如何在细粒度的架构中更好的微服务。这里会从持续集成和持续交付说起。
1.持续集成简介
CI(Continuous Integration , 持续集成)
CI能够保证新提交的代码与已有的代码进行集成,从而保证所有人保持同步。CI服务器会检测到
代码已提交并签出,然后花些时间来验证代码是否通过编译以及测试能否通过。
作为这个流程的一部分,我们经常会生成一些构建物(artifact)以供后续验证使用。
理想情况下,这些构建物应该只生成一次,然后在本次提交所对应的所有部署环节中使用。
CI的好处很多。通过它,我们能够得到关于代码质量的某种程度的快速反馈。
CI可以自动化生成二进制文件。用于生成这些构建物的所有代码都在版本的控制之下,
所以如果需要的话,可以重新生成这个版本的构建物。通过CI我们能够从已部署的构建物回溯到
相应的代码,有些CI工具,还可以使这些代码和构建物上运行过的测试可视化。
持续集成允许我们更快速,更容易的修改代码。
有人任务使用了CI工具就算采用了CI这个实践,事实上,只有工具是远远不够的。
测试别人是否真正理解CI的三个问题?
- 你是否每天签入代码到主线?
你应该保证代码能够与已有代码进行集成
- 你是否有一组测试来验证修改?
如果没有测试,我们只能知道集成后没有语法错误,但无法知道系统的行为是否已经被破坏。
没有对代码行为进行验证的CI不是真正的CI。
- 当构建失败后,团队是否把修复CI当做第一优先级的事情来做?
绿色的构建意味着,我们的修改已经安全地和已有代码集成在了一起。红色的构建意味着,最后一次修改很可能有问题,
这时只能提交修复构建的代码。
2.把持续集成映射到微服务
前面已经提到过,每个微服务应该能够独立于其他服务进行部署。
所以如何在微服务、CI构建及源代码三者之间,建立起合适的映射呢?
最简单的做法,如下
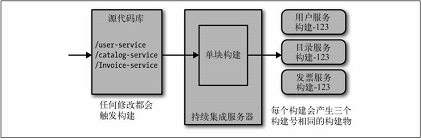
图 6-1 把所有微服务放在同一个代码库中,并且只有一个构建
这种方法从表面上看比其他方法要简单的多:因为你需要关心的代码库比较少,
而且从概念上来讲,这种构建也比较简单。开发者的工作也得到了简化:
我们只需要提交代码即可,如果需要同时在多个服务上工作的话,一个提交就能搞定。
在同步发布(lock - step release)中,你需要一次性部署多个服务。
一般来讲,我们绝对应该避免这个模式,但是在项目初期是个例外。
当仅有一个团队在所有的服务上工作时,这种模式在短时间内是可接受的。
这种模式存在很多明显的缺点。
如果我仅修改了图6-1中用户服务中的一行代码,所有其他服务都需要进行验证和构建,
而事实上它们或许并不需要重新进行验证和构建,所以这里我们花费了不必要的时间。
更糟糕的是,我不知道那些构建物应该被重新部署,哪些不应该。
使用这种方式的组织,往往都会退回到同时部署所有代码的模式,而这也正是我们非常不想看到的。
很不幸,如果这一行的修改导致构建失败,那么在构建得到修复之前,其他服务相关的代码也无法提交。
这种方法的一个变体是保留一个代码库,但是存在多个CI会分别映射到代码库的不同部分。
如图 6-2
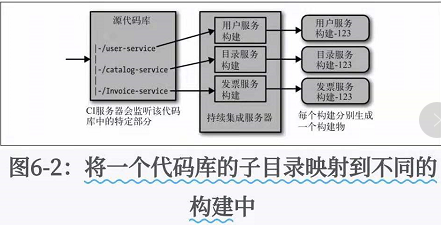
这种模式是个双刃剑。
一方面它会简化检出/检入的流程,但是另一方面,它会让你觉得同时提交对多个服务的修改
是一件简单的事情,从而做出将多个服务耦合在一起的修改。
但是相对于只有一个构建的多个服务来说,这个方式已经好很多了。
还有一种比较好的方式,每个微服务都有自己的CI,这样就可以将该微服务部署到生产环境之前做一个快速的验证。
如图6-3
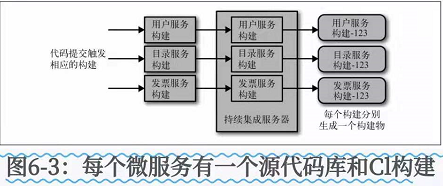
这里的每个微服务都有自己的代码库,分别于相应的CI绑定。
当对代码库进行修改时,可以只运行相关的构建以及其中的测试。
每个微服务都有自己的代码库和构建流程。
我们也会使用CI构建流程,全自动话的创建出用于部署的构建物。
3. 构建流水线和持续交付
把一个构建分成多个阶段是很有价值的。
因为有的测试运行快,涉及范围小,有的测试运行耗时,涉及范围广,
如果放一起,快速如果失败,还会接着运行耗时的测试,这样就不合理。
解决这个问题的一个方案是,将构建分解成为多个阶段,从而得到我们熟知的构建流水线。
在第一个阶段运行快速测试,在第二个阶段运行耗时测试。
构建流水线可以很好的跟踪软件构建进度:每完成一个阶段,就离终点更近一步。
流水线也能够可视化本次构建物的软件质量。构建物会在整个构建的第一个环节生成,
然后会被用在整个流水线中。
CD(Continuous Delivery, 持续交付)基于上述概念,并在此之上有所发展。
CD能够检查每次提交是否达到了部署生成环境的要求,并持续地把这些信息反馈给我们,
它会把每次提交当成候选发布版本来对待。
为了更好的理解这些概念,我们需要对从代码提交及部署到生产环境这个过程中,所需要经历的流程进行建模,
并知道哪些版本的软件时可发布的。
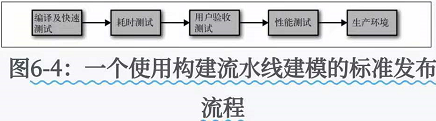
UAT(User Acceptance Testing, 用户验收测试)流程。
通过对整个软件上线过程进行建模,软件质量的可视化得到了极大改善,这可以大大减少发布之间的间隔,
因为可以在一个集中的地方看到构建和发布流程,这也是可以引入改进的一个焦点。
在微服务的世界,我们想要保证服务之间可以独立于彼此进行部署,所以每个服务都有自己独立的CI.
不可避免的例外
所有好的规则都需要考虑例外。
当一个团队刚开始启动一个新项目时,尤其是什么都没有的情况下,你可能会花很多时间来识别出服务的边界。
所以在你识别出稳定的领域之前,可以把初始服务都放在一起。
在最开始的阶段,经常会发生跨服务边界的修改,所以时常会有些内容移入或者移出某个服务。
在这个阶段,把所有的服务都放在一个单独的构建中,可以减轻跨服务修改所带来的代价。
当然,在这个阶段你必须把所有服务打包发布,但这应该是一个过渡步骤。
4.平台特定的构建物
大多数技术栈都有相应的构建物类型,同时也有相关的工具来创建和安装这些构建物。
Ruby中有gem,Java中有JAR包和WAR包,Python中有egg。
但是,从微服务部署的角度来看,在有些技术栈中只有构建物本身是不够的。
所以为了部署和启动这些构建物,需要安装和配置一些其他软件,再启动这些构建物。
自动化可以对不同构建物的底层部署机制进行屏蔽。
5.操作系统构建物
有一种方法可以避免多种技术栈下的构建物所带来的问题,那就是使用操作系统支持的构建物。
举个例子,对基于RedHat或者CentOS的系统来说,可以使用RPM;对于Ubuntu来说,可以使用deb包;
对于Windows来说,可以使用MSI。
使用OS特定构建物的好处是,在做部署时不需要考虑底层使用的是什么技术。只需要简单使用内置的工具就可以完成软件的安装。
OS包管理工具,可以帮你完成很多原本需要使用Chef或者Puppet来完成的工作。
其缺点是,刚开始编写构建脚本的过程可能会比较困难。
当然,还有另一个缺点,即如果你需要部署到多个操作系统的话,维护不同版本构建物的开销就会很大。
但如果软件时部署在你可控的机器上,那么建议,尽量减少需要维护的操作系统的数量,最好只维护一种。
它可以大大减少不同机器之间可能存在的不同之处,并减小部署和维护的工作量。
特别是如果你在linux上工作,而且采用多种技术栈来部署微服务,那么这种方法就很合适。
6.定制化镜像
使用类似Puppet、Chef及Ansible这些自动化配置管理工具的一个问题是,需要花费大量时间在机器上运行这些脚本。
什么是蓝绿部署?
蓝绿部署允许我们在老版本服务不下线的同时,去部署新版本的服务。可以减少在部署时,服务停止的时间增加。
一种减少启动时间的方法是创建一个虚拟机镜像,其中包含一些常用的依赖。
现在你可以把公共的工具安装在镜像上,然后在部署软件时,只需要根据该镜像创建一个实例,
之后在其上安装最新的服务版本即可。
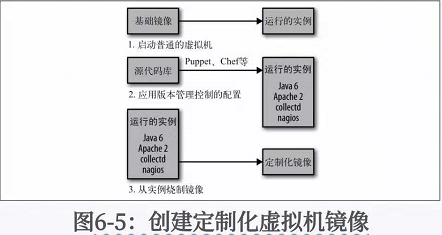
你只需要构建一次镜像,然后根据这些镜像启动虚拟机,不需要再花费时间来安装相应的依赖,
因为它们已经在镜像中安装好了,这样就可以节省很多时间。如果你的核心依赖没有改变,
那么新版本的服务就可以继续使用相同的基础镜像。
这个方法也有些缺点。
首先,构建镜像会花费大量的时间。
其次,产生的镜像可能会很大。例如,当你创建VMWare镜像时,在网络上传送一个20GB的镜像文件会怎么样。
由于历史原因,构建不同平台上的镜像所需的工具是不一样的。
6.1 将镜像作为构建物
我们可以把服务本身也包含在镜像中,这样就把镜像变成了构建物。
就像使用OS特定软件包那样,可以认为这些VM镜像时对不同技术栈的一层抽象。
我们不需要关心运行在镜像中的服务,所使用的语言是Ruby还是Java,最终构建物是gem还是JAR包,
我们唯一需要关心的就是它能否工作。
这个简洁的方法有助于我们实现另一个部署概念:不可变服务器。
6.2 不可变服务器
通过把配置都存到版本控制中,我们可以自动化重建服务,甚至重建整个环境。
但是如果部署完成后,有人登陆到机器上修改了一些东西呢?
这就会导致机器上的实际配置和源代码管理中的配置不再一致,这个问题叫做配置漂移。
为了避免这个问题,可以禁止对任何运行的服务器做手动修改。
相反,无论修改多么小,都需要经过构建流水线来创建新的机器。
7.环境