字符串前加u,b,r,f的含义
1.加u
字符串以 Unicode 格式 进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时出现乱码。
u"我是含有中文字符组成的字符串。"
2.加r
屏蔽转义。如去掉反斜杠的转移机制。
r" ” # 表示一个普通生字符串 ,而不是换行
3.加b
将字符串变成btyes类型
b'这里看上去是字符串,实际上已经变成字节了'
4.加f
模板字符串,类似于ES6模板字符串。(3.6版本加入)
country = "中国"
language = "Python"
str = "这里是%s,语言是%s
"%(country,language)
str1 = "这里是{0},语言是{1}
".format(country,language)
str2 = "这里是{a},语言是{b}
".format(a=country,b=language)
str3 = f"这里是{country},语言是{language}
"
print(str,str1,str2,str3)
基本字符串操作
Pyhton中字符串的格式化输出在前面已经总结了,接下来介绍一些常用的字符串操作
先定义一个字符变量,以下的操作都以此为例:
name=" my name is china " #(首尾有空格)
1.首字母大写(整个字符串的首字母)
print(name.capitalize()) # my name is china
并没有变化!是因为第一个字符是空格!如果把第一个空格去掉,结果为:My name is china
2.将所有字母变大写或变小写
name.lower() # my name is china name.upper() # MY NAME IS CHINA
3.首字母大写(每个单词)
name.title() # My Name Is China
4.大小写互换
name.swapcase() # MY NAME IS CHINA
此方法是:大写变小写,小写变大写
5.统计相同字符的数目
name.count("i") # 统计字符串中 "i" 的个数。
6.Center()方法
name.center(50,"-") print: ---------------- my name is china ----------------
一共50个字符,字符串以外用指定的“-”来填充,并将字符串变量内容居中
7.判断字符串是否以这个字符结尾
name.endswith("ng") # False
判断字符串是否以“ng”结尾
8.在字符串中寻找某个子字符串的位置
例如:寻找字符串中“name”的位置
name.find("name") # 4
9.去掉字符串两端的空格
有时候为了避免不必要的麻烦,会将用户输入的字符串去掉两端的空格
name.strip()
10.去掉字符串左边或右边的空格
name.lstrip() #去掉左边的空格 name.rstrip() #去掉右边的空格
11.字符串的加密
maketrans()方法 和 translate()方法
p=str.maketrans("abcedfghij","9876543210") #编写密码规则
print(name.translate(p)) #按照上述密码转换规则将明文翻译成密文
先上运行结果:
my n9m6 1s 721n9
看懂了吗?就是用“9”来替代“a”,“8”来替代“b”,“7”来替代“c”,……,依次类推
12.将字符串中特定字符替换
将字符串中某些旧字符替换成新字符,并返回新的字符串
name.replace()方法
print(name.replace("m","M",2))
将字符串中前2个“m”替换成“M”
结果为: My naMe is china
第一个值是被替换字符,第二个值是替换字符,第三个值是被替换的个数(可以省略)
13.字符串切片(截取)
不光列表,字符串也可以切片,而且和列表的操作一样
新定义一个字符串

运行结果:
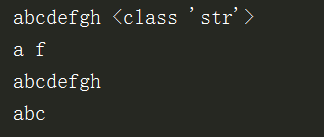
14.获取字符串的长度
len(a)
获取的是字符串的长度(字符数、字节数)。此方法不是字符串的专属,列表、字典等其他数据类型都可以用。列表获取的是元素的个数,字典获取的是key的数量。
15.split()分割函数
split() 通过指定分隔符对字符串进行分割,并返回分割后的字符串列表。如果参数 num 有指定值,则仅分隔 num 个子字符串
split(str,num)
参数:
str:分隔符,默认为所有的空字符,包括空格、换行( )、制表符( )等。
num: 分割次数(可以省略)
str = "Line1-abcdef
Line2-abc
Line4-abcd"
print str.split( )
print str.split(' ', 1 )
#运行结果:
['Line1-abcdef', 'Line2-abc', 'Line4-abcd']
['Line1-abcdef', '
Line2-abc
Line4-abcd']
16.index()
print(str.index("L")),输出第一个L的下标
string模块
string模块提供了几个实用的字符串方法。
- string.ascii_letters 输出所有小写和大写字母
- string.ascii_lowercase 输出所有小写字母
- string.ascii_uppercase 输出所有大写字母
- string.digits 输出所有十进制数字(0~9)
- string.hexdigits 输出所有十六进制数字(0~F)
- string.octdigits 输出所有八进制数字(0~7)
输出:

有什么应用呢?举个例子:每次运行随机生成一个4位的验证码,由数字和字母组成


import random import string checkcode="" for i in range(4): a=random.randint(0,1) if a==0: tmp = str(random.randint(1, 9)) #获取[1,9]之间的随机整数 else: tmp = random.choice(string.ascii_letters. replace("O","").replace("l","")) #获取所有英文字母(str)并随机选择1个 # 去除字符中容易混淆的大写字母O # 去除字母中容易混淆的小写字母l checkcode = checkcode + tmp print("验证码:",checkcode)