kafka与Rocketmq的区别
淘宝内部的交易系统使用了淘宝自主研发的Notify消息中间件,使用Mysql作为消息存储媒介,可完全水平扩容,为了进一步降低成本,我们认为存储部分可以进一步优化。
2011年初,Linkin开源了Kafka这个优秀的消息中间件,淘宝中间件团队在对Kafka做过充分Review之后,Kafka无限消息堆积,高效的持久化速度吸引了我们,
但是同时发现这个消息系统主要定位于日志传输,对于使用在淘宝交易、订单、充值等场景下还有诸多特性不满足,
为此我们重新用Java语言编写了RocketMQ,定位于非日志的可靠消息传输(日志场景也OK),目前RocketMQ在阿里集团被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,binglog分发等场景。
数据可靠性
- RocketMQ支持异步实时刷盘,同步刷盘,同步Replication,异步Replication
- Kafka使用异步刷盘方式,异步Replication
总结:RocketMQ的同步刷盘在单机可靠性上比Kafka更高,不会因为操作系统Crash,导致数据丢失。
同时同步Replication也比Kafka异步Replication更可靠,数据完全无单点。
另外Kafka的Replication以topic为单位,支持主机宕机,备机自动切换,但是这里有个问题,由于是异步Replication,那么切换后会有数据丢失,同时Leader如果重启后,会与已经存在的Leader产生数据冲突。开源版本的RocketMQ不支持Master宕机,Slave自动切换为Master,阿里云版本的RocketMQ支持自动切换特性。
性能对比
- Kafka单机写入TPS约在百万条/秒,消息大小10个字节
- RocketMQ单机写入TPS单实例约7万条/秒,单机部署3个Broker,可以跑到最高12万条/秒,消息大小10个字节
总结:Kafka的TPS跑到单机百万,主要是由于Producer端将多个小消息合并,批量发向Broker。
RocketMQ为什么没有这么做?
- Producer通常使用Java语言,缓存过多消息,GC是个很严重的问题
- Producer调用发送消息接口,消息未发送到Broker,向业务返回成功,此时Producer宕机,会导致消息丢失,业务出错
- Producer通常为分布式系统,且每台机器都是多线程发送,我们认为线上的系统单个Producer每秒产生的数据量有限,不可能上万。
- 缓存的功能完全可以由上层业务完成。
单机支持的队列数
- Kafka单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,load越高,发送消息响应时间变长
- RocketMQ单机支持最高5万个队列,Load不会发生明显变化
队列多有什么好处?
- 单机可以创建更多Topic,因为每个Topic都是由一批队列组成
- Consumer的集群规模和队列数成正比,队列越多,Consumer集群可以越大
消息投递实时性
- Kafka使用短轮询方式,实时性取决于轮询间隔时间
- RocketMQ使用长轮询,同Push方式实时性一致,消息的投递延时通常在几个毫秒。
消费失败重试
- Kafka消费失败不支持重试
- RocketMQ消费失败支持定时重试,每次重试间隔时间顺延
总结:例如充值类应用,当前时刻调用运营商网关,充值失败,可能是对方压力过多,稍后在调用就会成功,如支付宝到银行扣款也是类似需求。
这里的重试需要可靠的重试,即失败重试的消息不因为Consumer宕机导致丢失。
严格的消息顺序
- Kafka支持消息顺序,但是一台Broker宕机后,就会产生消息乱序
- RocketMQ支持严格的消息顺序,在顺序消息场景下,一台Broker宕机后,发送消息会失败,但是不会乱序
Mysql Binlog分发需要严格的消息顺序
定时消息
- Kafka不支持定时消息
- RocketMQ支持两类定时消息
- 开源版本RocketMQ仅支持定时Level
- 阿里云ONS支持定时Level,以及指定的毫秒级别的延时时间
分布式事务消息
- Kafka不支持分布式事务消息
- 阿里云ONS支持分布式定时消息,未来开源版本的RocketMQ也有计划支持分布式事务消息
消息查询
- Kafka不支持消息查询
- RocketMQ支持根据Message Id查询消息,也支持根据消息内容查询消息(发送消息时指定一个Message Key,任意字符串,例如指定为订单Id)
总结:消息查询对于定位消息丢失问题非常有帮助,例如某个订单处理失败,是消息没收到还是收到处理出错了。
消息回溯
- Kafka理论上可以按照Offset来回溯消息
- RocketMQ支持按照时间来回溯消息,精度毫秒,例如从一天之前的某时某分某秒开始重新消费消息
总结:典型业务场景如consumer做订单分析,但是由于程序逻辑或者依赖的系统发生故障等原因,导致今天消费的消息全部无效,需要重新从昨天零点开始消费,那么以时间为起点的消息重放功能对于业务非常有帮助。
消费并行度
-
Kafka的消费并行度依赖Topic配置的分区数,如分区数为10,那么最多10台机器来并行消费(每台机器只能开启一个线程),或者一台机器消费(10个线程并行消费)。即消费并行度和分区数一致。
-
RocketMQ消费并行度分两种情况
消息轨迹
- Kafka不支持消息轨迹
- 阿里云ONS支持消息轨迹
开发语言友好性
- Kafka采用Scala编写
- RocketMQ采用Java语言编写
Broker端消息过滤
- Kafka不支持Broker端的消息过滤
- RocketMQ支持两种Broker端消息过滤方式
- 根据Message Tag来过滤,相当于子topic概念
- 向服务器上传一段Java代码,可以对消息做任意形式的过滤,甚至可以做Message Body的过滤拆分。
消息堆积能力
理论上Kafka要比RocketMQ的堆积能力更强,不过RocketMQ单机也可以支持亿级的消息堆积能力,我们认为这个堆积能力已经完全可以满足业务需求。
成熟度
- Kafka在日志领域比较成熟
- RocketMQ在阿里集团内部有大量的应用在使用,每天都产生海量的消息,并且顺利支持了多次天猫双十一海量消息考验,是数据削峰填谷的利器。
技术选型:RocketMQ or Kafka
当业务需要系统间调用解耦时,MQ 是一个很好的方案,目前选择最多的当属Kafka和阿里的RocketMQ, 两种中间件都可以使用,都是备选方案,摆在面前,怎么选择?
- 方法论-评估和选择备选方案的方法
按优先级选择,即架构师综合当前的业务发展情况、团队人员规模和技能、业务发展预测等因素,将质量属性按照优先级排序,首先挑选满足第一优先级的,如果方案都满足,那就再看第二优先级……以此类推。
- RocketMQ 和 Kafka 到底有什么区别?
(1) 适用场景
Kafka适合日志处理;
RocketMQ适合业务处理。
结论:平手,根据具体业务定夺。
(2) 性能
Kafka单机写入 TPS 号称在百万条/秒;
RocketMQ 大约在10万条/秒。
结论:追求性能的话,Kafka单机性能更高。
(3) 可靠性
RocketMQ支持异步/同步刷盘;异步/同步Replication;
Kafka使用异步刷盘方式,异步Replication。
结论:RocketMQ所支持的同步方式提升了数据的可靠性。
(4) 实时性
均支持pull长轮询,RocketMQ消息实时性更好
结论:RocketMQ 胜出。
(5) 支持的队列数
Kafka单机超过64个队列/分区,消息发送性能降低严重;
RocketMQ 单机支持最高5万个队列,性能稳定
结论:长远来看,RocketMQ 胜出,这也是适合业务处理的原因之一
(6) 消息顺序性
Kafka 某些配置下,支持消息顺序,但是一台Broker宕机后,就会产生消息乱序;
RocketMQ支持严格的消息顺序,在顺序消息场景下,一台Broker宕机后,
发送消息会失败,但是不会乱序;
结论:RocketMQ 胜出
(7)消费失败重试机制
Kafka消费失败不支持重试
RocketMQ消费失败支持定时重试,每次重试间隔时间顺延。
(8)定时/延时消息
Kafka不支持定时消息;
RocketMQ支持定时消息
(9)分布式事务消息
Kafka不支持分布式事务消息;
阿里云ONS支持分布式定时消息,未来开源版本的RocketMQ也有计划支持分布式事务消息
(10)消息查询机制
Kafka不支持消息查询
RocketMQ支持根据Message Id查询消息,也支持根据消息内容查询消息
(11)消息回溯
Kafka理论上可以按照Offset来回溯消息
RocketMQ支持按照时间来回溯消息,精度毫秒,例如从一天之前的某时某分某秒开始重新消费消息
- 为什么阿里会自研RocketMQ?
(1)Kafka的业务应用场景主要定位于日志传输;对于复杂业务支持不够
(2)阿里很多业务场景对数据可靠性、数据实时性、消息队列的个数等方面的要求很高。
kafka针对海量数据,但是对数据的正确度要求不是十分严格。而阿里巴巴中用于交易相关的事情较多,对数据的正确性要求极高,Kafka不合适
(3)当业务成长到一定规模,采用开源方案的技术成本会变高.
开源方案无法满足业务的需要;旧版本、自开发代码与新版本的兼容都可能是问题;运维角度,Kafka使用 scala 编写,而阿里是java系。Kafka 的后续维护是个问题。
(4)阿里在团队、成本、资源投入等方面约束性条件几乎没有.
综上,阿里选择自己开发RocketMQ更多是业务的驱动,当业务更多的需要以下功能的支持时,kafka 不能满足或者 ActiveMQ 等其他消息中间件不能满足,财大气粗能力又强业务还复杂,所以就自己开发了。
- 其他
另外认为kafka是用于日志传输,所以不适合系统的业务事件是个更大的误区,Kafka本身在最早实现时的确是为了传输日志,但后来经过多年发展,其适用范围早不限于日志,并且很多采取Kafka的公司并非用它来处理日志,kafka背后的 Confluence公司提供了很多基于kafka来简化系统实现的例子。
大家都在发展,功能的差异会很快抹平的。
RocketMQ 可以理解为是Java版 的kafka。
更多的性能对比可以参考阿里中间件团队的报告。
Kafka理论概述和应用场景
1.Kafka概述
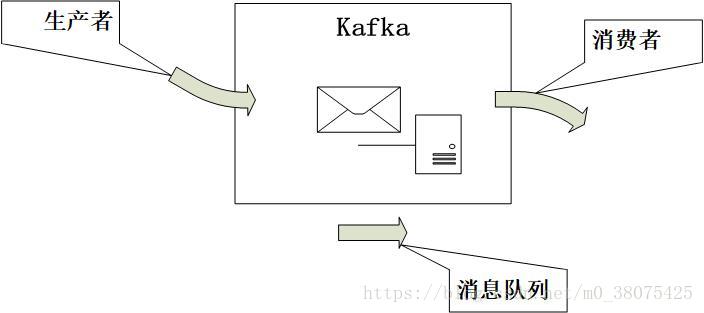
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。
简单地说,Kafka就相比是一个邮箱,生产者是发送邮件的人,消费者是接收邮件的人,Kafka就是用来存东西的,只不过它提供了一些处理邮件的机制。
2.Kafka相关名词分析
- Broker:Kafka节点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群
- Topic:一类消息,消息存放的目录即主题,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发
- massage: Kafka中最基本的传递对象。
- Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列
- Segment:partition物理上由多个segment组成,每个Segment存着message信息
- Producer : 生产者,生产message发送到topic
- Consumer : 消费者,订阅topic并消费message, consumer作为一个线程来消费
- Consumer Group:消费者组,一个Consumer Group包含多个consumer
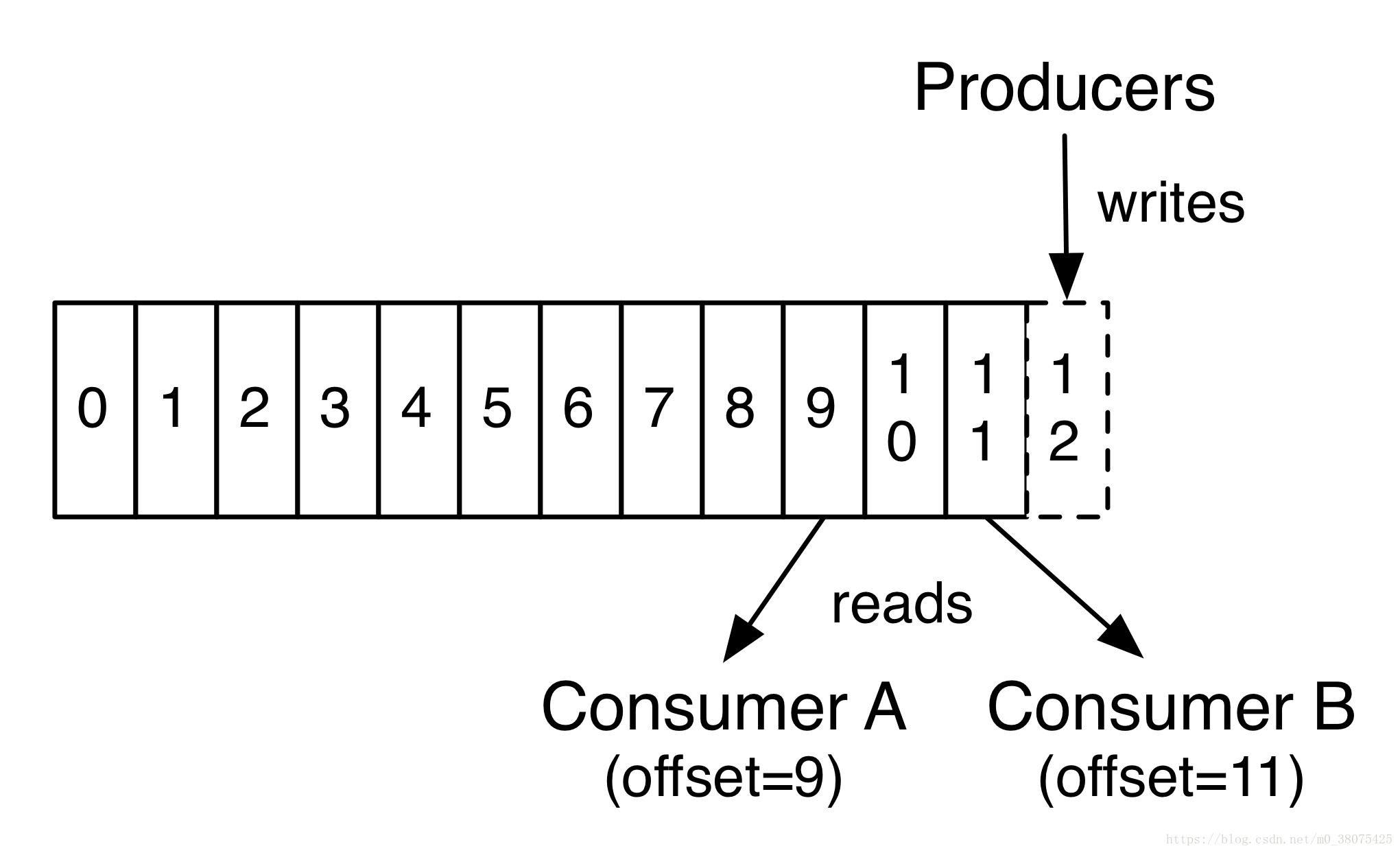
- Offset:偏移量,理解为消息partition中的索引即可
下面做进一步说明:
broker即kafka程序,kafka程序运行于zookeeper之上,zookeeper是一个分布式的,分布式应用程序的协调服务,其提供的功能包括:配置维护、域名服务、分布式同步、组服务等。在此处,zookeeper协调kafka节点的配置、同步操作等。
topic即主题,kafka中发布消息、订阅消息的对象是topic。我们可以为每类数据创建一个topic。一个topic中的消息数据按照多个partition组织,分区是kafka消息队列组织的最小单位(并不是物理上的最小单位),一个分区可以看作是一个FIFO( First Input First Output的缩写,先进先出队列)的队列。如下图:
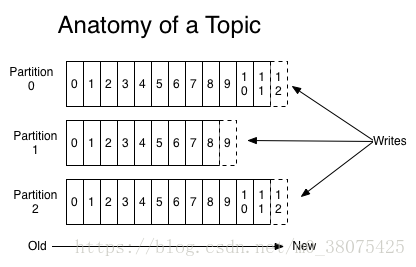
例如,在上图中,一个topic被分成了3个分区(即partition0~2),用户发布message时,可以指定message所处topic的partition,如果没有指定,则随机分布到该topic的partition。发布的消息(其实是逻辑日志)将在partition尾部插入。
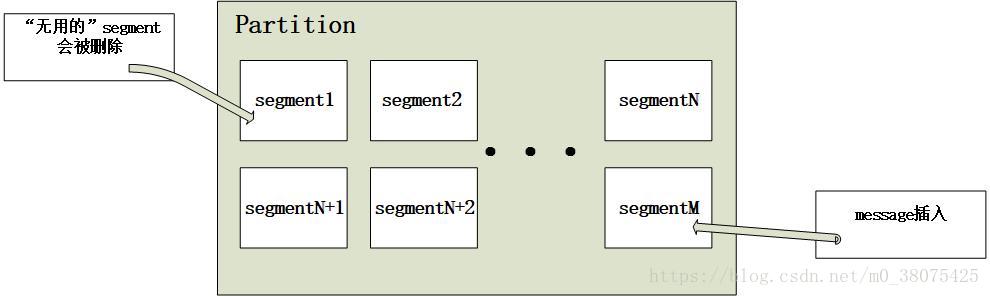
segment是partition的物理存储单元,kafka收到message后,会向对应partition的最后一个segment上添加该消息,当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被保存到磁盘,只有被保存到磁盘上的消息consumer才能消费,segment达到一定的大小后将不会再往该segment写数据,kafka会创建新的segment。其实,每个partition相当于分配到多个大小相等segment数据文件中。但每个segment消息数量不一定相等,这种特性方便无用的segment快速被删除,segment文件生命周期由服务端配置参数决定。如下图:
consumer和consumer group,一个consumer group包含多个consumer,用户可以指定consumer的group。各个consumer可以组成一个group,partition中的每个message只能被一个group中的一个consumer消费,如果一个message想要被多个consumer消费的话,那么这些consumer必须在不同的group。kafka不支持一个partition中的message同时由两个或两个以上的consumer thread来处理,即便是来自不同的consumer group的也不行。kafka为了保证吞吐量,只允许一个consumer去访问一个partition。如果觉得效率不高,可以加partition的数量来横向扩展,再加新的consumer去消费,充分发挥了横向的扩展性,吞吐量极高。这也就形成了分布式消费的概念。如下图:
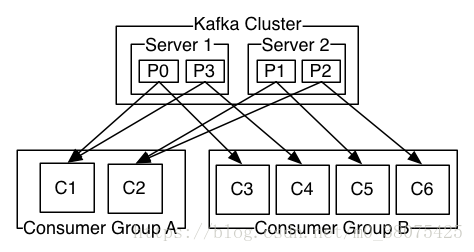
上图中有两个服务器的kafka群集,它们有四个分区(P0-P3),其中有两个group。group A有两个消费者,group B有四个消费者。P0如果被C1消费后,则C2不能再消费,但是group B的C3或者其它的一个可以消费P0。
3.Kafka的优势
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点故障(若副本数量为n,则允许n-1个节点故障)
- 高并发:支持数千个客户端同时读写
4.Kafka应用场景
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer
- 消息系统:解耦生产者和消费者、缓存消息等
- 用户活动跟踪:kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后消费者通过订阅这些topic来做实时的监控分析,亦可保存到数据库
- 运营指标:kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告
- 流式处理:比如spark streaming和storm;
RocketMQ —— 优点及基础理论
更深入的了解RocketMQ一些优点,以及队列的基础知识。
设计优点
| 优点 | 描述 |
|---|---|
| 支持分布式 | 原生支持分布式,ActiveMQ原生存在单点 |
| 严格的消息顺序 | 保证严格的消息顺序,ActiveMQ无法保证 |
| 海量消息低延迟 | RocketMQ支持亿级消息堆积能力,并可以保证亿级消息写入时达到低延迟 |
| 消息拉取模式 | 1. PUSH:消费者端设置Listener2. PULL:应用可主动从Broker获取消息,主动拉取会存在消费记录位置问题(如果不记录位置,会出现重复消费) |
| 分布式协调 | Metaq1.x/2.x版本,分布式协调采用Zookeeper,RocketMQ通过自己实现NameServer达到分布式协调,更轻量,由于自主实现,更贴近框架,性能更好 |
| 其它 | 消费重试机制、高效订阅者水平扩展功能、API(多语言)、分布式事务机制等! |
[Producer / Consumer] GROUP
RocketMQ中有一个“组”机制,此机制很重要,如下图: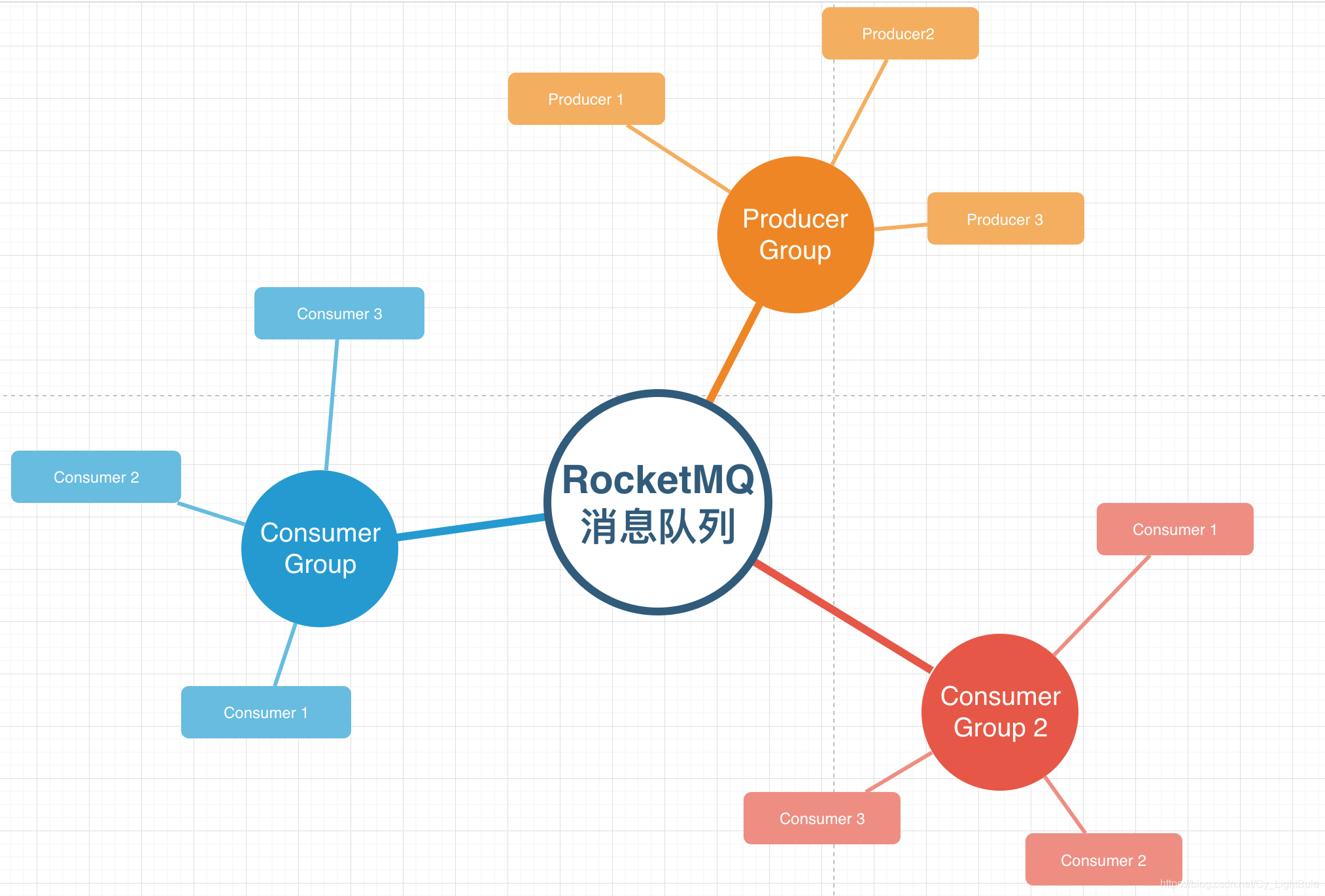
通过组机制(Group),RocketMQ可以天然支持分布式。如下所示: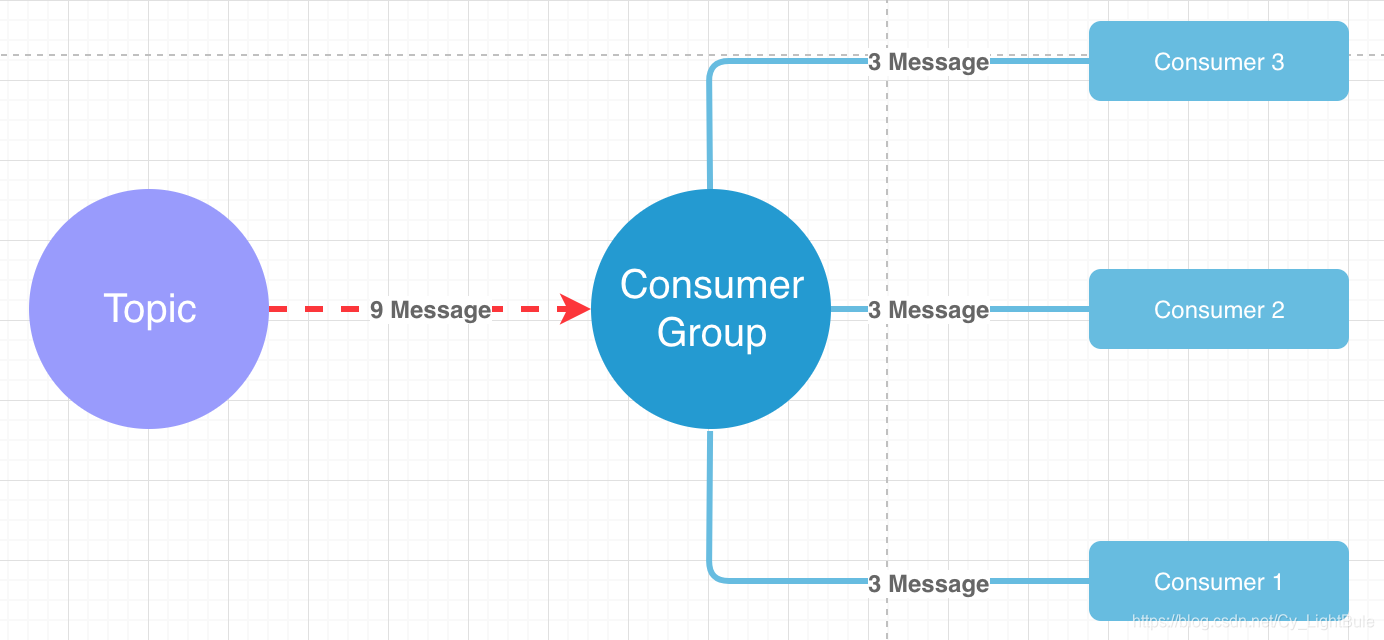
如上图所示,某个Topic有9条消息,Consumer Group有三个实例(3个进程或3台机器),9条消息就会均摊到每个实例上(3条/个)!
【RocketMQ只有一个模式 ———— 发布订阅模式!】
RocketMQ 集群部署模式
| 描述 | |
|---|---|
| 单Master模式 | 单点,Broker重启或宕机,队列就失效了,生产一定要避免单点,所以不考虑 |
| 多Master模式 | 由于是复数Master,当某台Broker宕机,新到消息是不会受影响,但由于没有Slave,会出现只有将宕机Master重启之后,才可以消费掉宕机Master上的消息,如果生产消息队列较少,并且对时间要求不严苛,可以考虑。 |
多Master多Slave(异步复制) |
高可用模式! 采用异步复制方式,主备之间短暂延迟。Master宕机可以在Slave消费,但是Master宕机,会导致少量消息丢失。常用投产解决方案之一 |
多Master多Slave(同步双写) |
和异步复制方式的区别在于,采用的是同步方式。在Master/Slave都写成功后向应用返回成功,无论是数据还是服务都不存在单点,可靠性强!不过同步性能比异步较低! |
参考:https://www.cnblogs.com/xuwc/p/14018568.html