并发编程-ThreadLocal&ForkJoinPool(使用以及原理分析)
本章只要聊聊两个东西,这里会给出如何使用他们,并且分析各自的源码以及原理。
【ThreadLocal】:在指定线程中存储数据,数据存储后只有指定线程可以获得
【ForkJoinpool】:实际上他类似于【hadoop】他是将一个大任务分成若干个小任务,然后对每个小任务进行计算,最后汇总结果(其运用【分治法】和【工作窃取】两种思想)
ThreadLocal
【使用】
他是用来解决线程安全问题的一个工具(本质上线程安全问题就是多个线程对同一个共享变量读和写的操作导致的),他就通过【线程隔离】解决这一问题,试想咱们现在有一个变量,每个线程拿到的这个变量都是一样的,各自对这个变量修改对彼此不可见。
public class ThreadLocalExample { static ThreadLocal<Integer> integerThreadLocal = ThreadLocal.withInitial(() -> 0); public static void main(String[] args) { Thread[] threads = new Thread[5]; for (int i = 0; i < 5; i++) { threads[i] = new Thread(() -> {
//获得线程中的数据 int i1 = integerThreadLocal.get().intValue();
//存储进去 integerThreadLocal.set(i1 += 5); System.out.println(integerThreadLocal.get() + "-->" + Thread.currentThread().getName()); }); } for (int i = 0; i < 5; i++) { threads[i].start(); } } }结果(每个线程获取的数据是一样的):我们其实可以用它存储用户信息,当前端传递过来一个token然后我们token进行解析,就可以当前用户信息存储在这个中。
如何应用在现实中(我们知道simpledatefromate不是线程安全的,那我们多个线程用同一个simpledatefromate一定会有问题,我们就可以用他来解决)

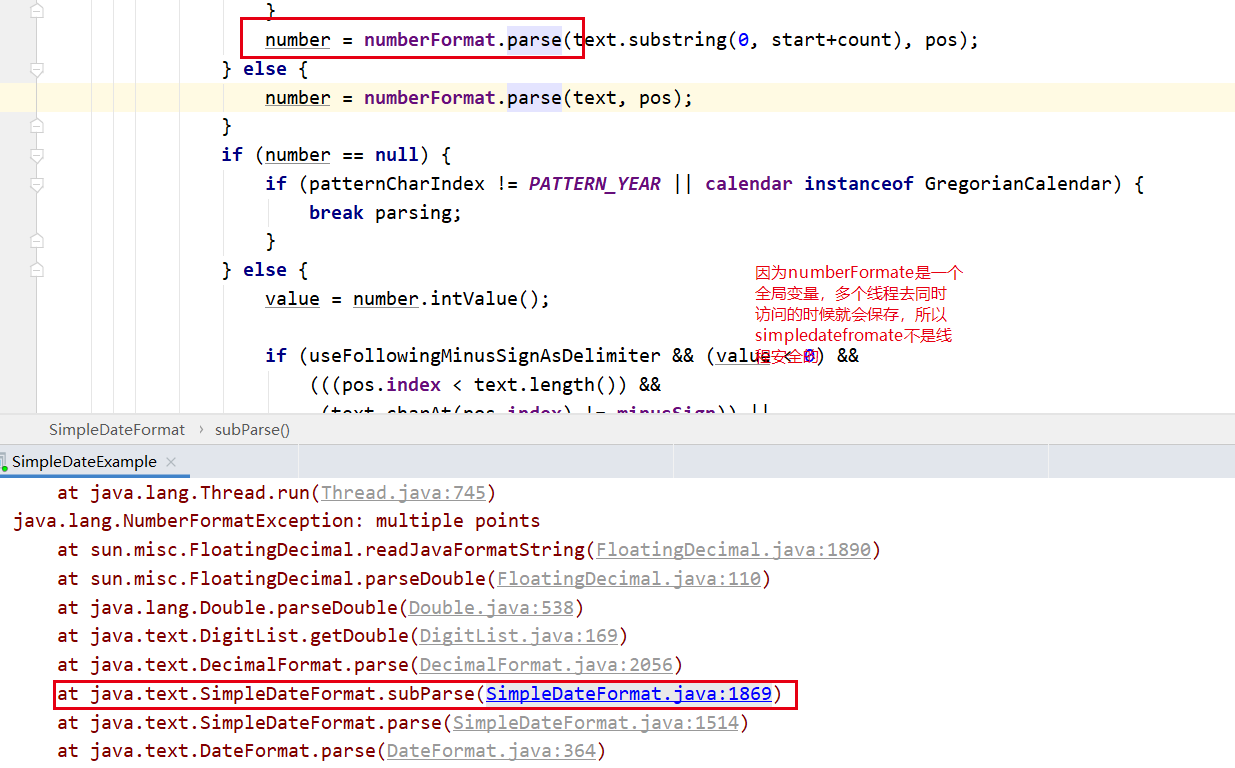
public class SimpleDateExample { static ThreadLocal<SimpleDateFormat> simpleDateFormatThreadLocal = new ThreadLocal<>(); static SimpleDateFormat getDateFormate() { //从当前线程中获取 SimpleDateFormat simpleDateFormat = simpleDateFormatThreadLocal.get(); if (simpleDateFormat == null) { // 在当前线程中设置一个 simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd"); simpleDateFormatThreadLocal.set(simpleDateFormat); } return simpleDateFormat; } private static Date parse(String strDate) throws ParseException { return getDateFormate().parse(strDate); } public static void main(String[] args) { ExecutorService executorService = Executors.newFixedThreadPool(10); for (int i = 0; i < 20; i++) { executorService.execute(() -> { try { System.out.println(parse("1998-05-08")); } catch (ParseException e) { e.printStackTrace(); } }); } } }
【原理】
主要有两个方法
- set:在当前线程中设置一个数,存储在ThreadLocal中,这个数值仅对当前线程可见【这就相当于在当前线程中建立了一个副本】
- get:从当前线程中取出set方法设置的数值
原理猜想:
- 能实现线程隔离,当前保存的线程只会存储在当前范围内
- 一定有一个容器存储这些副本,并且这个容器中的值肯定和每一个线程相关联
- 容器的key肯定和当前线程有关系,因为我们在get数据的时候没有传入任何key
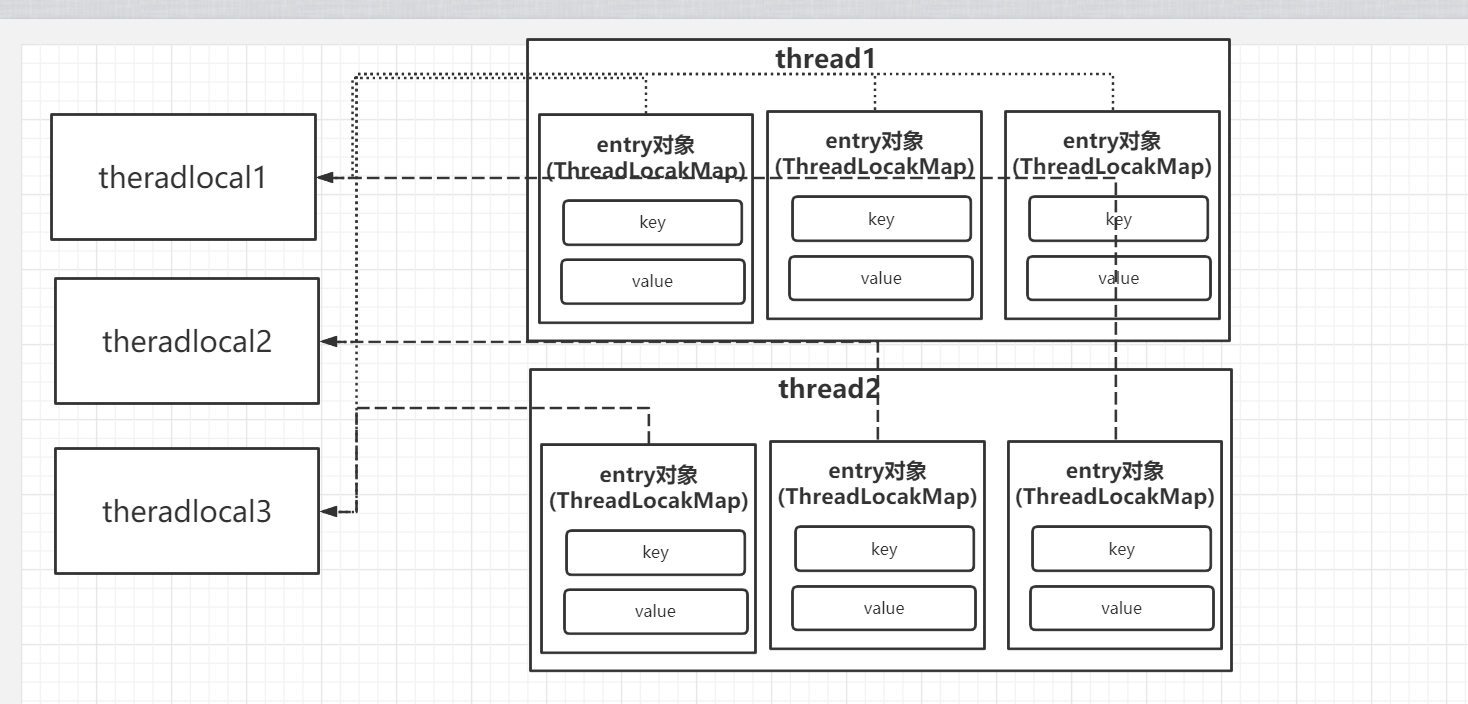
整体剖析(源码解析):其实是在每个线程中都把threadLoca存储在他当前的一个【ThreadLocalMap】中,key指向了ThreadLocalMap而value就是存储的数据
set():
public void set(T value) { Thread t = Thread.currentThread(); //根据当前线程获取ThreadLocalMap ThreadLocalMap map = getMap(t); if (map != null) //不为空则直接存储 map.set(this, value); else //初始化 createMap(t, value); }初始化
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) { //默认长度为10 table = new Entry[INITIAL_CAPACITY]; //计算数组下标 int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); table[i] = new Entry(firstKey, firstValue); size = 1; setThreshold(INITIAL_CAPACITY); }存储数据
private void set(ThreadLocal<?> key, Object value) { Entry[] tab = table; int len = tab.length; //根据key计算数组下标 int i = key.threadLocalHashCode & (len-1); //线性探索(这里是怕通过TheradLocal计算的数组下标是同一个,所以这里是解决hash冲突的) for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { ThreadLocal<?> k = e.get(); //如果这个位置有内容则直接进行替换 if (k == key) { e.value = value; return; } //如果key为空则证明这里存储的数据是一个脏数据,需要被清理(因为这里是弱引用,当threadLocal被Gc了那所引用他的对象也就为空了) if (k == null) {
//我们一会主要聊聊这个方法 replaceStaleEntry(key, value, i); return; } } tab[i] = new Entry(key, value); int sz = ++size; if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash(); }get()
public T get() { Thread t = Thread.currentThread(); // 获取当前线程的ThreadLocalMap ThreadLocalMap map = getMap(t); if (map != null) { //通过当前的ThreadLocal去获取数据 ThreadLocalMap.Entry e = map.getEntry(this); if (e != null) { @SuppressWarnings("unchecked") T result = (T)e.value; return result; } } return setInitialValue(); }private T setInitialValue() { //获取咱们设置的初始数据 T value = initialValue(); Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); return value; }在设置set内容的时候有一段代码比较特殊,我们来分析一下【replaceStaleEntry】:他主要做两件事情
【把当前的value存储在entry中】,【并且清理无效的key】但是里面牵扯到【线性寻址法】可以解决hash冲突,具体是这样的
从通过ThreadLocal生成的下标中向前查找,然后再向后查找。
【脏enrty】:指的是key为null
【可以替换的enrty】:传入的通过当前ThreadLocal计算的hash值和整个entry中的某个key相同,则把两个位置做一个替换
具体情况如下
- 向前查找到了脏的enrty(✔),向后有可以替换的enrty(✔)->这一步是最繁琐的,剩下的就简单啦
- 向前查找直到找到key为null结束然后使用【slotToExpunge】记住脏entry的下标
- 向后查找,假设我们要添加一个value为6的entry,我们换算出来的下标为4,向后查找,我们发现传入的key的hash值和下标是6的hash值是相同的,那我就互换他们的位置(如果不替换他们的位置,我们设置内容的时候就会存在冲突的问题)
- 这个时候从【slotToExpunge】这里还是给后面清理,从我们记住 的脏entry开始给后面遍历entry,把enrty中key为null的value设置为空
- 向前查找到了脏的enrty(✔),向后没有发现可以替换的enrty(✖)
- 这里就直接插入数据,因为没有hash冲突,然后我们向前查找,找到【slotToExpunge】,然后从这里再给遍历把key为null的value设置为空
- 向前查找没有脏的entry(✖),向后发现了可以替换的enrty(✔)
- 那就找到冲突的hash然后替换。
- 向前没有找到脏的enrty(✖),向后没有发现可以替换的enrty(✖)
- 那直接插入即可
- 如果当前下标对应的entry中的key为null,则向前查找是否还存在key为null的entry进行清理
- 通过线性探索解决hash冲突的问题
private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) { Entry[] tab = table; int len = tab.length; Entry e; //这里定义了一个需要开始清理的位置 int slotToExpunge = staleSlot; //这里向前查找 for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len)) //找到前面的key为null,然后记录开始查找位置 if (e.get() == null) slotToExpunge = i; //向下查找 for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get(); //如果找到一个相同的key if (k == key) { //这里就对他们进行替换 e.value = value; tab[i] = tab[staleSlot]; tab[staleSlot] = e; if (slotToExpunge == staleSlot) slotToExpunge = i; //这里清理无效的key cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); return; } if (k == null && slotToExpunge == staleSlot) slotToExpunge = i; } tab[staleSlot].value = null; tab[staleSlot] = new Entry(key, value); if (slotToExpunge != staleSlot) cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); }对无效的key进行清理
//这里就是我们向前查到后找到的key为null的下标 private int expungeStaleEntry(int staleSlot) { Entry[] tab = table; int len = tab.length; tab[staleSlot].value = null; tab[staleSlot] = null; size--; Entry e; int i; //这里循环查找 for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get(); //只要key为null,则设置他的value也为null if (k == null) { e.value = null; tab[i] = null; size--; } else { int h = k.threadLocalHashCode & (len - 1); if (h != i) { tab[i] = null; while (tab[h] != null) h = nextIndex(h, len); tab[h] = e; } } } return i; }关于内存泄漏问题,是会有极端情况下产生,你我们每次用完后就使用remove即可,remove底层也是使用了线性探索对key和value进行移除
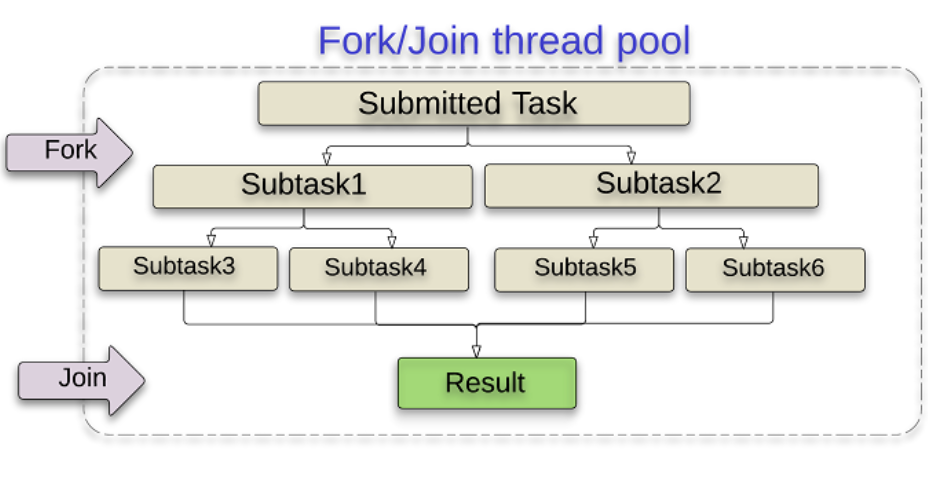
Fork/Join
它可以将一个大的任务拆分成多个子任务进行并行处理,最后将子任务结果合并成最后的计算结果,有点像Hadoop
【使用】
API:
ForkJoinTask:
RecursiveAction:没有返回结果的
RecursiveTask:有返回结果的
CountedCompleter:没有返回值,但是任务触发后会进行回调
fork():让task异步执行
join():让task同步通同步,等待获得返回值
ForkJoinPool:专门用来运行ForkJoinTask的线程池
public class ForkJoinExample { //以200为一个单位进行拆分 private static Integer separateLine = 10; static class CalcJoinTask extends RecursiveTask<Integer> { //子任务开始计算的数值 private Integer startValue; //子任务开始结束计算的数值 private Integer endValue; CalcJoinTask(Integer startValue, Integer endValue) { this.startValue = startValue; this.endValue = endValue; } @Override protected Integer compute() { // 如果当前的数据计算已经小于给定数值则不需要进行拆分,否则会进行不断的拆分 if (endValue - startValue < separateLine) { System.out.println("开始计算startValue:" + startValue + "endValue:" + endValue); return endValue+startValue; } //从开始位置到一半的位置 CalcJoinTask calcJoinTask = new CalcJoinTask(startValue, (startValue + endValue) / 2); calcJoinTask.fork(); //总数一半加一的地方,到最大的数值 CalcJoinTask calcJoinTask1 = new CalcJoinTask((startValue + endValue) / 2 + 1, endValue); calcJoinTask1.fork(); //这里汇总总数 return calcJoinTask.join() + calcJoinTask1.join(); } } public static void main(String[] args) throws ExecutionException, InterruptedException { CalcJoinTask calcJoinTask = new CalcJoinTask(1, 100); ForkJoinPool forkJoinPool = new ForkJoinPool(); ForkJoinTask<Integer> result = forkJoinPool.submit(calcJoinTask); System.out.println("result"+result.get()); } }工作队列
我们看fork方法的底层是一个工作队列【workQueue】,他会把当前的任务放在一个workQueue,他是一个【双端队列】(是一个两端进行添加和操作元素的队列),他它可以实现后进先出(fifo),每个线程中都私有这样一个双端队列,这个队列中存储的就是fork添加进行去的任务,每次执行任务都从这个队列中取,因为是后进先出,所以第一个元素就是最后push进去的元素,执行完成第一个元素,把执行的数据传递给下一个队列中的元素。但是如果一个线程执行完成了他自己的任务,那怎么办,我们不能让他闲着,所有这里使用了一个工作窃取的算法
工作窃取
如果某个线程的【workQueue】执行完成了,那我先不闲着,我从其他的队列中去获取一个任务,从他们的对尾获取,这样就不会冲突,因为其他线程是从队头获取任务执行,这样就提升了性能
如何应用到实际业务中(拆分多个rpc任务去查询商品信息)
在一个电商系统中需要查询:商品信息查询(【RPC->】商品基本信息查询 & 商品评价信息查询) 店铺信息查询 (【RPC->】销售情况,店铺基本信息 )然后我们把每个查询都给他变成一个task
这里是所有的pojo类
 View Code/** * @author : lizi * @date : 2021-06-25 18:01 * 商品信息 **/ public class Shop { String name; public String getName() { return name; } public void setName(String name) { this.name = name; } }
View Code/** * @author : lizi * @date : 2021-06-25 18:01 * 商品信息 **/ public class Shop { String name; public String getName() { return name; } public void setName(String name) { this.name = name; } }这里是我们模拟的所有的rpc服务
View Code/** * @author : lizi * @date : 2021-06-25 18:08 * //商品评价信息查询 **/ @Service public class CommentService extends AbstractLodeDataProcessor { @Override public void load(Context context) { //这里是模拟rpc调用 Comment comment=new Comment(); comment.setContent("Glen"); comment.setName("everything is ok"); context.setComment(comment); } }/** * @author : lizi * @date : 2021-06-25 18:11 * 商品基本信息查询 **/ @Service public class ItemService extends AbstractLodeDataProcessor { @Override public void load(Context context) { Item item=new Item(); item.setNum(100); item.setProductName("battery"); context.setItem(item); } } /** * @author : lizi * @date : 2021-06-25 20:25 * 销售情况 **/ @Service public class SellerService extends AbstractLodeDataProcessor { @Override public void load(Context context) { Seller seller=new Seller(); seller.setTotalNum(1000); seller.setSellerNum(100); context.setSeller(seller); } } /** * @author : lizi * @date : 2021-06-25 20:27 * 店铺基本信息 **/ @Service public class ShopService extends AbstractLodeDataProcessor { @Override public void load(Context context) { Shop shop=new Shop(); shop.setName("Glen’s shop"); context.setShop(shop); } }这里进行所有任务的聚合
View Code/** * @author : lizi * @date : 2021-06-25 20:24 **/ @Service public class ComplexTradeService extends AbstractLodeDataProcessor implements ApplicationContextAware { ApplicationContext applicationContext; List<AbstractLodeDataProcessor> abstractLodeDataProcessors=new ArrayList<>(); @Override public void load(Context context) { abstractLodeDataProcessors.forEach(x->{ x.setContext(this.context); //创建一个fork task x.fork(); }); } @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { this.applicationContext=applicationContext; abstractLodeDataProcessors.add(applicationContext.getBean(SellerService.class)); abstractLodeDataProcessors.add(applicationContext.getBean(ShopService.class)); } @Override public Context getContext() { this.abstractLodeDataProcessors.forEach(ForkJoinTask::join); return super.getContext(); } } /** * @author : lizi * @date : 2021-06-25 20:14 * 对于商品信息的聚合任务 实现ApplicationContextAware去获取上下文 **/ @Service public class ItemTaskForkJoinDataProcessor extends AbstractLodeDataProcessor implements ApplicationContextAware { ApplicationContext applicationContext; List<AbstractLodeDataProcessor> abstractLodeDataProcessors=new ArrayList<>(); // 在这里我们对于每个task进行一个fork @Override public void load(Context context) { abstractLodeDataProcessors.forEach(x->{ x.setContext(this.context); //创建一个fork task x.fork(); }); } @Override public Context getContext() { //这里获取每个任务的等待 this.abstractLodeDataProcessors.forEach(ForkJoinTask::join); return super.getContext(); } @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { this.applicationContext=applicationContext; abstractLodeDataProcessors.add(applicationContext.getBean(CommentService.class)); abstractLodeDataProcessors.add(applicationContext.getBean(ItemService.class)); abstractLodeDataProcessors.add(applicationContext.getBean(ComplexTradeService.class)); } }我们需要有一个上下文去存储获取的信息
View Codepublic class Context { public Comment getComment() { return comment; } public void setComment(Comment comment) { this.comment = comment; } public Item getItem() { return item; } public void setItem(Item item) { this.item = item; } public Seller getSeller() { return seller; } public void setSeller(Seller seller) { this.seller = seller; } public Shop getShop() { return shop; } public void setShop(Shop shop) { this.shop = shop; } Comment comment; Item item; Seller seller; Shop shop; @Override public String toString() { return "Context{" + "comment=" + comment + ", item=" + item + ", seller=" + seller + ", shop=" + shop + '}'; } }定一个一个模板模式的基础类,所有的任务类都需要继承这个类,并且去实现模板方法
/** * @author : lizi * @date : 2021-06-25 18:03 **/ //因为我们不需要返回值所以用 RecursiveAction public abstract class AbstractLodeDataProcessor extends RecursiveAction implements ILodeDataProcessor { public void setContext(Context context) { this.context = context; } public Context getContext() { // 得到一个聚合的结果 this.join(); return context; } protected Context context; @Override protected void compute() { //调用子类的具体实现,【所有实现了AbstractLodeDataProcessor的子类都会实现load方法】 load(context); } }并且我们需要一个接口,这样方便进行管理,并且遵循相关的设计思想
View Codepublic interface ILodeDataProcessor { //加载数据 void load( Context context); }这里这是一个controller进行访问测试
@RestController public class IndexController { @Autowired ItemTaskForkJoinDataProcessor itemTaskForkJoinDataProcessor; @GetMapping("/say") public Context index() { Context context = new Context(); itemTaskForkJoinDataProcessor.setContext(context); ForkJoinPool forkJoinPool = new ForkJoinPool(); forkJoinPool.submit(itemTaskForkJoinDataProcessor); return itemTaskForkJoinDataProcessor.getContext(); } }