一、简介
Kafka是Apache旗下的一款分布式流媒体平台,Kafka是一种高吞吐量、持久性、分布式的发布订阅的消息队列系统。它最初由LinkedIn(领英)公司发布,使用Scala语言编写,与2010年12月份开源,成为Apache的顶级子项目。主要用于处理消费者规模网站中的所有动作流数据。动作指(网页浏览、搜索和其它用户行动所产生的数据)。
Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。无论是kafka集群,还是consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
二、其他消息系统对比
- RabbitMQ Erlang编写,支持多协议 AMQP,XMPP,SMTP,STOMP。支持负载均衡、数据持久化。同时 支持Peer-to-Peer和发布/订阅模式
- Redis 基于Key-Value对的NoSQL数据库,同时支持MQ功能,可做轻量级队列服务使用。就入队操作而言, Redis对短消息(小于10KB)的性能比RabbitMQ好,长消息的性能比RabbitMQ差。
- ZeroMQ 轻量级,不需要单独的消息服务器或中间件,应用程序本身扮演该角色,Peer-to-Peer。它实质上是 一个库,需要开发人员自己组合多种技术,使用复杂度高
- ActiveMQ JMS实现,Peer-to-Peer,支持持久化、XA事务
- Kafka/Jafka 高性能跨语言的分布式发布/订阅消息系统,数据持久化,全分布式,同时支持在线和离线处理。适合数据下游消费众多的情况;适合数据安全性要求较高的操作,支持replication。为什么适合数据下游消费众多?因为有就算有多个消费者,kafka里面存的数据是一样的,不会再增加副本。
- MetaQ/RocketMQ 纯Java实现,发布/订阅消息系统,支持本地事务和XA分布式事务
三、Kafka组件
1.Kafka的三大特点
- 1.高吞吐量:可以满足每秒百万级别消息的生产和消费。
- 2.持久性:有一套完善的消息存储机制,确保数据高效安全且持久化。
- 3.分布式:基于分布式的扩展;Kafka的数据都会复制到几台服务器上,当某台故障失效时,生产者和消费者转而使用其它的Kafka。
2.流媒体平台有三个关键功能:
- 1.发布和订阅记录流,类似于消息队列或企业消息传递系统。
- 2.以容错的持久方式存储记录流。
- 3.记录发生时处理数据流
3.Kafka通常用于两大类应用:
- 1.构建可在系统或应用程序之间可靠获取数据的实时流数据管道
- 2.构建转换或响应数据流的实时流应用程序
4.Kafka的几个概念
- 1.Kafka作为一个集群运行在一个或多个服务器上,这些服务器可以跨多个机房,所以说kafka是分布式的发布订阅消息队列系统。
- 2.Kafka集群将记录流存储在称为Topic的类别中。
- 3.每条记录由键值;"key value"和一个时间戳组成。
5.Kafka的四个核心API:
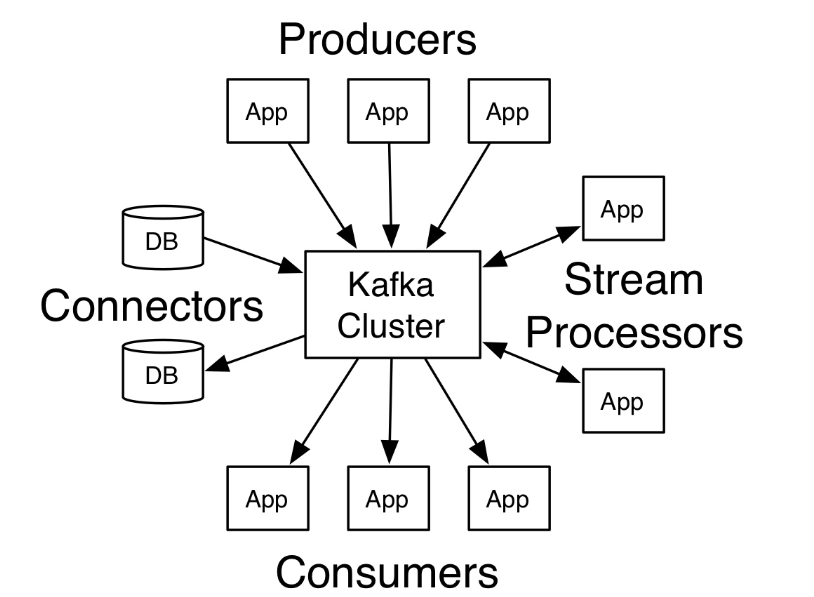
- 1. Producer API:生产者API允许应用程序将一组记录发布到一个或多个Kafka Topic中。
- 2. Consumer AIP:消费者API允许应用程序订阅一个或多个Topic,并处理向他们传输的记录流。
- 3. Streams API:流API允许应用程序充当流处理器,从一个或者多个Topic中消费输入流,并将输出流生成为一个或多个输出主题,从而将输入流有效地转换为输出流。
- 4. Connector API:连接器API允许构建和运行可重用的生产者或消费者,这些生产者或消费者将Kafka Topic连接到现有的应用程序或数据系统。例如:连接到关系数据库的连接器可能会捕获对表的每次更改。
四、Kafka架构图

1、结构名词解释
消息由producer产生,消息按照topic归类,并发送到broker中,broker中保存了一个或多个topic的消息,consumer通过订阅一组topic的消息,通过持续的poll操作从broker获取消息,并进行后续的消息处理。
Producer :消息生产者,就是向broker发指定topic消息的客户端。
Consumer :消息消费者,通过订阅一组topic的消息,从broker读取消息的客户端。
Broker :一个kafka集群包含一个或多个服务器,一台kafka服务器就是一个broker,用于保存producer发送的消息。一个broker可以容纳多个topic。
Topic :每条发送到broker的消息都有一个类别,可以理解为一个队列或者数据库的一张表。
Partition:一个topic的消息由多个partition队列存储的,一个partition队列在kafka上称为一个分区。每个partition是一个有序的队列,多个partition间则是无序的。partition中的每条消息都会被分配一个有序的id(offset)。
Offset:偏移量。kafka为每条在分区的消息保存一个偏移量offset,这也是消费者在分区的位置。kafka的存储文件都是按照offset.kafka来命名,位于2049位置的即为2048.kafka的文件。比如一个偏移量是5的消费者,表示已经消费了从0-4偏移量的消息,下一个要消费的消息的偏移量是5。
Consumer Group (CG):若干个Consumer组成的集合。这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个CG只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
假如一个消费者组有两个消费者,订阅了一个具有4个分区的topic的消息,那么这个消费者组的每一个消费者都会消费两个分区的消息。消费者组的成员是动态维护的,如果新增或者减少了消费者组中的消费者,那么每个消费者消费的分区的消息也会动态变化。比如原来一个消费者组有两个消费者,其中一个消费者因为故障而不能继续消费消息了,那么剩下一个消费者将会消费全部4个分区的消息。
2、内部结构
- 消费者和生产者能操作的最小单元是分区,也就是不可能只消费一条数据
- 消费者组是逻辑概念,只是一个标记而已,具体的修改在config的server.properties中的设置int类型的broker_id
- 同一个消费者组里面不能是同时消费者消费消息,只能有一个消费者去消费,第二,同一个消费者组里面是不会重复消费消息的,第三,同一个消费者组的一个消费者不是以一条一条数据为单元的,是以分区为单元,就相当于消费者和分区建立某种socket,进行传输数据,所以,一旦建立这个关系,这个分区的内容只能是由这个消费者消费。
- Zookeeper保存kafka的集群状态信息的,包括每个broker,为什么?,因为zk和broker建立监听,一旦有一个broker宕机了,另一个备份就可以变为领导,第二,zk保存消费者的消费信息,为什么要保存?就是为了消费者下一次再次消费可以得知offset这个偏移量,consumer信息高版本在本地维护
- 为什么说kafka是分布式模型呢?首先,同一个kafka集群有共同拥有一个topic, 而同一个topic又拥有不同的分区,不同的分区可以分布在不同的borker上也就是不同的机子上,所以,分区是分布式的,则数据也是分布式的,kafka就是分布式
- 在不加上leader和fllower的概念的前提下,kafka的同一个topic里的分区号是不同,一定不能重复。
- 除了分区是分布式的,还有消费者也是分布式的,比如,消费者组里的消费者可以在不同的机器上,有什么好处?消费的方式可以是存储可以是计算,如果是放在一台机子上,Io等压力很大,
- kafka上面的所有想到的角色都是分布式的,不管是消费者还是生产者还是分区,他们之间沟通的唯一桥梁就是zookeeper
- 强调:kafka分区内有序,整体不一定有序。
- 消费者组的概念很重要,下图解释和同一组和不同组的使用情景

怎么实现消费者消费不同的数据? 将消费者放在同一组,但是生产环境一般要求消费者消费的数据一样且多个,比如一个写到hdfs,一个放到spark计算,这样就得要求不同的消费者在不同的消费者组里。
简单的说就是队列里面的数据,如果想让不同的消费者读不同的数据,就把他们放在同一个组里,否则放在不同组。
参考:http://www.yunweipai.com/34283.html
https://blog.csdn.net/student__software/article/details/81486431