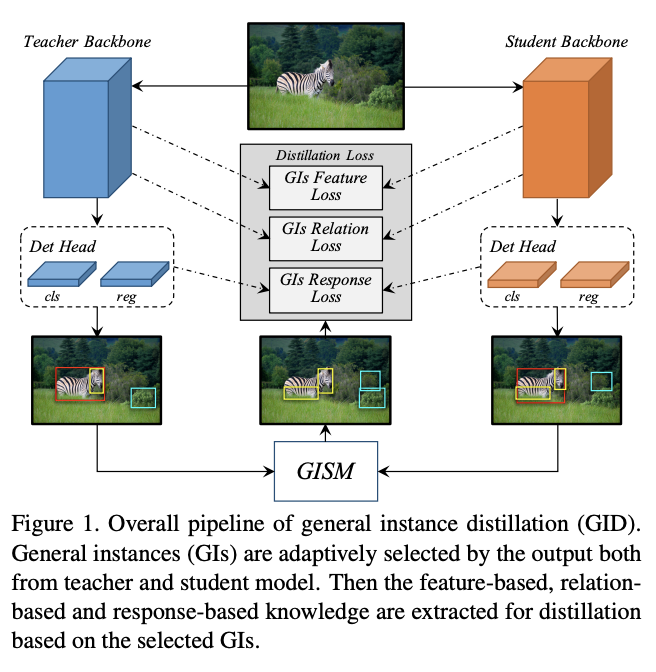
为了达到上述目的,论文结合response-based知识、feature-based知识和relation-based知识,提出了基于可辨别目标的蒸馏方法GID(general instances Distillation),主要优点有以下:
- 可以对单图中的多个实例间的关系进行建模并用于蒸馏中。尽管已经有研究表明实例间的关系信息在检测中的重要性,但还没有研究将其应用的知识蒸馏中。
- 避免手动设置正负样本比例或只选择GT相关区域进行蒸馏。虽然GT相关区域包含最多信息,但背景也可能包含对student的泛化能力学习有帮助的信息。论文通过实验发现自动选择的可辨别实例(discriminative instance)对迁移学习有明显的提升作用,这些显著实例也称为通用实例(General Instance, GIs),因为不需要关心其正负。
- 对不同检测框架通用,GIs是根据student和teacher的输出进行选择的,与网络的内部结构无关。
总结起来,论文的主要贡献如下:
- 定义通用实例(GIs)作为蒸馏目标,能够高效地提升检测模型的蒸馏效果。
- 基于GI,首次将relation-based知识引入到知识蒸馏中,并与response-based知识和feature-based知识合作,使得student能超越teacher。
- 在MSCOCO和PASCAL VOC数据集上验证不同检测框架下的有效性,均达到SOTA。
General Instance Distillation
有研究提出GT附近的特征区域包含有助于知识蒸馏训练的丰富信息,而论文发现不仅GT附近的区域,即使属于背景的区域,只要是可辨别区域(discriminative patch)都对知识蒸馏有帮助。基于上面的发现,论文设计了通用实例选择模块(general instance selection module, GISM),用于从teacher和student的输出中选择关键实例进行蒸馏。其次,为了更好地利用teacher的信息,论文综合使用了feature-based、relation-based和response-based知识用于蒸馏。
General Instance Selection Module
在检测模型中,预测结果能够指出信息最丰富的区域,而teacher和student的丰富区域的差异恰恰就是性能的差异。为了量化每个结果的差异,选择可辨别实例用于蒸馏,论文提出了两个指标:GI score和GI box,在每次迭代中动态计算。为了减少计算消耗,通过计算分类分数的L1 score作为GI score,而GI box则直接选择分类分数更高的box。
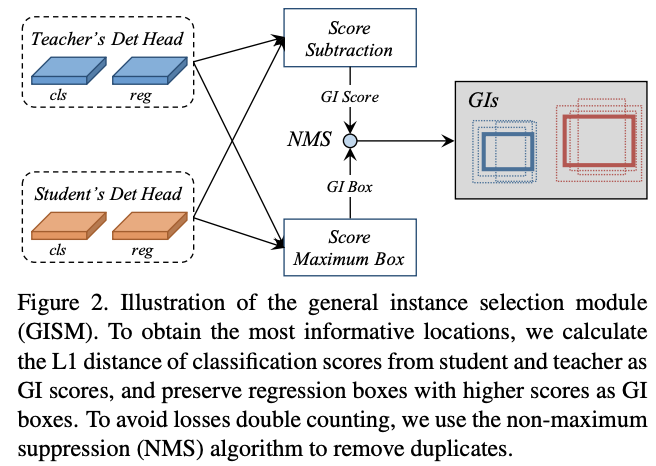
整个GI的选择过程如图2所示,对于实例\(r\),其score和box的选择定义为:
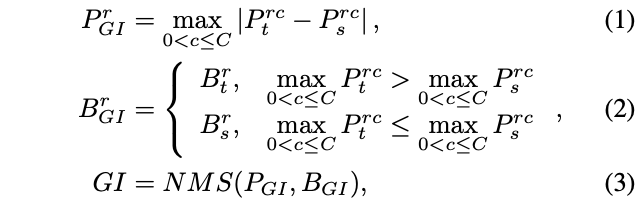
\(P_{GI}\)和\(B_{GI}\)分别为GI score和GI box。对于one-stage检测器,\(P_t\)和\(P_s\)为teacher和student的分类分数,而对于two-stage检测器则为RPN的objectness分数,\(B_t\)和\(B_s\)同理。\(R\)为预测框数目,\(C\)为类别数。由于论文将teacher和student的detection head设置成完全一样的,所以预测框也是可以根据位置一一对应的。
需要注意的是,高GI score的实例可能重合度比较高,导致蒸馏损失翻倍。为解决这一问题,使用NMS来去重,递归选择重复实例中GI score最高的实例。在实际使用中,NMS的IoU为0.3,最终每张图片只选择top-K个实例。
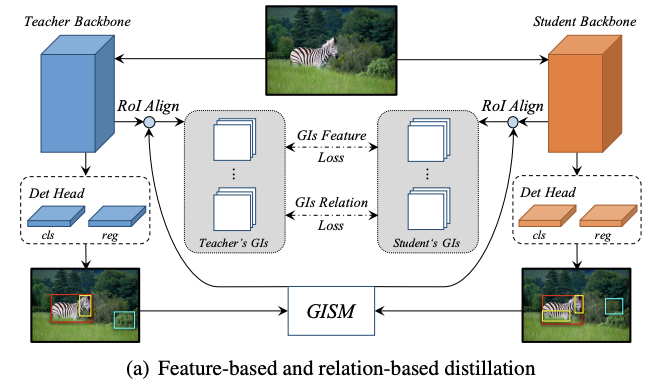
Feature-based Distillation
FPN结合了主干网络的不同层特征,能够显著提升检测模型对多尺度目标的鲁棒性。于是,论文打算将FPN加入到蒸馏中,根据GI box的尺寸选择对应的FPN层特征。
由于每个FPN层的目标特征大小不同,直接进行pixel-wise蒸馏会导致模型更倾向于大目标。于是论文转而采用ROIAlign将不同大小的特征输出为相同大小再进行蒸馏,如图a所示。feature-based蒸馏损失计算如下:
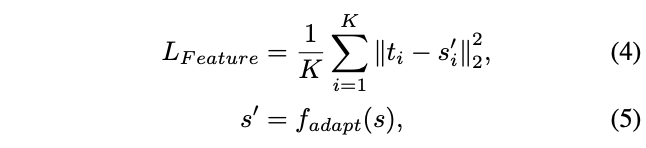
\(K\)为GISM选择的GI数目,\(t_i\)和\(s_i\)为ROIAlign处理后的FPN特征,\(f_{adapt}\)用于将\(s_i\)缩放到\(t_i\)的相同大小。
Relation-based Distillation
物体间的关系信息是分类任务进行蒸馏的关键,但还没在检测任务蒸馏中进行尝试。同一场景中的物体,不管是前景还是背景,都是高度相关的,这对student网络的收敛有很大帮助。
为了挖掘GIs中的关系知识,使用欧式距离来度量实例间的距离,然后用L1距离来传递知识。如图a所示。relation蒸馏损失计算如下:
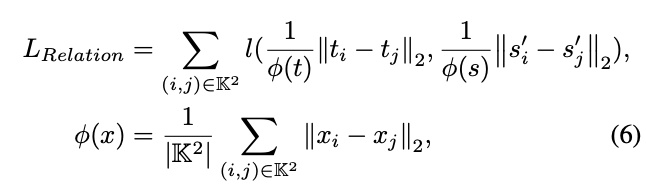
\(\mathbb{K}^2=\{(i,j)|i\ne j, 1\le i,j\le K\}\),\(\phi\)为归一化因子,\(l\)为smooth L1损失。
Response-based Distillation
知识蒸馏的关键主要是来自teacher的response-based知识的约束,这里的response-based知识指的是模型的最终输出。但因为检测输出往往存在正负样本不平衡或过多负样本的情况,如果直接将detection head的所有输出进行蒸馏,这种情况带来的噪声反而会损害student的性能。
有研究提出只蒸馏detection head的正样本,但这种方法忽略了可辨别的负样本的作用。为此,论文设计了distillation mask,将分类分支和回归分支的输出与GIs挂钩,比只选择正样本要高效。
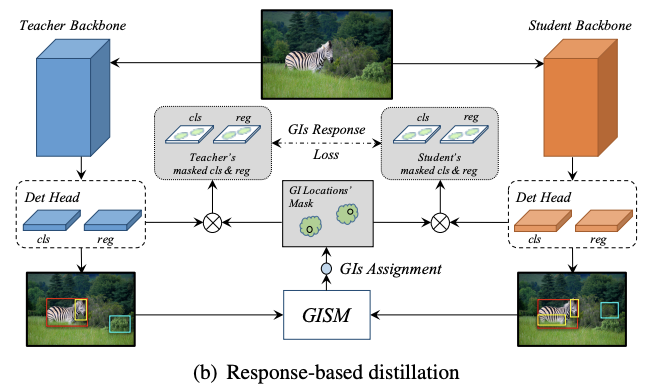
不同检测模型的输出是不同的,论文定义了一个通用的方法来进行detection head的蒸馏,如图b所示。首先,基于GIs的distillation mask计算为:
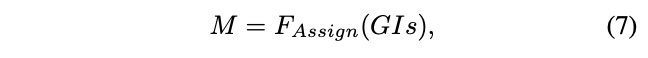
函数\(F\)是标签指定算法,输入为GI box,当匹配时,输出1,否则输出0。函数\(F\)对不同的模型的定义是不同的,对于RetinaNet,使用anchor和GIs间的IoU决定是否匹配,而对于FCOS则所有中心点在GIs外的输出都是0。
然后,response-based损失计算如下:
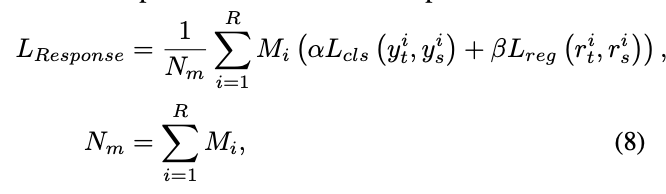
\(R\)为所有与选择的GIs匹配的输出,teacher和student对应的输出其中一个匹配即可。\(y_t\)和\(y_s\)为分类分支输出,\(r_t\)和\(r_s\)为回归分支输出,\(L_{cls}\)和\(L_{reg}\)为分类损失函数和回归损失函数。需要注意的是,为了简便,对于two-stage检测器只蒸馏RPN输出。
Overall loss function
模型的训练是端到端的,student的整体损失函数为:
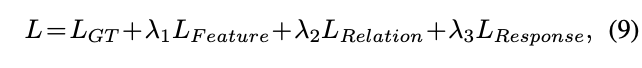
\(L_{GT}\)为模型原本的损失函数,\(\lambda\)为调节超参数。
Experiment
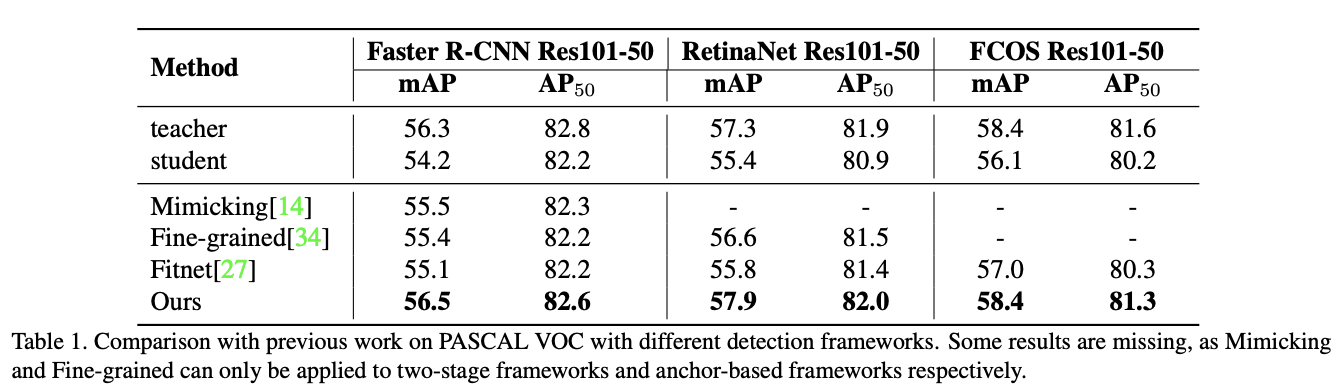
在VOC上对比蒸馏效果。
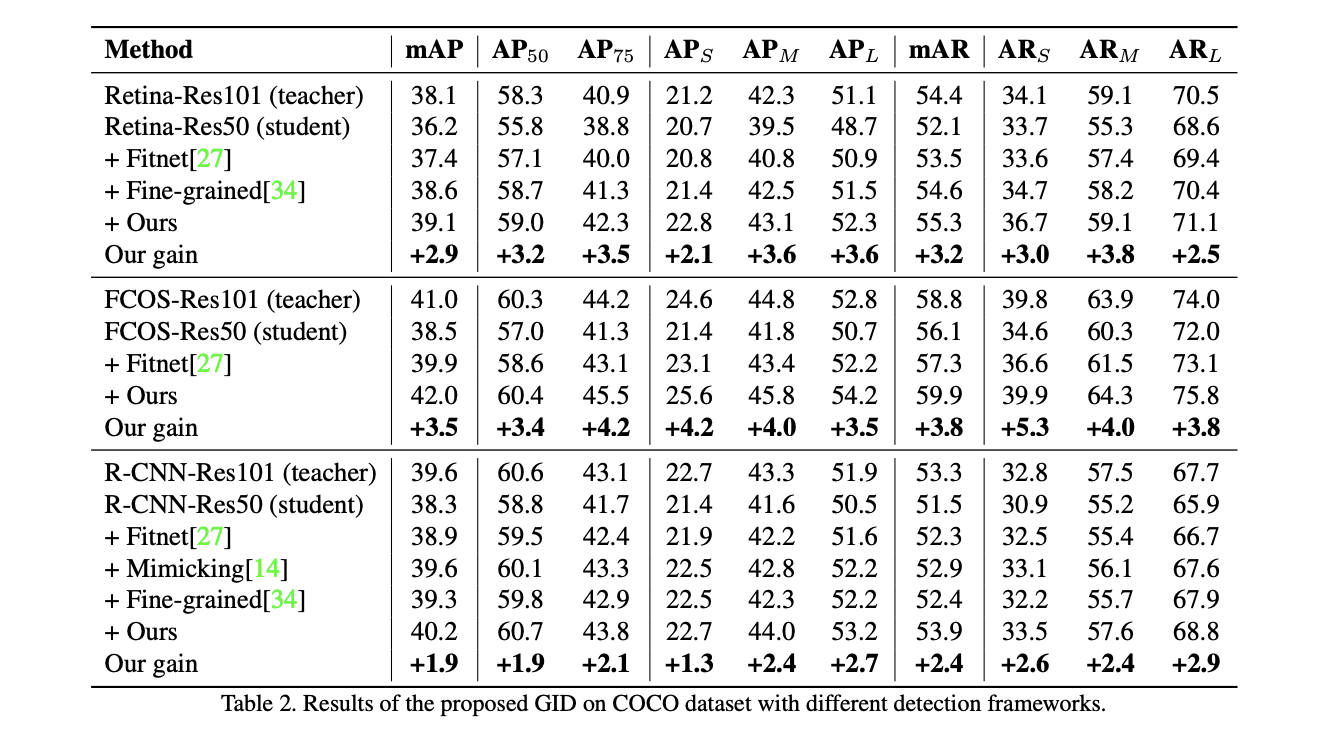
在COCO上对比蒸馏效果。
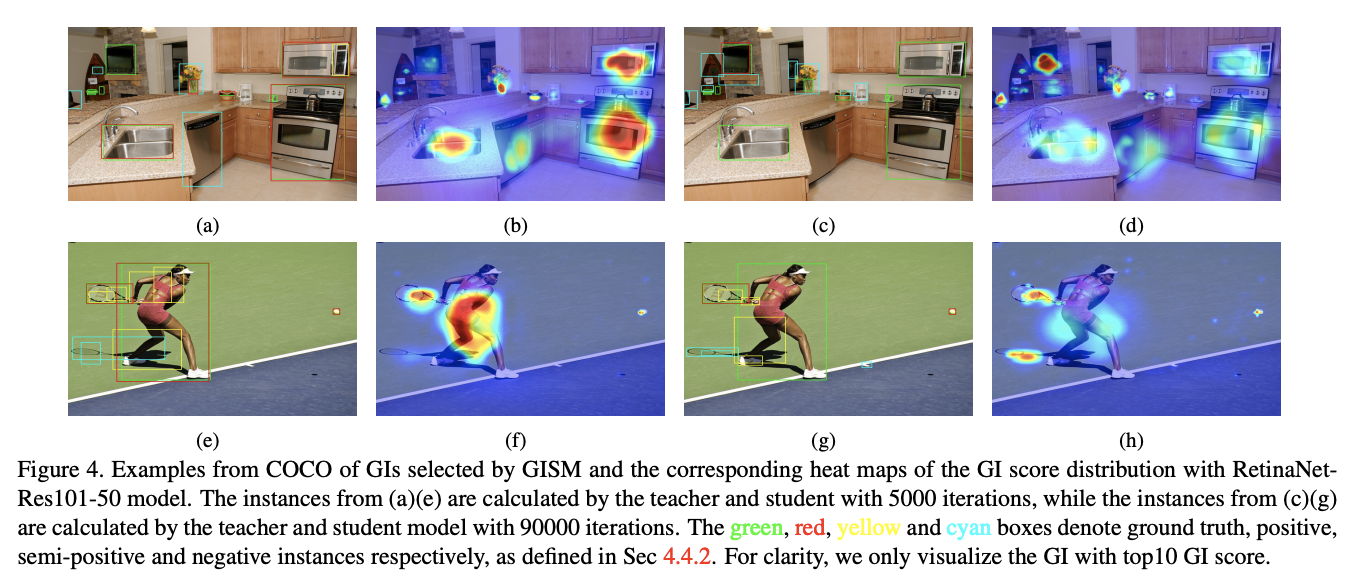
选择的GI box可视化,前面为5000迭的选择,后面为90000迭的选择。绿色代表GT,红色为正样本,黄色为中间(非正非负)样本,青色为负样本。
Conclusion
论文提出的GID框架能够自动选择可辨别目标用于知识蒸馏,而且综合了feature-based、relation-based和response-based知识,全方位蒸馏,适用于不同的检测框架中。从实验结果来看,效果十分不错,值得一看。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
