本文属性等介绍借鉴了以下博客和文章:
https://blog.csdn.net/supermao1013/article/details/83628344
https://www.w3cschool.cn/solr_doc/solr_doc-jmqv2fzk.html
Schema:模式,是集合/内核中字段的定义,让solr知道集合/内核包含哪些字段、字段的数据类型、字段该索引存储。在solr高版本中,在managed-schema文件中配置。
在这里要强调一下,单机模式的schema文件保存在每个内核的conf文件夹下面。而solrCloud模式是配置在zookeeper里,并没有找到文件
managed-schema详解
文件结构
<?xml version="1.0" encoding="UTF-8" ?> <schema version="1.6"> <field .../> <dynamicField .../> <uniqueKey>id</uniqueKey> <copyField .../> <fieldType ...> <analyzer type="index"> <tokenizer .../> <filter ... /> </analyzer> <analyzer type="query"> <tokenizer.../> <filter ... /> </analyzer> </fieldType> </schema>
field
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="_version_" type="plong" indexed="false" stored="false"/> <field name="_root_" type="string" indexed="true" stored="false" docValues="false" /> <field name="_nest_path_" type="_nest_path_" /> <field name="_text_" type="text_general" indexed="true" stored="false" multiValued="true"/>
必填属性
| 属性 | 描述 | 值 |
|---|---|---|
|
字段名(name) |
字段名,必需。字段名可以由字母、数字、下划线构成,不能以数字开头。以下划线开头和结尾的名字为保留字段名,如 version |
名称 |
|
fieldType属性(type) |
字段的fieldType名,必需。为 FieldType标签中定义的name属性值。 |
fieldType |
可选属性
| 属性 | 描述 | 值 | 隐含默认值 |
|---|---|---|---|
|
默认值(default) |
如果提交的文档中没有该字段的值,则自动会为文档添加这个默认值。相当于传统数据库中的字段默认值。 |
true 或者 false |
false |
|
索引(indexed) |
如果为 true,则可以在查询中使用该字段的值来检索匹配的文档。 |
true 或者 false |
true |
|
存储(stored) |
如果为 true,则字段的实际值可以通过查询来检索。 |
true 或者 false |
true |
|
docValues |
如果为 true,则该字段的值将被放入一个面向列的 DocValues 结构中。 |
true 或者 false |
false |
|
sortMissingFirst sortMissingLast |
排序字段不存在时控制文档的位置。 |
true 或者 false |
false |
|
多值(multiValued) |
如果为 true,则表示单个文档可能包含此字段类型的多个值。 |
true 或者 false |
false |
|
omitNorms |
如果为 true,则省略与该字段关联的规范(这将禁用该字段的长度规范化,并保存一些内存)。对于所有基元 (non-analyzed) 字段类型(如 int、float、data、bool 和 string)的默认值均为true。只有全文字段或字段需要规范。 |
true 或者 false |
* |
|
omitTermFreqAndPositions |
如果为 true,则省略该字段过帐的术语频率、位置和有效载荷。这可以提高不需要这些信息的字段的性能。这也减少了索引所需的存储空间。依赖于使用此选项在字段上发布的位置的查询将悄然无法找到文档。对于不是文本字段的所有字段类型,此属性默认为 true。 |
true 或者 false |
* |
|
omitPositions |
类似于 omitTermFreqAndPositions 但保留了词频信息。 |
true 或者 false |
* |
|
termVectors termPositions termOffsets termPayloads |
这些选项指示 Solr 维护每个文档的全部向量矢量,可选地包括这些向量中每个词条出现的位置,偏移和有效载荷信息。这些可以用来加速突出显示和其他辅助功能,但在索引大小方面会带来相当大的成本。对于 Solr 的典型用途,它们不是必需的。 |
true 或者 false |
false |
|
需要(required) |
指示 Solr 拒绝任何尝试添加一个文件,该文件没有这个字段的值。该属性默认为 false。 |
true 或者 false |
false |
|
useDocValuesAsStored |
如果该字段启用了 docValues,将其设置为 true 将允许 stored=false 在 fl 参数中匹配“*”时将该字段作为存储字段返回(即使有)。 |
true 或者 false |
true |
|
大(large) |
如果实际值<512KB,大字段总是被延迟加载,并且只占用文档高速缓存中的空间。这个选项需要 stored="true" 和multiValued="false"。它的目的是为了可能有非常大的值,以便他们不被缓存在内存中的字段。 |
true 或者 false |
false |
fieldType
作用:定义在索引时该如何分词、索引、存储字段,在查询时该如何对查询串分词
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
name:字段类型名称,用于Field定义中的type属性引用
class:存放该类型的值来进行索引的字段类名(同lucene中Field的子类)。注意,应以 *solr.*为前缀,这样solr就可以很快定位到该到哪个包中去查找类,如 solr.TextField 。如果使用的是第三方包的类,则需要用全限定名。solr.TextField 的全限定名为:org.apache.solr.schema.TextField。
positionIncrementGap:用于多值字段,定义多值间的间隔,来阻止假的短语匹配
autoGeneratePhraseQueries:用于文本字段,如果设为true,solr会自动对该字段的查询生成短语查询,即使搜索文本没带“”
synonymQueryStyle:同义词查询分值计算方式
enableGraphQueries:是否支持图表查询
docValuesFormat:docValues字段的存储格式化器:schema-aware codec,配置在solrconfig.xml中的
postingsFormat:词条格式器:schema-aware codec,配置在solrconfig.xml中的
class
solr字段类型
| 类 | 描述 |
|---|---|
|
BinaryField |
二进制数据。 |
|
BoolField |
包含 true 或 false。第一个字符中的值: |
|
CollationField |
支持排序和范围查询的 Unicode 排序规则。ICUCollationField 是一个更好的选择,如果你可以使用 ICU4J。有关更多信息,请参阅 Unicode 归类部分。 |
|
CurrencyField |
已弃用。改用 CurrencyFieldType。 |
|
CurrencyFieldType |
支持货币和汇率。有关更多信息,请参阅使用货币和汇率部分。 |
|
DateRangeField |
支持索引日期范围,还包括时间点实例(单毫秒(single-millisecond )持续时间)。有关使用此字段类型的更多详细信息,请参阅使用日期部分。请考虑使用这种字段类型,即使它只是用于日期实例,特别是当查询通常在 UTC 年/月/日/小时等边界时。 |
|
DatePointField |
日期字段。代表精确到毫秒的时间点,使用基于“维度点”的数据结构进行编码,可以非常有效地搜索特定值或值的范围。有关支持的语法的更多详细信息,请参阅使用日期部分。对于单值字段,必须使用 docValues = "true" 来启用排序。 |
|
DoublePointField |
双字段(64 位 IEEE 浮点)。该类使用基于 “Dimensional Points” 的数据结构对double 值进行编码,从而可以非常有效地搜索特定的值或值的范围。对于单值字段,必须使用 docValues = "true" 来启用排序。 |
|
ExternalFileField |
从磁盘上的文件中提取值。有关更多信息,请参阅使用外部文件和进程一节。 |
|
EnumField |
已弃用。改用 EnumFieldType。 |
|
EnumFieldType |
允许定义枚举的一组值,这些值可能不易按字母或数字顺序(例如,严重性等级列表)排序。这个字段类型需要一个配置文件,它列出了字段值的正确顺序。有关更多信息,请参阅使用枚举字段一节。 |
|
FloatPointField |
浮点字段(32 位 IEEE 浮点)。该类使用基于“维度点”的数据结构对浮点值进行编码,可以非常有效地搜索特定的值或值的范围。对于单值字段,必须使用 docValues = "true" 来启用排序。 |
|
ICUCollationField |
支持排序和范围查询的 Unicode 排序规则。有关更多信息,请参阅 Unicode 归类部分。 |
|
IntPointField |
整数字段(32位有符号整数)。该类使用基于“Dimensional Points”的数据结构对int 值进行编码,可以非常有效地搜索特定值或值的范围。对于单值字段,必须使用 docValues = "true" 来启用排序。 |
|
LatLonPointSpatialField |
纬度/经度坐标对;可能多值多点。通常用逗号指定为 “lat,lon” 顺序。有关更多信息,请参阅空间搜索部分。 |
|
LatLonType |
已弃用。请考虑使用 LatLonPointSpatialField 来代替。一个单值的纬度/经度坐标对。通常用逗号指定为 “lat,lon” 顺序。有关更多信息,请参阅空间搜索部分。 |
|
LongPointField |
长字段(64 位有符号整数)。该类使用基于 “Dimensional Points” 的数据结构对foo 值进行编码,从而可以非常有效地搜索特定值或值的范围。对于单值字段,必须使用 docValues = "true" 来启用排序。 |
|
PointType |
一个单值的 n 维点。它既用于排序不是经纬度的空间数据,也用于一些更罕见的用例。(注:这与基于 "Point" 的数值字段无关)。请参阅空间搜索以获取更多信息。 |
|
PreAnalyzedField |
提供一种发送到 Solr 序列化标记流的方法,可选地具有独立存储的字段值,并且在没有任何额外的文本处理的情况下存储和索引这些信息。 PreAnalyzedField 的配置和用法在“使用外部文件和进程”一节中有介绍。 |
|
RandomSortField |
不包含值。对此字段类型进行排序的查询将以随机顺序返回结果。使用动态字段来使用此功能。 |
|
SpatialRecursivePrefixTreeFieldType |
(简称 RPT)接受纬度逗号经度字符串或 WKT 格式的其他形状。请参阅空间搜索以获取更多信息。 |
|
StrField |
字符串(UTF-8 编码的字符串或 Unicode)。字符串用于小型字段,不以任何方式标记或分析。他们有一个不到 32K 的硬限制。 |
|
TextField |
文本,通常是多个单词或标记。 |
|
TrieDateField |
已弃用。改用 DatePointField。 |
|
TrieDoubleField |
已弃用。改用 DoublePointField。 |
|
TrieFloatField |
已弃用。改用 FloatPointField。 |
|
TrieIntField |
已弃用。改用 IntPointField。 |
|
TrieLongField |
已弃用。改用 LongPointField。 |
|
TrieField |
已弃用。这个字段用一个 type 参数来定义要使用的 Trie * 字段的特定类;改为使用适当的“Point Field”类型。 |
|
UUIDField |
通用唯一标识符(UUID)。通过 NEW 值, Solr 将创建一个新的 UUID。 注意:NEW 在使用 SolrCloud 时,配置一个默认值为 UUIDField 的实例对于大多数用户是不可取的(因为结果将是每个文档的每个副本将得到一个唯一的 UUID值。建议使用 UUIDUpdateProcessorFactory 在添加文档时生成 UUID 值。 |
analyzer(分析器)
在正常使用情况下,只有类型为 solr.TextField 的字段将指定一个分析器。
第一种方式:配置分析器的最简单的方法是使用单个 <analyzer> 元素,它的类属性是一个完全限定的Java 类名。命名的类必须派生自 org.apache.lucene.analysis.Analyzer。例如:
<fieldType name="nametext" class="solr.TextField"> <analyzer class="org.apache.lucene.analysis.core.WhitespaceAnalyzer"/> </fieldType>
第二种方式:灵活组合标记器(分词器)和过滤器:
<fieldType name="nametext" class="solr.TextField"> <analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StandardFilterFactory"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.StopFilterFactory"/> </analyzer> </fieldType>
tokenizer(标记器/分词器)
tokenizer 负责将字段数据分解为词法单位或标记。
https://www.w3cschool.cn/solr_doc/solr_doc-z4un2g9e.html
这个地址讲解的很完整
filter(过滤器)
过滤器定义应遵循 tokenizer 或其他过滤器定义
https://www.w3cschool.cn/solr_doc/solr_doc-dcwb2g9n.html
dynamicField 动态字段
若定义字段较多,可定义一个规则,通过前缀或后缀通配符*表示
<dynamicField name="*_txt_ja" type="text_ja" indexed="true" stored="true"/>
copyField 复制字段
将 cat 字段复制到一个名为 text 的字段中
<copyField source="cat" dest="text" maxChars="30000" />
将_t为后缀的字段复制到text字段中
<copyField source="*_t" dest="text" maxChars="25000" />
uniqueKey 唯一键
指定用作唯一的字段,一般用作业务主键
schemaAPI
单机模式下的solr部署是可以在内核的conf下找到managed-schema文件的,在里面做了修改后,去管理平台reload就可以生效了。
但是在集群模式下,却怎么都没有找到managed-schema文件,经过查看solr官方文档,发现了可以通过schemaAPI的方式对集群的schema进行修改。
参考地址:https://www.w3cschool.cn/solr_doc/solr_doc-8v5b2g40.html
如:新增一个fieldType,则
linux下执行:
curl -X POST -H 'Content-type:application/json' --data-binary '{
"add-field-type":{
"name":"myNewTextField",
"class":"solr.TextField",
"indexAnalyzer":{
"tokenizer":{
"class":"solr.PathHierarchyTokenizerFactory",
"delimiter":"/" }},
"queryAnalyzer":{
"tokenizer":{
"class":"solr.KeywordTokenizerFactory" }}}
}' http://localhost:8983/solr/gettingstarted/schema
gettingstarted为你的核心名称
也可使用postman等工具用post方式调用接口:
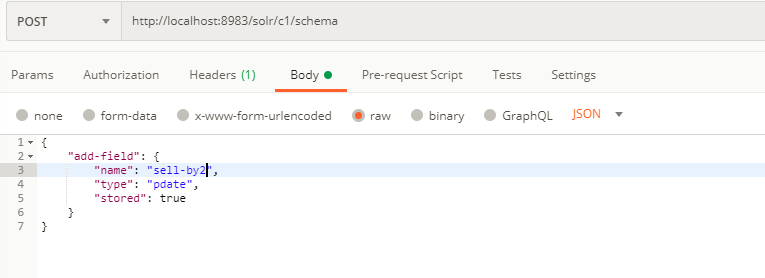
这样就做到了对集群schema的修改,如果还有其他更好的办法,欢迎大佬交流。